

Over the last couple of years, we have been watching how burst buffers might be deployed at some of the world’s largest supercomputer sites. For some background on how these SSD devices boost throughput on large machines and aid in both checkpoint and application acceleration, you can read here, but the real question is how these might penetrate the market outside of the leading supercomputing sites.
There is clear need for burst buffer technology in other areas where users are matching a parallel file system with SSDs. While that is still an improvement over the disk days, a lot of the random I/O and other benefits of using flash are lost without a smarter software layer to manage I/O. Accordingly, a number of storage vendors have started at the top HPC centers and are pushing their message about burst buffers down to the smaller HPC sites, according to James Coomer, senior technical advisor for burst buffer and storage maker, DataDirect Network’s (DDN) European division.
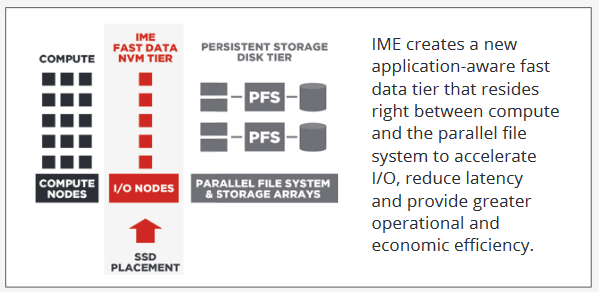 The European sites Coomer frequents are showing a greater interest in more varied aspects of I/O, he says. “They might have algorithms that do different things and do not behave well, or a mix of algorithms where only some do. They might be doing some big data, complex database, or transactional workloads that don’t work well on parallel file systems. These are changes that are happening, which is why we have had to work on the parallel file systems themselves to make them more IOPs and metadata friendly. All of this feeds into the work we’ve done with IME.”
The European sites Coomer frequents are showing a greater interest in more varied aspects of I/O, he says. “They might have algorithms that do different things and do not behave well, or a mix of algorithms where only some do. They might be doing some big data, complex database, or transactional workloads that don’t work well on parallel file systems. These are changes that are happening, which is why we have had to work on the parallel file systems themselves to make them more IOPs and metadata friendly. All of this feeds into the work we’ve done with IME.”
IME is DDN’s burst buffer, which just entered general availability. So far, they have five mid-sized sites that have deployed the flash racks with the burst buffer software. “We suspect that many large datacenters, at least in Europe, will give us a chance to put in a burst buffer and there will be some pickup in the mid-range as well, especially by the second and third quarters of 2017. It makes sense because with the same budget, it’s possible to double throughput, and while not capacity, this is not the emphasis, especially for a lot of the codes we see,” Coomer tells The Next Platform.
“In the near term, the most interest in burst buffers is coming from those who have large, high-scaling codes. Over time, influenced by the decreasing cost of flash and more customers putting burst buffers into practice, we will see it scaling down to the midrange.”
DDN is not the only storage vendor setting sights on the potential of burst buffers in both HPC and large-scale enterprise. Cray has a burst buffer, called DataWarp, which is an add-on to its Sonexion storage line and other more enterprise-oriented vendors, including EMC/NetApp, have their own burst buffer offerings. Cray was the first to put burst buffers to test at massive scale with its work on the Cori supercomputer, which is detailed here, including information about how teams at NERSC will put DataWarp to use—not just for for checkpoint/restart, but to bolster application performance for data-intensive workloads and to gear up for a much larger incarnation of that technology via the Trinity supercomputer. An even larger-scale test of burst buffer technology ala DataWarp will be found on the Aurora supercomputer, coming to Argonne National Lab in 2018 (with the smaller Theta system this year also sporting the technology), and will also be found on the Summit supercomputer coming to Oak Ridge National Lab, although that will not use the Cray technology. In short, all of the major pre-exascale systems will have a burst buffer component—a fact that DDN and others hope will showcase their potential for smaller HPC and big enterprise sites.
While the initial use case for burst buffers was for checkpointing on large systems, application acceleration is the real draw, especially as the handful of vendors working on this technology have shown clear benchmarks and outlined how they can perform for a range of scientific codes.

“For some, checkpointing is interesting, but the real push is from those with codes similar to what we see in weather, as an example. Here, all the data goes into the burst buffer, used during the 24-hour production run, then is started all over again, which allows all workflows and I/O to be done in the burst buffer.” There is limited capacity in such an approach (10-20% of the file system) but users are finding they can put all their data in the burst buffer and refresh it the next day. Other use cases include awkward workloads that don’t work well on parallel file systems because they require many random reads and writes (seismic analysis is a good example). “The burst buffer can take the individual I/O from the application and place it directly on the buffer without a lot of the background activity file systems have to do to associate that fragment with a file. That gives a big jump in the random IOPs behavior—10X or so.”

One of the reasons burst buffers have generated so much buzz in HPC is because for far fewer racks to manage, power, and cool, it is possible to get a massive increase in throughput. While it is possible to buy SSDs and hook them into the file system, the burst buffer, which is a mechanism to provide a transparent pool of flash, allows for far greater random I/O in those SSDs versus simply working through the file system. “If you want a terabyte per second from a file system, that will be many racks, as many as 30. However, with two racks of IME you are getting ten times the performance at one tenth of the cost,” Commer says.

Be the first to comment