

In the worlds of high performance computing (HPC) and physics, seemingly straightforward challenges are frequently not what they seem at first glance.
For example, doing justice to an outwardly simple physics experiment involving a pendulum and drive motor can involve the need to process billions of data points. Moreover, even when aided by the latest high performance technology, such as the Intel Xeon Phi processor, achieving optimal compute levels requires ingenuity for addressing unexpected coding considerations.
Jeffery Dunham, the William R. Kenan Jr. Professor of Natural Sciences at Middlebury College in Vermont, should know. For about eight years, Professor Dunham has been applying parallel programming techniques to the analysis of data acquired from a nonlinear dynamics experiment that produces about 250 million samples a day. In July of 2016, Professor Dunham purchased the newly launched Ninja Developer Platform for Intel Xeon Phi Processors from Colfax International because he thought it might be the ideal machine for processing data from the experiment. Before he moved his workloads to the Ninja Developer Platform, however, curiosity led Dunham to try something he had never done before. He decided to write a program to test Intel’s peak compute-performance claims so he had a standard with which to compare the performance of his nearly-ideal embarrassingly parallel code. His plan was to use what is sometimes called a “speed of light” program (the name comes from a loose analogy of limiting compute-performance of a CPU to the limiting value of a particle’s speed in the theory of special relativity) for his tests. Initially, Dunham said that achieving peak performance was much more difficult than he expected—then he realized what needed to be done in the coding beyond multi-threading and vectorization.
An interesting challenge for the physics lab
Middlebury College, which was founded in 1800 and is located in Middlebury Vermont, is the number-four ranked U.S liberal arts college (tied with Swarthmore College) on the U.S. News & World Report National Liberal Arts Colleges Rankings.1 The school enrolls roughly 2,500 undergraduates each year, so the physics department is by no means large; it includes six full time faculty and rewards about 15 bachelor of arts degrees in physics per year, on average. But Professor Dunham says that small departments like his are able to tackle increasingly complex problems as more and more powerful, yet cost-effective HPC tools become available.
When Professor Dunham began the nonlinear dynamics experiment in 2008, he was looking for a good academic challenge for him and his students and never expected that it would turn into a long-term research project that required parallel computations. Initially, Dunham set out to improve upon an experiment by Robert DeSerio at the University of Florida that he read about in an article called “Chaotic pendulum: the complete attractor.” DeSerio’s experiment revealed interesting fractal geometric patterns associated with chaotic pendulum movements in a motor-driven system.2 Dunham noted that DeSerio was only able to analyze roughly 10 million data points per day in his experiment, and that he not only wanted to gather at least 25x more data, but also identified several opportunities for improving upon DeSerio’s work.
The apparatus Dunham made for producing data in his lab is simple. A rotating disk with an attached brass knob serves as the pendulum. A string-spring combination connect the pendulum to a drive stepper-motor that has been optimized for uniform rotation. A second fixed spring also connects the pendulum to an optical table top. The motor rotates about once per second and the pendulum responds to the motor (see figure 1).
“The operating physical law is merely Newton’s second law of motion,” Dunham said. “What’s interesting is that even though the motor is always rotating at the same uniform speed, the pendulum disk may respond in unison with the motor, or may repeat every two or three motor rotations, or the response may appear completely random and unrelated to the uniform rotation of the drive motor. In the latter case, the disk is exhibiting what is known as chaos. But when you analyze the data from specific time periods using a Poincaré Plot, it turns out the data is anything but random. Instead you get these intricately structured and beautiful fractals.” According to Dunham, proving that there is more than meets the eye to the seemingly chaotic pendulum behavior is not easy, since there is so much data and the output is discrete.
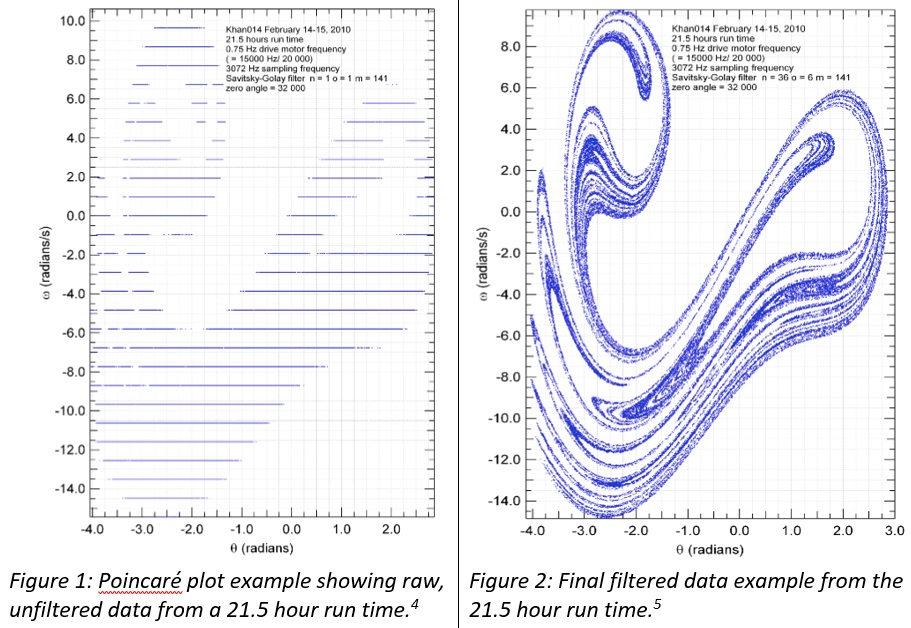
The instruments in Dunham’s nonlinear dynamics experiment record angular positions of the pendulum about 3,000 times per second and about 250 million times per day. The data sets are not only large, but the data comes out discrete and “terribly noisy,” so deriving angular position, velocity and acceleration isn’t possible without the Savitsky-Golay filtering algorithm. “That’s what needs to be written as parallel code because not only do we need to analyze a quarter of a billion items we also need to perform something like a minimum of 1,200 operations on each of them, so we are quickly up to a trillion or more computations per day,” said Dunham. Previously, the lab had excellent success with GPU devices, but Dunham was interested in doing the filtering calculations entirely on a CPU for the sake of simplicity. He thought it would be easier to maintain a single C/C++ filter code that could run on a Xeon or Xeon Phi CPU machine, without a GPU present and without writing special code in CUDA. Dunham’s curiosity about the possibility of switching to a CPU-based system eventually led him to testing whether or not the Intel Xeon Phi Processor in the Ninja Developer Platform could deliver on the performance numbers claimed by Intel.
An unexpected challenge
Dunham said that most of what he knows about parallel programming techniques he learned in the last eight years. “I had to start with what I learned in college 40 years ago and bring it up to date,” said Dunham. “So when you talk about code modernization, believe me I’ve gone through a lot of modernizing in recent years…I didn’t know any C or C++ in 2008 and now I program with OpenMP, I’ve picked up Linux and know how to use things like Intel Intrinsics for speeding up speed of light code.” Dunham even took the Colfax course on optimizing code for the Intel Xeon Phi processor twice, so when he received his Ninja Developer Platform he was ready to test it out with a diagnostic program. He said the reason he wanted to put Intel’s performance claims to task was simply to understand whether or not he should be satisfied with his new machine. He likens it to testing the marketing claims on a high-end sports car. “If your sports car is hitting a max speed of 70 MPH and the sales literature said it could hit 180 that’s a problem,” explained Dunham. “I wanted to understand what kind of performance I should expect from my nearly ideal embarrassingly parallel code relative to the ideal.”
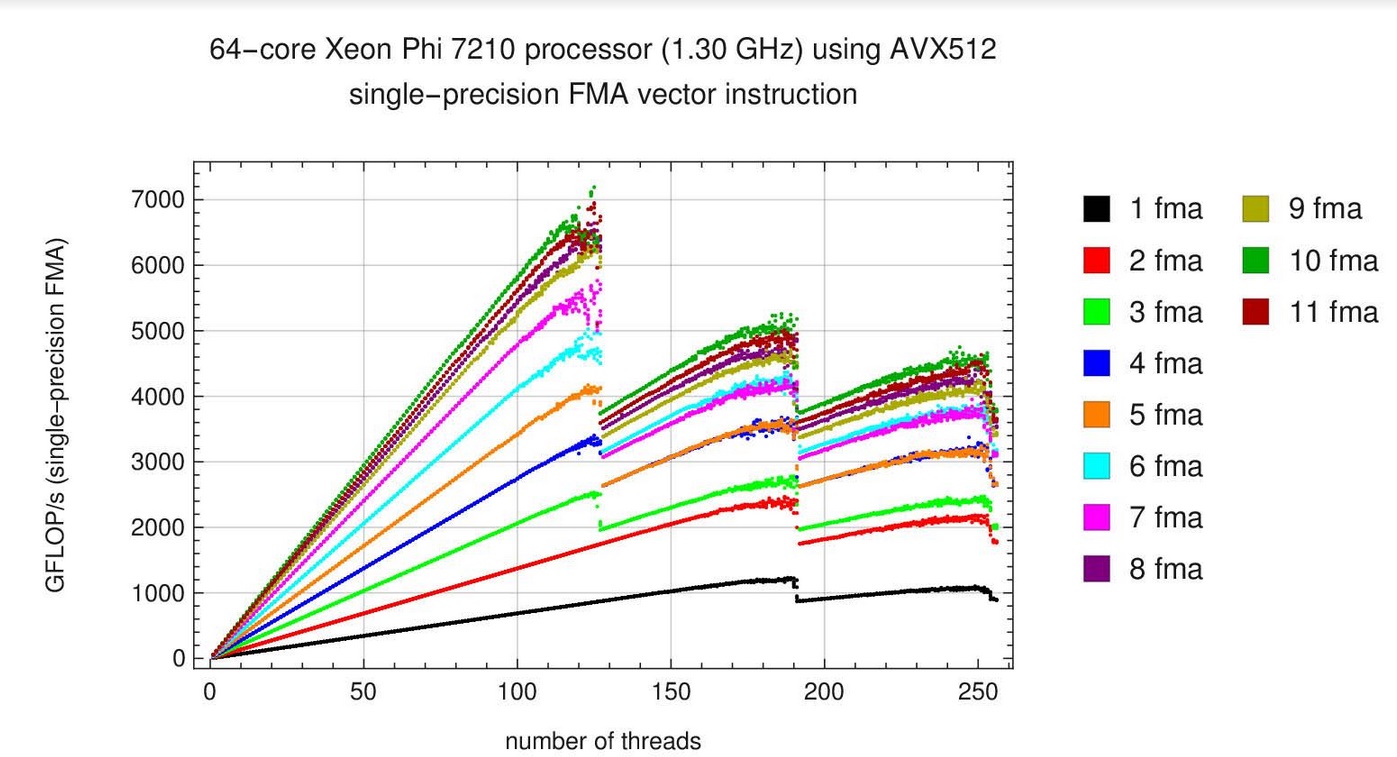
Although Dunham was able to hit Intel’s performance claims, it took him the better part of a week because he ran into some unexpected snags. “Most people know that a big part of the performance gains from the Xeon Phi processor come from the 512-bit register width and its either 16 single-precision or eight double precision numbers. The Colfax course also clearly covered why you have to use vectorization to get optimal performance,” explained Dunham. “I thought I could just write a C/C++ program with obviously vectorizable code that used OpenMP for threading, and I would have no trouble getting 256 hyperthreads to exercise 64 cores in the Xeon Phi processor. Most of that went easily, but for single precision I was stuck at 1 or maybe 2 Tflops per second for a week or two, which was disappointing.”
Achieving peak performance
Dunham said that that he was starting to wonder if he was doing something wrong in his testing or if the automatic vectorizing capabilities in the compiler were working correctly. “As I understand it, chip makers set performance claims based on an instruction called fused multiply-add (FMA). So in one instruction and compute cycle, you multiply two numbers and add that result to a third number. The problem is that that’s what you want, but I could not get the Intel compiler to turn that into quick code. I tried many different ways to have it recognize that the inner loop that I wanted was nothing more than one large FMA-type instruction.” After some trial and error, Dunham decided to go down a level with his coding.
“I’d seen an article about the importance of keeping each vector processing unit in each core busy to achieving optimal performance and I realized that’s what may be needed on my new machine. So I decided to use intrinsics for the inner part of my code. It’s not a very long section of code, but it can exploit up to 32 of the 512-bit-wide registers with the FMA instruction from the AVX-512 instruction set. Placing so many FMA instructions in a single loop is a form of ‘loop unrolling’ that ensures that both vector processing units (VPUs) in each of the 64 Xeon Phi cores always has work to do. Within 10 minutes I could see I was on the right track.” Dunham also verified that in assembly language, when the complier takes his code and turns it into what is really going to be raw machine code, it is incredibly efficient. He noted that he usually uses a -03 complier setting for general vectorization, but that the speed of light code achieves excellent vectorization by hard-coding the vectorization with intrinsics. “It does exactly what I want and just raw computes, with no extraneous memory accesses or use of cache,” explained Dunham. In the end, Dunham said he was able to surpass the performance claims made by Intel (6 TFLOP/s for single precision and 3 TFLOP/s for double precision) by about 5 – 10%.
In the nonlinear dynamics experiment that Dunham copied, the original goal was to collect and analyze 25x more data than DeSerio, and he said he’s already gone well past that milestone with absolutely beautiful results. He explained that he’s now approaching the possibility of gathering 250x more data points per day and it looks even better still. “I’m not getting greedy here. Besides figuring out the type of criteria you use to show you’ve analyzed the data optimally or correctly without distortion from filters, a big goal of mine is to figure out what it takes to analyze that much data on a one-computer workstation,” added Dunham. “That means that even though I’m part of a small physics department, access to a computer like the Ninja Developer Platform for Intel Xeon Phi Processors is very important to my ongoing work.”
Sources:
1 National Liberal Arts Colleges Rankings, U.S. News & World Report, 2016.
2 DeSerio, Robert. March 2003. Chaotic pendulum: the complete attractor. Am. J. Phys., Vol. 71, 3, 4, 5 Khan, Shujaat. “Modeling Chaos and Periodicity in a Driven Torsional Pendulum”, B.A. Thesis, Middlebury College, 2010.


DUG Sets Foundation For Exascale HPC Utility With Xeon Phi
While exascale systems, even at the single precision computational capability commonly used in the oil and gas industry, will cost on the order of $250 million, that cost pales in comparison to the capital outlay of drilling exploratory deep water wells, which can cost $100 million a pop. The trick …

The End Of Xeon Phi – It’s Xeon And Maybe GPUs From Here
To a certain extent, the “Knights” family of parallel processors, sold under the brand name Xeon Phi, by Intel were exactly what they were supposed to be: A non-mainstream product that tried out a different architecture than its mainstream Xeon family of server processors and that was aimed at the …

Argonne Hints at Future Architecture of Aurora Exascale System
There are two supercomputers named “Aurora” that are affiliated with Argonne National Laboratory – the one that was supposed to be built this year and the one that for a short time last year was known as “A21,” that will be built in 2021, and that will be the first …
Well done. Not very surprised that he managed to get more performance by using the AVX-intriinsics directly. C++ compilers have been always rather suboptimal when it comes to autovectorization. GNU CC has always been outrageously bad Intel CC is a lot better but also not perfect.
Anyway since AVX-512 is also part of Skylake Xeon’s he can even move that code to a non Xeon-Phi specific cluster if he wants.
In the end, as always in HPC environment, you need hand-tunning to squeeze the maximum FLOPS from your iron. This what HPC is. You buy a new machine, and then you spend time and time optimizing the software for the architecture until the next big machine is bought. Compilers, programming models help in the process but fine-tunning (or hand-tunning) is required at some point.
I’m missing a comparison with the GPU(s) that it replaced. So what is the evaluation of this hardware experiment? Is the Xeon Phi better or not?
Well, P100 have double the transistor count at simmilar frequency thanks to more advanced manufacturing process so it has double performance too.
So there is reason why they did not compare them.
The only rough comparison I can make, with the hardware available to me, is the 64-core Xeon Phi compared to a single old NVIDIA Tesla K20c. The K20c is capable of about 4 TFLOP/s single-precision and 1.5 TFLOP/s double-precision for a “more-or-less” comparable “speed of light” no-memory-access/no-cache-access code. So the Xeon Phi is better in the particular case of this code.
Of course, the K20c is not the most modern GPU available. For single precision only, the 11 TFLOP/s “raw compute” performance of the NVIDIA Titan X (I don’t have one available to me) would be superior to the Xeon Phi. I have been waiting for the release of a Pascal-generation NVIDIA GPU, with strong single- AND double-precision performance, in order to do a “head-to-head” comparison between CPU and GPU solutions for my Savitsky-Golay filter work.
Jeffrey,
Looking at 2nd chart seems that the processor cannot handle the load if the load pass 128 threads, i can see a huge hit in terms of TFOPS at 128 threads. So Intel engineers are using HT techniques on phi’s internal combustion engine.
This is due to overhead of managing more threads. You’ve got ~64 cores (depends on exact model) and with two thread per core you can keep it busy with pipelining. But going beyond that leads to degradation because of the cost of scheduling, swapping, less efficient pre-fetching and many other factors. You can play with various scheduling options, and OpenMP may not be the best approach to optimizing.
Also, the cliffs you are seeing have to do with problems of load balancing when the number of threads is not a multiple of 64.
Wait for the POWER9 + NVIDIA GPUS via NVLink next year. That is going to be a game-changer. Actually, the latest POWER8 with NVLINK + GPUs are doing an amazing job. Maybe, don’t wait… just buy a machine with really integrated accelerators. That’s the bottleneck in HPC. Just testing raw core performance is not going to make it … do this guy know about the memory wall? the ILP wall? the power wall? or the reliability wall? These are the trade-offs to do when implementing a big HPC machine.
Absolute performance is not the thing to focus on. Performance per dollar is more important if you are doing dumb parallelism, but you must also take into account the cost of the entire system. Another consideration is the performance divided by a more general cost measure that includes the amount of human effort necessary to obtain this performance. In particular, this is part of the allure of Knight’s Landing, etc. But it is a bit of an illusion, as this article makes clear, because autovectorization is generally quite insufficient, and at a certain point CUDA starts looking attractive.