
It is hard to tell which part of the HPC market is more competitive: compute, networking, or storage. From where we sit, there is an increasing level of competition on all three fronts and the pressure to perform, both financially and technically, has never been higher. This is great for customers, of course, who are being presented with lots of technology to choose from. But HPC customers tend to pick architectures for several generations, so there is also pressure on them to make the right choices – whatever that means.
In a sense, enterprises and hyperscalers and cloud builders, who just use 10 Gb/sec or 40 Gb/sec or 100 Gb/sec Ethernet throughout their organizations, have it a lot easier. They don’t have to weigh InfiniBand against Omni-Path against Ethernet against Omni-Path against Tofu against NUMALink against a few other proprietary interconnects that scratch out an existence in the upper echelons of computing.
We are grateful for the variety because it is fun, and we expect that in the Cambrian Computing Era that is starting right now, there is a good chance that networking will become as diverse as compute. Particularly with various protocols like Gen Z, CCIX, and OpenCAPI layering into and across systems and even PCI-Express finding its place in racks of servers and storage. Networking, in the broadest sense, is getting more interesting, more tuned, and more sophisticated, and that is because moving data is the biggest problem in system architecture.
It is with all of this in mind that we take a look at the trends in the latest Top 500 supercomputer rankings, which came out this week at the SC16 supercomputing conference.
While everyone obsesses about compute because it represents such a big part of clustered systems (at least when you put the processor and main memory into the same cost bucket), networking adapters, switches, and cables together comprise approximately a quarter of the cost of HPC and hyperscale systems these days and the networking costs are growing faster than any other part of the system. So is energy consumption, which is why you see Google, Microsoft, Facebook, and Amazon Web Services all creating their own switches and intelligent adapter cards as well as driving innovation in single-mode fiber optic cables so they can be used in the datacenter. The HPC centers are under similar pressure but they are not about to create their own networking hardware and software like the hyperscalers. They just don’t have the same scale issues, and HPC centers never will. There is a world of difference between having to link and manage several systems with a few hundred racks each and doing so for a global fleet of millions of servers with tens of thousands of racks across dozens of regions.
In the HPC world, there is always a certain amount of churn as different networking technologies leapfrog each other in terms of pricing and performance, or personal preferences drive purchases. It is common, for instance, to see Intel’s OEM partners pair its Xeon and Xeon Phi processors with its Omni-Path interconnect, which is a derivative of the True Scale InfiniBand networking it acquired from QLogic more than three years ago, mixed with some technology derived from the “Aries” interconnect created by Cray and sold in its XC parallel systems. Cray might have sold off the “Gemini” XT and Aries XC interconnects to Intel around the same time in 2013, but it has exclusive rights to sell this technology, and it has done a good job explaining the benefits of its dragonfly topology and the scalability advantages (thanks in large part to adaptive routing across the network, as we discussed earlier this year with Cray chief technology officer Steve Scott) it provides, and therefore the “Cascades” XC supercomputer line continues its presence on the Top 500 list.
The Top 500 list is not, strictly speaking, just a list ranking traditional simulation and modeling systems used in government, research, academic, and enterprise facilities. A number of cloud builders, telcos, and other large-scale web properties run the Linpack Fortran benchmark tests on their machines to show off the size of their clusters and to help the nationalist causes in their countries to show they have computing might. To one way of thinking, these additions are skewing the results away from the “true HPC” market, but to another way of thinking, these customers who submit results are helping to present a picture of high-end computing, networking, and storage that reflects the reality of clustered systems. We need a Top 5,000 list if we really want to understand what is going on out there, and we need it to be available for all systems, not just those willing to run the Linpack test.
That said, we have to work with the data that we have, not with the data we wish we had.
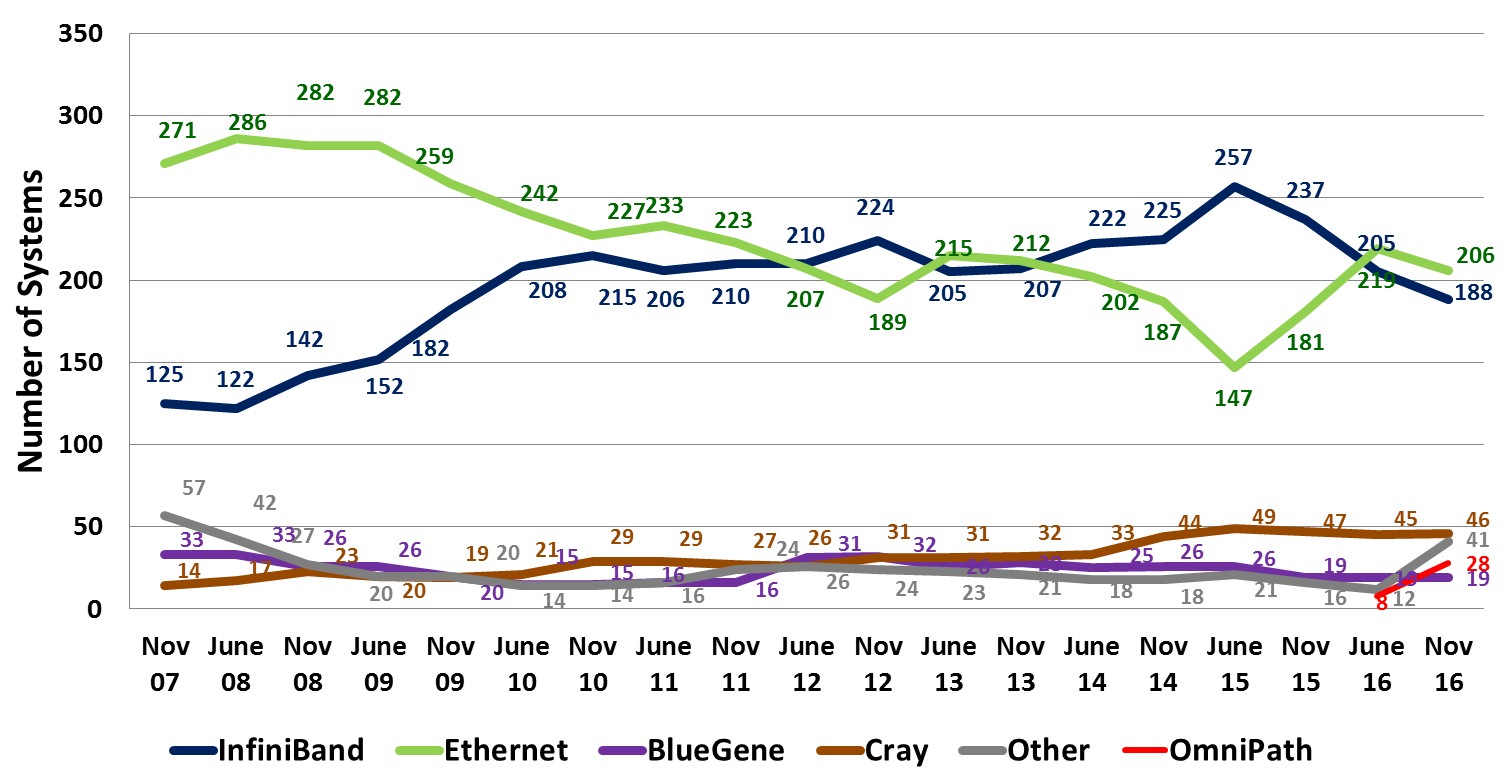
The number of systems on the Top 500 list using Ethernet protocols has been trending down for most of the past decade, as you can see from the chart above, but in recent years, the adoption of 10 Gb/sec and now 100 Gb/sec Ethernet has helped Ethernet rebound a little in terms of system count. InfiniBand was on the rise for most of the past decade, but in the past three years has seen a slight waning as Cray’s Aries got traction on some large systems. Both InfiniBand and Ethernet have taken a slight hit in the past year thanks to the ramping of Intel’s Omni-Path, although you could say that Omni-Path is really just a flavor of InfiniBand and then “InfiniBand” would be holding more or less steady and slightly ahead of Ethernet at all speeds.
The Ethernet protocol is preferred by hyperscalers, telcos, and cloud builders, so when they run the Linpack test and submit results, they drive up the numbers for Ethernet, although if they had not done that, smaller Ethernet systems that did not make the cut for a given list would have risen to the bottom third of the list, as happened in years gone by. Honestly, given the change in customers who submit results, it is amazing that there is any consistency to the list at all, and as we have said before, we think that any government sponsored facility that uses taxpayer dollars to fund parallel machines should have to run Linpack tests and submit them. No ducking the rankings, because this data helps markets figure out what is going on. We would argue that we need more and better tests, and that these should be used to help people make very difficult processor, switch, and storage decisions.
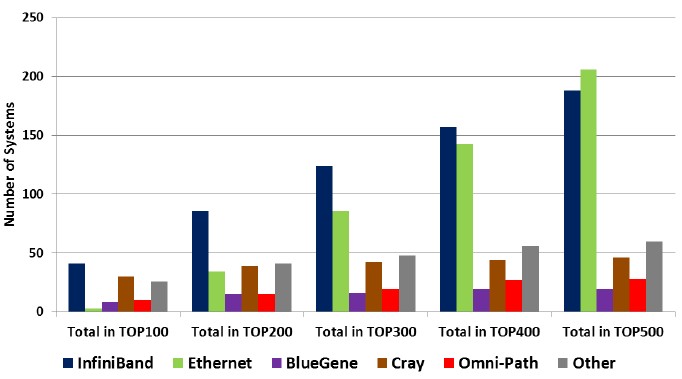
As you can see in the chart above, InfiniBand, Cray Gemini and Aries, and proprietary interconnects dominate the Top 100 portion of the supercomputer rankings, and as you move down the list and add in the successive hundreds of machines until you have the full list, the portion of systems using Ethernet grows. Interestingly, the share of systems across the list based on InfiniBand only goes down a little as more machines are added from the list from biggest to smaller. It is much less likely to see a Cray Gemini or Aries interconnect on smaller machines on the Top 500 list, and ditto for other interconnects of various kinds. IBM’s BlueGene 3D torus interconnect, which has not been updated in years and which is no longer a product the company sells, is hanging on because some very large systems are still doing useful work. But eventually, these BlueGene machines will all be replaced with something else. Intel is going after them with the Xeon Phi/Omni-Path tag team, and IBM is trying to keep them with the combination of Power8 chips, Nvidia Tesla coprocessors, and Mellanox Technologies 100 Gb/sec InfiniBand. Cray has also been successful in dislodging some BlueGene machines with its XC series of systems with the Aries interconnect.
The data in the Top 500 site is skewed for another reason other than the changing mix of organizations that are submitting results. The Sunway TaihuLight system installed at the National Supercomputing Center in Wuxi, China, which has 93 teraflops of computing across its 40,960 nodes, is using 100 Gb/sec InfiniBand networking from Mellanox as the interconnect for the cluster, but the Top 500 list organizers and Sunway are insisting it be called a Sunway interconnect. This is silly, even if Wuxi is adapting the network software stack. It is still InfiniBand hardware, and we would also argue – probably to Intel’s annoyance – that Omni-Path is also InfiniBand. So you have to take the diced and sliced results from the Top 500 with a grain of monosodium glutamate. This doesn’t change the system count by much, but it sure does change the aggregate performance under management by a specific network type by a lot.
Here is a treemap that shows the number of systems with each type of network and the relative percentage of the capacity on the November 2016 Top 500 list by the area of each machine on the list:

See that big yellow-ish rectangle at the top left? By our reckoning, this belongs in the InfiniBand light blue section, and ditto for the TH Express-2 interconnect used in the Tianhe-2 system at the National Super Computer Center in Guangzhou, China, which is the second largest yellow rectangle. We think this is also a derivative of InfiniBand. There could be others. In the treemap above, the light green systems at the lower right are Gigabit Ethernet, and the light magenta ones are using Tofu interconnect. The thin green slice that you can barely see is 100 Gb/sec Ethernet.
It is best to look at the interconnects on the Top 500 list in tabular form, so you can see the number of machines, the peak and sustained performance, and aggregate capacity under network for each networking type. So, take a look:
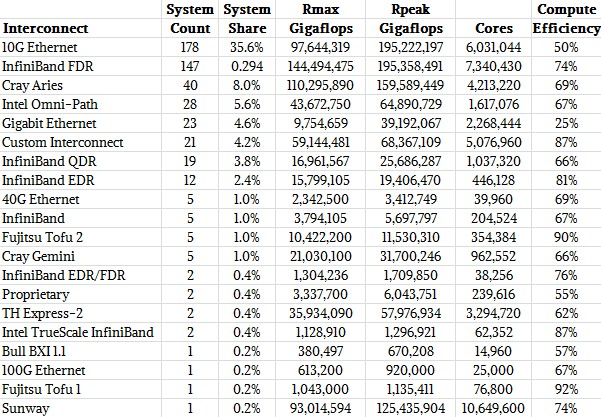
We have consolidated some categories that the Top 500 sublist generator for some reason keeps separate (it counts 56 Gb/sec FDR InfiniBand three different ways, for instance), and we kept the Sunway and TH Express-2 systems separated even though we think these are InfiniBand derivatives as well.
The interesting thing to us is to look at the compute efficiency of the systems, which is a ratio of the sustained Linpack performance divided by the peak theoretical performance of the machine. We know that the network is not the only reason Rmax is not equal to Rpeak), but the trends are still interesting and demonstrate that at least as far as Linpack is concerned, InfiniBand and a number of custom interconnects like Tofu are remarkably efficient and 10 Gb/sec Ethernet, well, not so much.


The Eternal Battle Between InfiniBand And Ethernet In HPC
It is always good to have options when it comes to optimizing systems because not all software behaves the same way and not all institutions have the same budgets to try to run their simulations and models on HPC clusters. For this reason, we have seen a variety of interconnects …
Luminaries Argue For The Interconnect We Could Have Already Had
Here is an old saw that we bring out of the toolbox every now and then, and we use it just enough so it has never really gotten rusty and it can cut through a lot of crap to make a point: The datacenter, and perhaps all clients, would have …

It’s Back To The Future For Omni-Path InfiniBand
People in the modern era sometimes forget that networking predates the rise of Cisco Systems and the commercialization of the Internet. Long before there even were routers and switches as we know them, there were intelligent subsystems and controllers that linked computers to each other, to end users, and to …
Be the first to comment