

Every new hardware device that offers some kind of benefit compared to legacy devices faces the task of overcoming the immense inertia that is imparted to a platform by the software that runs upon it. While FPGAs have so many benefits compared to general purpose CPUs and even GPUs because of their malleability, the inertia seems even heavier.
Any substantial change requires a big payoff to be implemented because change is inherently risky. It doesn’t help that the method of programming FPGAs efficiently using VHDL and Verilog are so alien to Java and C programmers, and that the tools for porting code from such high level programming languages, often through an OpenCL parallel framework, down to the logic gates on an FPGA are not as efficient as doing the VHDL and Verilog by hand, from scratch, but these tools are getting better. And finally, the application development and runtime stacks common in the enterprise do not know what to do with FPGAs.
This is obviously a problem, and Xilinx wants to help fix it. And so the company is continually increasing the performance of its FPGAs to make them compelling alternatives to CPUs and GPUs, which is just table stakes in the fight for compute dollars, and has also put together what it is calling the Reconfigurable Acceleration Stack to make it easier for those who want FPGA acceleration to get going quicker.
The momentum is building stronger and stronger behind FPGAs, Steve Glaser, senior vice president of corporate strategy and marketing at Xilinx, tells The Next Platform, and the Reconfigurable Acceleration Stack aims to push it harder.
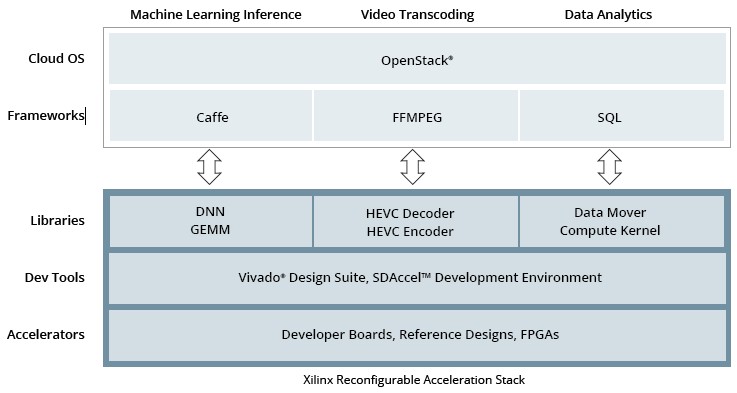
This stack is aimed at hyperscalers (and by extension their HPC and large enterprise peers) that want to get started quickly with FPGA acceleration. The base of the offering is a new developer board that is based on a top-end, datacenter-class UltraScale devices with application specific libraries and framework integration for the five key workloads that Xilinx has identified as the richest ground to plow into to grow its business. These include machine learning inference, SQL query and data analytics, video transcoding, storage compression, and network acceleration. (More on this in a moment.)
Xilinx has had development boards before that were made in conjunction with the FPGA hardware community, but Glaser says that it wanted to get one board out the door and put its own brand on it. And the purpose of the board is not to generate revenues so much as get hyperscale and alike companies started with FPGA acceleration. This developer board has a reference design that hyperscalers can grab and modify as they see fit for their own internal use, such as converting to passive cooling or adding in a higher-end Virtex FPGA.
These developer boards plug into systems, and then clusters of machines are fired up with the OpenStack cloud controller and then a suitable framework for each one of these workloads mentioned above. The Caffe framework for machine learning is the one that Xilinx started with, but TensorFlow will come next and probably Torch and Theano after that. FFMPEG is the framework for video transcoding that snaps into OpenStack and can talk to the Xilinx boards. The opportunity here, says Glaser, is more for the transcoding of live content than for static media stored at sites like Netflix. IBM and Xilinx have created a storage acceleration framework that will come to play here, and network acceleration frameworks based on Open vSwitch will be snapped in. It is not clear what SQL database query acceleration methods will be supported by the Reconfigurable Acceleration Stack, but there will no doubt be several.
By the way, for those who don’t want to build their own iron to learn how to use FPGAs, Xilinx has also partnered with HPC cloud provider Nimbix to offer a cloud-based developer environment that has the same elements as the Reconfigurable Acceleration Stack.
Wrapping around the Reconfigurable Acceleration Stack is OpenStack, which does all of the provisioning of the underlying hardware and hypervisors so virtual machines and containers know how to speak to FPGAs hanging off server nodes. It is available for the latest “Newton” OpenStack release that came out last month through package updates, and with the future “Ocata” OpenStack release due in April 2017, it will be part of the main distro. The FPGA passthrough features that Xilinx has created are modules for the Nova compute module of OpenStack.
None of this is meant to be a turnkey solution for hyperscalers, but Glaser says that it gets them about 80 percent of the way there. It would not be that difficult for OEMs and ODMs to take all of this and commercialize it, and we expect that many will do just that. Moreover, we expect that machines like Microsoft’s Project Olympus systems, which are clearly aiming to have room for both GPU and FPGA acceleration, will inspire a set of machines that deploy CPU, GPU, and FPGA compute on a single node for specific acceleration tasks in the application stack.
There is not, nor will there ever be again, a single kind of compute. Get used to this idea.
FPGAs Rain Down From The Hyperscale Highs
It took the HPC community to kickstart GPU computing and then the hyperscalers to kick it into overdrive thanks to machine learning, as Nvidia’s recent financial results show. The HPC community and certain parts of the financial services and oil and gas industries have been using FPGAs for decades, but again, it looks like the hyperscalers will be pushing the volume economics and making this a real business. It is reasonable to ask why it has taken so long for frameworks and libraries to be accelerated by FPGAs.
“There is a wide range of customers who, in general, like to do their own thing,” explains Andy Walsh, director of strategic market development at Xilinx. “Some of the big hyperscale companies are very quiet, and in some cases we don’t even know what they are doing with our parts. They want to build a complete customized stack with optimized libraries, and those are the pioneers that we have been working with. We have spent two years, along with Altera and Intel, learning about the workloads as they have been evolving, and now we are able to put together a team to build this 80 percent foundation. We are now evolving to another stage, this one of mainstream adoption. I would also point out that some of the big companies that thought they could do it all did make a few mistakes and we supported them and learned what mistakes they were making and with the Reconfigurable Acceleration Stack, we can help other companies avoid those mistakes. Two years ago, we didn’t even know what to build.”
Xilinx is highlighting the use of its own FPGAs at Chinese hyperscaler Baidu, which are deployed for machine learning for speech recognition and autonomous car workloads as well as for accelerating databases. DeePhi is also using Xilinx FPGAs to accelerate machine learning inference, and even though Microsoft’s Catapault system deployed rival Altera’s FPGAs for compute and network acceleration on various workloads, Glaser says that Catapult is a great use case and helps the FPGA cause. Xilinx has partnerships with IBM, through the OpenPower Foundation, and Qualcomm, which is working to launch its 64-bit server parts next year, as well. Xilinx has made significant investments in tools to port C/C++ applications written for the OpenCL framework to port to FPGAs as well as porting common libraries and other software stacks to FPGAs, and even has MicroBlaze and PicoBlaze soft cores available for those who want to emulate a processor on an FPGA and run their C/C++ code right on it. (This is not an efficient way to make use of FPGA gates, but it sure makes it simple and fast to do the port.)
“These are three indications of how FPGAs have gone mainstream in hyperscale, and shows what the opportunity is for Xilinx,” says Glaser. “It speaks to the ability and desire to put more workloads on the FPGA accelerators and get more return on investment and better TCO.”
Because Xilinx – and indeed any accelerator vendor – is asking customers to change from Xeon CPUs that they know how to buy, operate, and program to something different, it is also reasonable to ask how much of a jump customers need to see before they will take the plunge on an alternative technology.
“I have been here for the past year, and I have seen Xilinx FPGAs establish their credentials as an accelerator in the datacenter,” says Glaser. “I feel that when you can get an order of magnitude on performance per watt, that is when people get excited and start sharpening their pencils to take advantage of this opportunity. And this is not all that different from the early days of GPU computing.”
This sales pitch will sound familiar to those of us who watched the rise of GPU computing over the past decade. Here is how Xilinx says an FPGA-accelerated platform rates against a generic Xeon cluster running either machine learning inference or other kinds of data analytics workloads:
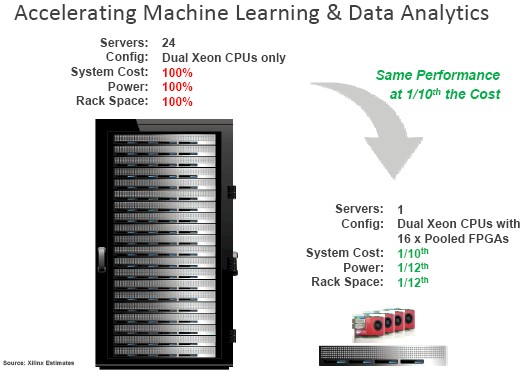
A half rack of servers with 24 two-socket Xeon machines (precise configuration not revealed) can be compressed down to a single two-socket server with sixteen FPGAs to accelerate the work performed. Glaser says this FPGA setup will deliver the same performance for one-tenth the cost and take up one twelfth the space and use one-twelfth the power. (Presumably, all of those FPGA cards are linked to this one server using external enclosures and PCI-Express switches because as far as we know there is no server that can have sixteen FPGAs in them. Four or eight is common.)
Here is a more specific example that Xilinx has cooked up to show the relative speedup of machine learning inference work compared to an Altera Arria 10 FPGA:
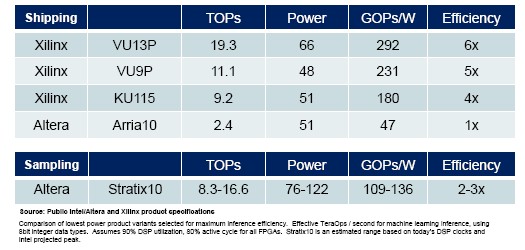
This particular machine learning inference workload assumes the use of 8-bit data types and that the DSPs on the FPGAs that are doing the number crunching are running at 90 percent utilization. The performance of the Stratix 10 FPGA, which is now sampling from Intel using its 14 nanometer process, is estimated based on publicly available data about its architecture.
What is interesting, of course, is how these key workloads mentioned above are accelerated compared to a standard Xeon server that is common in datacenters the world over. Here is the visual on that:
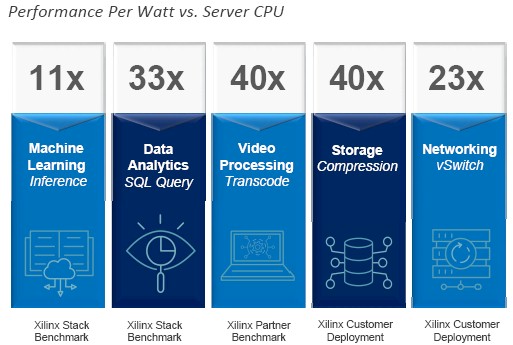
On the machine learning inference workload, which is a system running the AlexNet image recognition application atop the Caffe framework, a single “Broadwell” Xeon E5-2699 v4 part with 22 cores from Intel was benchmarked to be able to classify 1,320 images per second on a system that burned 321 watts, delivering 4.11 images per second per watt. A system configured with a Xilinx Kintex KU115 FPGA could do 2,400 images per second running while burning only 55 watts, yielding an 11X better performance per watt of 43.6 images per second per watt. This comparison has a problem, however, in that the FPGA is not operating in standalone mode, but is inside of a server, offloading applications from the CPU and does not take into account that CPU’s power, thermals, or cost. (Microsoft did the same thing in its analysis of its Catapult system, which annoyed us. But again, those CPUs are often doing other tasks when the work is offloaded to the FPGAs.)
The data analytics benchmark was done on an old six-core Xeon 5600 processor and a Kintex KU115 FPGA equipped with SQL DataMover and compute kernel libraries showed a 33X performance increase, but a modern 22-core Broadwell Xeon would no doubt close that gap quite a bit. We think down to something more like an 8X performance increase, but it is hard to tell.
The video encoding was done on an “Ivy Bridge” Xeon E5-2680 v3 processor, which could encode at 3 frame per second and burned 120 watts to do so, for a FPS/watt rating of 0.025. A Xilinx VU190 FPGA could encode at 60 frames per second and burned 60 watts, which is 40X better performance per watt.
For the storage acceleration workload, a Xilinx customer has implemented Static Huffman erasure coding and is using top-end Xeon E7-8893 v4 processors to do it. This processor consumed 150 watts and delivered the baseline results, and a Xilinx KU060 processor was able to do 7X the erasure coding work in a 25 watt thermal envelope, delivering a 40X bump in performance per watt for this workload.
On network acceleration, the workload was encryption on the Open vSwitch virtual switch, which is a particularly compute-hungry workload. This test was also at a customer and also using the Xeon E7-8893 v4 processors (and very likely the same customer, we think). The Xeon E7 processor could encrypt data in flight at a rate of 7 Gb/sec and burned 150 watts to do it, while a Virtex 7 FPGA could be programmed to run the same workload and did so at a rate of 40 Gb/sec while only consuming 40 watts, for a 23X improvement in performance per watt.
FPGA makers, including main suppliers Altera and Xilinx, are cagey about their prices just like Nvidia is about its Tesla GPU accelerators. But Walsh provided this guidance: “From what we have heard about Xeon CPUs at hyperscale volumes, we believe prices for our high end Virtex UltraScale parts will be comparable to midrange to high end Xeons. The typical high end Virtex price is 1.5X to beyond 2X the price of a Kintex midrange FPGA.”
That helps some. But a list price and a street price would be wonderful things to make actual price/performance comparisons. Make sure you get them.

Reports Of OpenStack’s Death Greatly Exaggerated
OpenStack, the venerable open source cloud controller born in 2010 out projects pulled together by Rackspace Hosting and NASA, continues to push on despite its death being predicted myriad times over the past several years. There are those who say its time has passed, with hyperscalers like Amazon Web Services, …
Xilinx Keeps Pushing Programmable Logic As It Awaits AMD Takeover
The top brass at FPGA maker Xilinx are not hosting calls with Wall Street because of the pending $35 billion acquisition of the company by AMD, so we are left to get our own insight out of the financial report and accompanying statement that Xilinx has released for its latest …
AMD Flexing Spartan FPGA Muscles In Clouds And At Edges
The edge is continuing to become a place where IT infrastructure vendors need to be, and that includes chip makers, all of whom have strategies to push their silicon to where the data is increasingly being generated and needs to be stored, processed, and analyzed. AMD, armed with the technology …
Be the first to comment