

Systems built from commodity hardware such as servers, desktops and laptops often contain so-called general-purpose processors (CPUs)—processors that specialize in doing many different things reasonably well. This is driven by the fact that users often perform various types of computations; the processor is expected to run an Operating System, browse the internet and even run video games.
Because general-purpose processors target such a broad set of applications, they require having hardware that supports all such application areas. Since hardware occupies silicon area, there is a limit to how many of these processor “cores” that can be placed—typically between 4 and 12 cores are placed in a single processor.
If the user develops an application that contains a lot of parallelism, then that application is still performance-bound by the number of processor cores in the system. Even if an application can utilize 100s of processors, in practice, the application will only see no more than 12 cores.
A new trend is that general-purpose processors can utilize data parallelism with vector instructions, the latest version of intel AVX can process operations on 512 bits in parallel, and the use of GPUs for data-parallel programs. This, however, introduces a second level of parallelism in addition to the cores which may be difficult to utilize in many applications.
A team from Sweden’s Royal Institute of Technology (KTH) sought to overcome these limitations of general-purpose processors and data-parallel vector units/GPUs, using Field-Programmable Gate-Arrays (FPGAs). FPGAs are devices that contains logic that is reprogrammable, which means it is possible to create a system inside the FPGA that is tailored to the application; in other words, there is no support needed to run an OS – it only requires the functionality to run a specific application as fast as possible.
To better understand how the Swedish team was able to create a high-level synthesis flow that can automatically generate parallel hardware from unmodified OpenMP programs, we had a chat with the authors of the full paper, Artur Podobas and Mats Brorsson.
Where is OpenMP lacking and how are FPGAs central to making up for the lack of parallelism you point out?
KTH Team: By understanding the needs of the application we can create a system containing a large amount of very small “cores” on our FPGA and be capable of executing many more things in parallel than a general purpose processor ever could; even if the clock-frequency is lower on the FPGA compared to the CPU, the performance benefits of using more parallelism is often worthwhile.
While OpenMP as of version 4.0 contains support for accelerators (through the #pragma omp target directive), so far, the supported accelerators in compilers have been limited to either GPGPUs or Intel Xeon PHIs. Our belief is that OpenMP can be used to drive parallel hardware generation. Most of the existing OpenMP infrastructure is general enough to allow this.
There are a few things that OpenMP could have to better support High-Level Synthesis. Among these are ways for the user to specify other – non-IEEE compliant – floating point representations.
How exactly are you generating parallel hardware from OpenMP programs?
KTH Team: We created a prototype tool-chain that automatically transforms OpenMP applications into specialized parallel hardware.
The hardware that we automatically generate consists of a master soft-core processor and a number of slaves called “OpenMP accelerators”. The master processor is thus general-purpose and is responsible for exposing parallelism and schedule them onto the OpenMP-accelerators, where they are executed.
Each OpenMP accelerator contains a number of what we call “hyper-tasks”. A hyper-task is a processing element that specializes in performing a certain computation. In fact, the hyper-task is created such that it is only capable of executing a certain computation. Unlike general purpose processors, the hyper-task will only contain logic that is crucial for the computation – it will be void of functionality such as TLBs, large physical registers or out-of-order logic. Instead, we decide at compile time how many registers a hyper-task will have and statically schedule the instructions onto a finite state machine. The real-world analogy here would that if you have a stop in your sewer pipes you would call a plumber and not a baker – the plumber is specialized at fixing the sewer pipes and do so most effectively.
Each OpenMP accelerator contains many such hyper-tasks, which can share certain hardware units between them. The ability to share resource is crucial as many resources are very area-expensive to implement on the FPGA. For example, a floating pointer adder is a costly resource that – if sparsely in the application – should be shared across as many hyper-tasks as possible. The real-world analogy would be that most people own their own mug at work while sharing the coffee machine.
Most parameters such as the number of hyper-tasks per accelerator, the number of accelerators and the internal mapping of instructions to hardware is solved using constraint programming approach, which means that we fully model the problem and time alone dictates how good the solution will be – our methodology generates better hardware with future systems.
Can you provide some detail about the following figure? – On left is the overall compilation flow; on right is the proposed OpenMP accelerator. This shows the steps involved in transforming an OpenMP-extended C source code into a specialized SOC along with an abstract view of one OpenMP accelerator with two tasks—regional and private. Describe how this works.
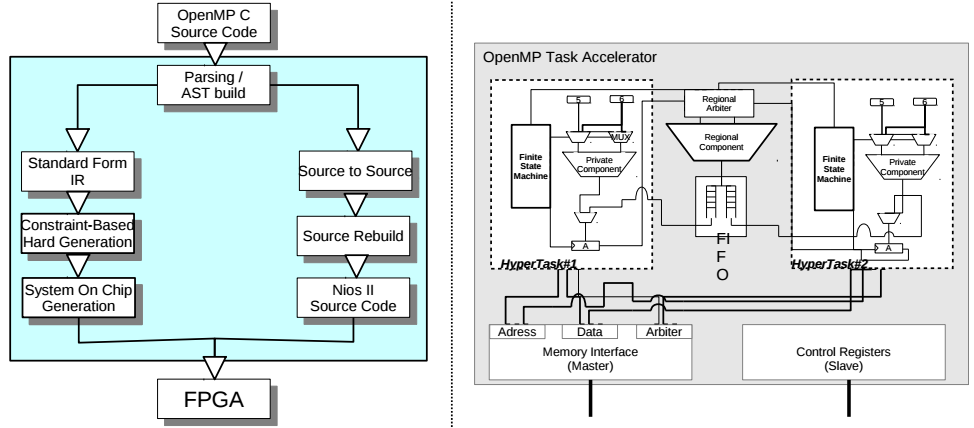
KTH Team: Initially, the user provides our prototype tool-chain with an OpenMP application written in the C programming language (we do not support C++). Our tool will parse and understand this application and divide it into two categories: software-based and hardware-based. More specifically, we divide everything related to parallel computation (more specifically, OpenMP tasks) into hardware-based and everything related to exposure and management of parallelism in software-based.
Following the said classification, the hardware-generation step begins. We extract the computational part of the application and transform them into a less-abstract format (the so-called intermediate representation) and perform some standard optimizations on it.
Once the computation parts have been optimized, we create a constraint programming model that solves all variables related to the hardware generation. This includes how each instruction is mapped to the hardware hyper-task, how many of each resources we need and whether they are to be shared inside an accelerator or not. We also solve how many hyper-tasks each accelerator contains.
When all parameters have been solved we generate the entire system. This primarily glues together all accelerators through a shared interconnect (Altera Avalon) together with various peripherals and a general purpose processor. We also create a unique memory map for the System-on-Chip, which states where in the memory each device is located. A memory-map is essentially a map of addresses where the different peripherals and accelerators can be found. This memory-map is used in the next phase: source-to-source compilation.
Source-to-source compilation changes all OpenMP-specific directives into using the underlying OpenMP runtime-system. In our case, it is crucial that this phase comes after the hardware has been generated, because both the runtime-system and parts of the translated application requires knowledge about the hardware (e.g. number of accelerators, memory map etc.). The output is a translated C source code that is to be used with the general-purpose processor in the system.
Finally, the application source code is compiled and the generated hardware is synthesized, technology mapped and place and routed to yield a bit-stream. This bit-stream is used to program the FPGA and the user can start using the enhanced OpenMP-accelerated application.
In your conclusions section you say that a main limitation is that you’re not modeling the memory hierarchy. Please explain this limitation and what you might do in the future.
KTH Team: One of the main limitations of our work is that we do not take memory hierarchies into account when generating hardware. This includes everything starting from the hyper-task’s data request until it is satisfied. In our current work, the OpenMP accelerators do not have a cache and instead rely on hiding as-much of the memory latency as possible by executing concurrently.
One of the biggest challenges in encouraging people to use FPGAs is to reduce complexity. While adding a simple data-cache would have improved the performance of the accelerators, currently it would also have required the user to specify the details regarding the cache, which is what we are trying to avoid. Ideally, everything should be automatically derived and modelled, including caches and interconnect width. Today, we do not model the memory.
Future work of ours focus on analyzing memory traces generated by the application offline in order to satisfy the bandwidth and latency requirements of the targeted application.
Whom do you expect to be most interested in this? Where do you think developments in this will eventually land and what needs to happen first?
KTH Team: We believe that the traditionally embedded High-Level Synthesis marked is slowly moving towards the more general-purpose and even HPC communities. Field-Programmable Gate-Array technology can be more power-efficient with respect to CPUs or GPUs. The main focus should right now be to raise the level of abstraction of using FPGA for users.
Thus, the first prerequisite for mainstreaming FPGAs for general-purpose or high-performance computing will be too improve productivity through the use of high-level programming models such as OpenMP but also though the use of data-parallel languages mainly used for GPUs such as OpenCL. CUDA is not likely a candidate as it is too tied the Nvidia hardware.
The second aspect is performance. FPGAs can outperform general purpose CPU but have difficulty in beating GPUs. That is mainly because we are attempting to replicate the GPUs functionality within the FPGAs: we use similar memory hierarchy, similar techniques for hiding latency and – perhaps more importantly – we use the same representations for precision.
One opportunity is to move away from the IEEE standard mantissa/fraction settings for floating point precision, if the application does not require the full precision of the IEEE format. For example, if a user application requires a third of the precision provided by single precision, generating hardware with lesser precision will not only increase the overall peak performance of the system but also benefit data transfers (more numbers transmitted in the same time) and lower power consumption.
Even if we continue to use the IEEE floating point standard, then we can still improve performance by making the FPGA slightly more coarse-grained and introduce hard IP blocks dedicated for floating point performance. This would also increase the peak performance delivered by future FPGA and seem to be the route manufacturers are taking (e.g. Altera Stratix 10).
The full paper with results and detailed descriptions of how the team accomplished this can be found here.


Can SYCL Slice into Broader Supercomputing?
There are a few unignorable trends in high performance computing, especially in the exascale age. First, heterogenous and differing architectures at the major HPC sites are diverging with some using AMD CPUs and GPUs, others Nvidia, and of course, still others sticking with the well-tread Intel path. Second, codes are …

Programming In The Parallel Universe
This week is the eighth annual International Workshop on OpenCL, SYCL, Vulkan, and SPIR-V, and the event is available online for the very first time in its history thanks to the coronavirus pandemic. One of the event organizers, and the conference chair, is Simon McIntosh-Smith, who is a professor of …
Burying The OpenMP Versus OpenACC Hatchet
I have been frequently asked when the OpenMP and OpenACC directive APIs for parallel programming will merge, or when will one of them (usually OpenMP) will replace the other. I doubt the two APIs will or can merge, and whether one replaces the other depends more on whether users abandon …
Be the first to comment