

With most of the year finished and a new one coming up fast, and a slew of new compute and networking technologies ramping for the past year and more on the horizon for a very exciting 2017, now is the natural time to take stock of what has happened in the HPC business and what is expected to happen in the coming years.
The theme of the SC16 supercomputing conference this year is that HPC matters, and of course, we have all known this since the first such machines were distinct from enterprise-class electronic computers back in the 1960s. HPC not only matters, but the growing consensus at the conference is that HPC will possibly be returning to its roots as a sector for innovation and specialization to solve very specific and computational intensive and complex problems. We could be seeing the waning of the Era of General Purpose HPC even as the simulation, modeling, analytics, and machine learning workloads that comprise modern HPC continue to evolve at a rapid pace.
It takes money to make HPC happen, and HPC also makes money happen, and it is supposed to be a virtuous cycle where more innovation in HPC systems drives more innovation in product design and various kinds of simulation such as weather forecasting or particle physics or cosmology, just to name a few. It is easy to put a value on weather forecasting, much less so on pure science – right up to the moment where we have not invested in the sciences for an extended period of time and innovation that leads to better products and processes slows down.
First and foremost, HPC matters to the suppliers of systems that run these workloads, and it matters to the enterprise, government, and academic organizations that have to come up with the cash to invest in systems and to justify the continued expenses. In this regard, HPC is no different from any other workload, and in many ways, HPC has a more rigorous process for designing, procuring, building, testing, and accepting systems than enterprise computing. (How many enterprise buyers get to qualify a machine running their applications before they pay for it?) Risk is mitigated as much as possible in HPC even as bleeding edge innovation drives the technology – and the business – forward, year after year.
The HPC sector is, however, a very choppy one, with revenues rising and falling with the tides of politics, economics, and technology. Investments in HPC proper are large, but they pale in comparison to the vast datacenters that the hyperscalers of the world – Google, Facebook, Microsoft and Amazon in the United States and Alibaba, Baidu, Tencent, and China Mobile in the Middle Kingdom – build every year. The hyperscalers drive a lot of innovation in their own right, and they have business models and customer-facing applications of various types that actually pay for that innovation. Traditional HPC is about investing up front and hoping for a payoff, either literally from a better product design or manufacturing process or from gaining new insight into science that will, it is hoped, drive further innovation. HPC is about hope and faith in the scientific method to provide a basis for us to solve problems, often really difficult ones that we would rather not face. The hyperscalers want to connect us, amuse us, sell us stuff, and mine our every move on the Internet to provide us more services or sell us more stuff.
It is just not the same thing at all, is it? HPC makes us good citizens, hyperscalers make us good consumers or good friends across large distances, and cloud builders give us good, utility style IT that is easy to consume and manage.
We think you cannot judge HPC by the same metrics as we might judge a hyperscaler or a cloud builder. Being able to tell differences between the technologies they deploy is getting difficult, of course, as there is a lot of borrowing back and forth between the groups – including people, who are being hired out of the national labs to work for hyperscalers and startups. We are not surprised that the major cloud builders like AWS, Microsoft Azure, Google Cloud Platform, and IBM SoftLayer are finally getting around to getting true HPC functionality on their infrastructure, or to see smaller companies like Nimbix, Rescale, and Penguin Computing carve out their niches. There is no easy way to track the revenue streams out on the clouds, but we can try to get a sense of the health of the HPC business from the revenue streams of those who build HPC systems for organizations around the globe.
HPC By The Numbers
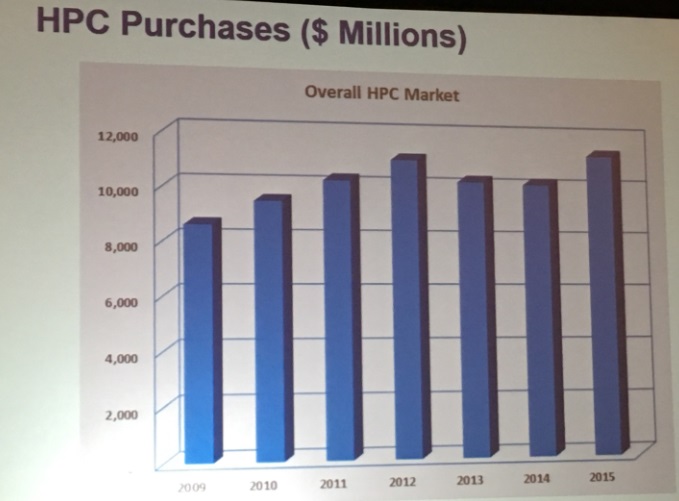
The HPC analysts at IDC host an early morning breakfast at the International Supercomputing Conference each June and at the Supercomputing conference each November, which aims to give us a sense of how spending on HPC systems is trending. Earl Joseph, program vice president for high performance computing at IDC, said that the overall HPC market (including servers, storage, software, and support) is expected to grow by somewhere between 6 percent and 7 percent in 2016, even as the investment across the upper echelon of capability-class supercomputers has slowed in recent years and this year being no exception. In many cases, it is getting harder to separate classical HPC system sales from new-fangled data analytics systems, and for some of the bigger systems being built by the national labs, the systems are designed and acquired specifically to run both kinds of workloads.
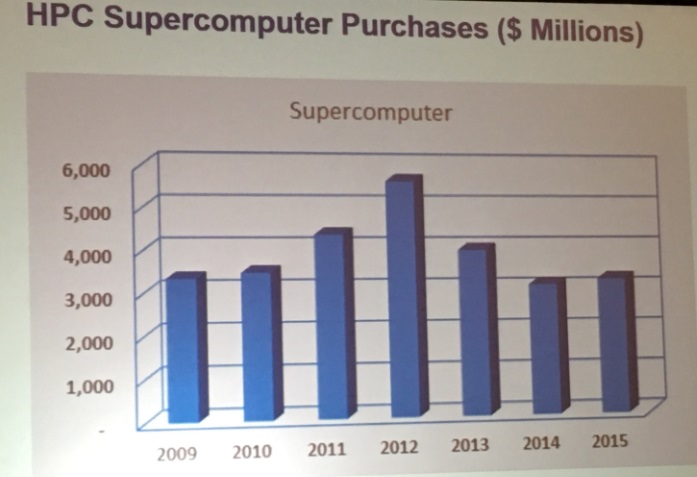
Servers are the key component of HPC systems, and so sales of servers into the HPC space is a good proxy for the overall health of the HPC sector. In the first half of this year, HPC centers of all shapes and sizes bought 5.2 billion of machines, with $1.6 billion of that being allocated for supercomputers, which in the IDC categorization of systems are for machines that cost in excess of $500,000. Divisional supercomputers, which cost between $250,000 and $500,000, drove another $1.2 billion in revenues in the first half of this year, and departmental machines, which cost between $100,000 and $250,000, pushed $1.5 billion. Smaller workgroup HPC servers, which cost under $100,000, accounted for the remaining $900 million in revenues for the first six months of this year, according to IDC data.

Everybody wants to know who is making money in HPC, and Joseph gave a taste of the data that IDC has by revealing the breakdown, by vendor, for supercomputer sales globally. Hewlett Packard Enterprise is the leader, by far, in driving revenues, even before it acquired SGI, a deal that just closed ahead of the supercomputing conference. (We have chatted with HPE and SGI about their future in HPC, and will be telling you all about that shortly.) Take a look at the numbers:
IDC tracks about 45 different HPC system makers, and as a matter of policy it only reveals results of vendors by name with their permission, Luckily all of the big players in HPC play along, so we get a pretty good sense of what is going on. For the big system deals, like the $300 million one that built the Sunway TaihuLight system at the National Supercomputing Center in Wuxi, China, that is at the top of the Top 500 list, IDC is starting to carve these out separately so we can see how these big deals sway the numbers.
“There are some tremendous changes in the market by vendors,” explained Joseph. “HPE clearly has become the market leader since IBM sold off its System x division to Lenovo. Going forward with its acquisition of SGI, this really puts them in a different position from the other vendors. We are also seeing Dell getting some very significant growth right now, and with the combination with EMC, we expect to see Dell to grow quite a bit.”
IBM is still in the game, of course, with its Power Systems machines, but has fallen behind Cray in revenues for the first half. Lenovo, thanks in large part to that IBM System x deal, is the number three revenue generator in the HPC server space.
While the HPC server segment is still growing, the growth rates for 2016 for server sales is a bit lower than for the overall HPC market, as you can see from the data that Joseph presented below:

According to the latest IDC forecast, HPC server revenues are expected to grow about 5 percent this year to $12 billion. According to that forecast, HPC server sales will grow at a declining rate between 2017 and 2020, but it will still grow to $15.1 billion by 2020. This is not for raw server sales that are directly comparable with IDC’s raw data for servers, which is for iron with minimal operating systems. You cannot mix these two sets of data. (Which is unfortunate.)
Joseph also presented a forecast for the broader HPC space, including servers, storage, middleware, applications and break-fix services. (It does not include professional services or system integration service above and beyond that which comes from a system sale.)
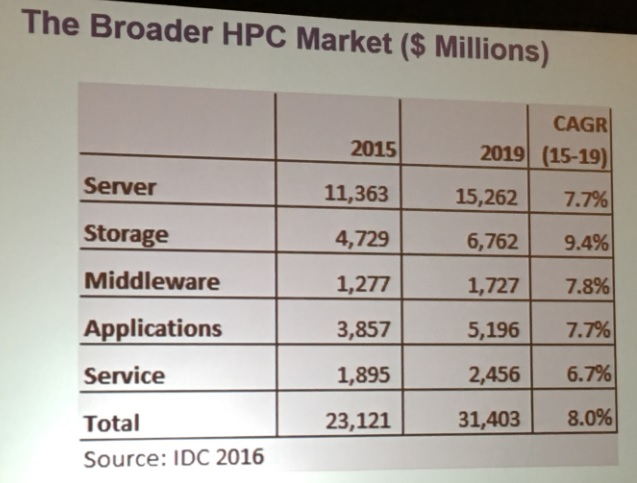
As you can see from the table above, the server portion of the HPC pie, which includes network adapters and switches, dominates the revenue stream at just under half of the $23.1 billion pie in 2015. (We think that networking makes up a pretty significant portion of these storage figures, but IDC doesn’t break it out.) Servers including switching are expected to me nearly half of revenues at the end of the 2019 forecast period in this chart. If you back out switching from the server numbers, storage systems for HPC iron are probably almost as large as the server portion by itself; interestingly, storage is expected to have a compound annual growth rate of 9.4 percent.
What would be interesting to us is to see how much of the servers that are sold each quarter and each year end up in clustered systems that are of HPC scale, whether they are at HPC centers proper or hyperscalers, cloud builders, and large enterprises. We increasingly think that the distinction between these categories is hard to fathom, and maybe somewhat meaningless. Maybe what we need to be counting is the machinery that gets clustered and running the new HPC workloads of machine learning and data analytics at scale as well as traditional HPC workloads of simulation and modeling.
Here is a good for instance. Let’s imagine that we build a cluster of 500 machines running a containerized variant of the OpenStack cloud controller using the Kubernetes container management system atop bare metal. Then we run hypervisors on some of the nodes to provide virtual server instances and then the Kubernetes container management system on top of this OpenStack substrate (well, really next to it) on bare metal compute nodes, and then put the MPI stack and maybe a ANSYS Fluent computational fluid dynamics as well as Hadoop in containers on a percentage each of the nodes. All of these workloads run on the same cluster of 500 machines, concurrently, and change as workloads dictate. So, is this an HPC system? Can companies like IDC find them and count them? How much shadow HPC is out there today, and how much more will there be when everything gets mashed up?
We have some evolving thoughts about this, and we will share as soon.




Be the first to comment