
Todd Mostak, the creator of the MapD GPU-accelerated database and visualization system, made that database because he was a frustrated user of other database technologies, and as a user, he is adamant that accelerating databases and making visualization of queried data is about more than just being a speed freak.
“Analytics is ultimately a creative exercise,” Mostak tells The Next Platform during a conversation that was supposed to be about benchmark results but that, as often happens here, wandered far and wide. “Analysts start from some place, and where they go is a function of the resources that are at their disposal. Systems that are slow interrupt creativity. They reduce the opportunity to have those bursts of creativity that are so powerful. Analytical resources that require minutes of waiting between responses crush those creative impulses and reduce the likelihood of finding critical insights that can change the trajectory of the business.”
So that, indeed, is the whole point of trying to accelerate a database with GPUs, and why we think that database acceleration is going to take off in the enterprise a whole lot more rapidly than GPU-accelerated Java – should that ever find its way into a commercial distribution as was hinted at by IBM, Nvidia, and AMD so many years ago. Admittedly, it would be useful for enterprises to have both, since everything is not a simulation, model, or neural network as often is the impression you get from reading about acceleration in general.
The big problem with not having a zippy database is that people are impatient, and they do stupid things because they need an answer, usually now. This bears reminding for any kind of system, not just a database.
“When it takes too long to get answers, people start to ask only those questions for which they know they can get an answer to in a reasonable amount of time,” Mostak continues. “Further, both the question-maker and the answer-getter will fight hard to defend the ‘rightness’ of those questions because they represent success. This is dangerous. Moreover, because we don’t always know what we are looking for, there can be multiple questions for a given business problem. If each question takes a minute or more to consider, people run out of patience rather quickly, and that means analysts and decision makers often stop short of a complete understanding and adopt ‘directional’ indicators as their guide. No one is immune to this problem – the research is clear on this. Slow systems wear down people and result in sub-optimal outcomes.”
Fast systems with lots of data, on the contrary, let them play around and learn, sometimes useless correlations but often ones that make a difference. This is why Mostak struck out several years ago to create his own GPU-accelerated database from scratch, and having completely reworked that MapD database to make it commercial-grade, the database and visualization system was formally available in March and now has dozens of paying customers (including Verizon and Facebook) and lots more tire kickers.
Back in March, when the commercial grade MapD database first started shipping, Mostak shared some early performance data pitting his own software against two in-memory databases and Hadoop with an Impala SQL query overlay. The MapD system had two Xeon processors and eight Tesla K80 accelerators from Nvidia, and it could chew through 260 billion rows per second on the benchmark test, compared to around 850 million rows per second for that two-socket Xeon machine without any GPUs, (The MapD database is accelerated by GPUs, but you can run it in CPU-only mode and, by the way, you can also run it on IBM’s Power8 chips in addition to Intel Xeons.) That is a factor of more than 300X more throughput.

But what if you need to chew on more than a few billion rows? And what if you want to run the database on a cloud instead of your own servers? To prove that MapD can work well on a cloud with plain old Ethernet linking server nodes equipped with GPU accelerators, Mostak worked with IBM to fire up sixteen bare metal server instances on the SoftLayer cloud, each with a pair of Tesla K80s. The goal was to have a very large dataset, and so Mostak took the flight data set compiled by the US Federal Aviation Administration, which runs from 1987 through 2008 and which has 128 million rows, and replicated it 312 times to create a 40 billion row database. To scale across those multiple GPUs on the SoftLayer cloud, Mostak used the Boost GPU aggregation software from Bitfusion. (We will be analyzing Boost in a separate story this week, so stay tuned for that.)
Mostak did not use any indexing or tiering to try to speed up the queries against the database, and throwing it raw out onto the SoftLayer cloud like that, MapD was able to process 147 billion records per second and had a query response time of between 200 and 250 milliseconds. That is right under the window of time where people get frustrated – which is precisely Mostak’s goal.
The Need For Speed
Mostak tells The Next Platform that MapD is very happy with Bitfusion’s Boost middleware, but that the company is working on its own distributed framework, one that parallelizes and pools both CPU and GPU resources, and moreover that MapD has never tried to be a hyperscale database, like Google’s Spanner or Facebook’s Presto. Where MapD is targeting for the scale of its eponymous database is to span up to hundreds of billions of rows and maybe a few racks of machines.
“This is big data with a little D, but it actually covers 90 percent of the market,” says Mostak. “And even if organizations have databases with trillions of rows, there is usually some smaller working set that is of interest. People don’t usually need millisecond response time on queries spanning trillions of rows.”
Security agencies and ad serving engines at hyperscalers excepted, of course.
To cover its bases and go after some big government contracts, MapD had been working with SGI, which will soon be part of Hewlett Packard Enterprise, to get certified on the UV 300 series of tightly coupled NUMA machines. It is interesting in that the MapD database has autosharding features to break datasets into bits and spread them across nodes in a cluster and this autosharding is NUMA aware as well; importantly, the MapD database can be compiled down to run across CPUs, with or without GPU acceleration, and in a CPU-only setup, the main memory could be much larger (up to 24 TB on a UV 300), and even if the latency might rise as high as even ten seconds, the dataset would be quite large. Kinetica has shown this works with its own projects on a mix of SGI UV Xeon-based systems accelerated by GPUs.
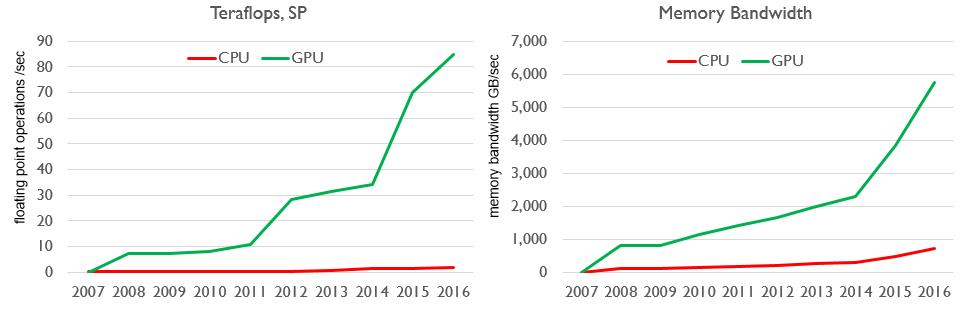
MapD scales across as many GPUs as are available in a single node, which is typically eight or sixteen Tesla K80s, which means up to 32 physical GPUs. Most customers run in servers with eight Tesla K80 GPUs in a single server, says Mostak, but once the Tesla P40, which Nvidia just launched, is widely available, MapD might transition customers to these devices because they have 24 GB of memory per GPU as opposed to 16 GB for the P100s and 12 GB for the K80s. All of these GPUs are so fast relative to CPUs, in terms of their throughput, that computation is not the bottleneck. Memory capacity and memory bandwidth is. So, in essence, more memory trumps more compute at a certain point. We estimate that the P40 that plugs into a PCI-Express 3.0 x16 slot costs about half as much as the P100 with NVLink ports. It has very little double precision performance, at 370 gigaflops, compared to the K80’s 2.91 teraflops across the two GK210B GPUs on the board. The K80 and P40 cost about the same, at roughly $4,700, we think. The upshot is that if you are doing simulation and modeling as well as database acceleration, machine learning, and visualization, you need to buy the Tesla K80s. If you are doing very heavy machine learning and traditional HPC, then the P100 with NVLink is the thing. If you are just doing analytics, database, and machine learning, then the P40 is the ticket.
“Customers can get away without double precision floating point in a lot of cases when it comes to database acceleration,” says Mostak. “We find that with the cards that don’t support double precision math to use decimal formats, and people should not be storing their data in floating point format in a database anyway. Also, the lack of floating point does not hurt you all that much with database anyway. We have been so bound by memory bandwidth on GPUs over the years, although that is less the case with the Tesla P100s with HMB2. Typically, though, even without the good double precision support, you don’t suffer that much with database operations, even if you are doing a few per cycle or a few per byte of data.”
Perhaps much more significant than talk of floating point math is the addition of transcendental functions to the GPU math units that allow for very fast geospatial calculations – and importantly, database joins that allow for the calculation of distances between two points – that run like greased lightning on a GPU but, as Mostak puts it, run “dog slow” on a GPU.
MapD is also gearing up to get its database and visualization software running on IBM’s Power platform, which has a set of benefits that are not available on the Xeon platform from Intel.
“We have the compilation infrastructure for Power8 with LLVM, and sometime back we did some qualification work on Power and it was running well,” says Mostak. “At the time, we didn’t have a need to push on that, but IBM has gotten in touch with us and we are actually just starting discussions on doing formal certification. It should be relatively straightforward, and we are obviously really excited about NVLink. Any time that you can speed up GPU-to-GPU or CPU-to GPU communication, it is a big win. That is one big advantage that IBM Power has over Intel Xeon, in that they are willing to explore alternatives to PCI-Express.”
But again, as the SoftLayer tests aptly demonstrate, NVLink is not a requirement for all distributed databases running across GPUs, and that is so by design.
“Our focus has always been that whatever interconnect you have between CPU and GPU, you are going to have a lot more GPU bandwidth,” Mostak says. “We read with interest the story The Next Platform did on Kinetica, where they said that ganging up multiple GPUs was too costly, and we disagree. They run on tens to hundreds of servers using RAM, which is probably a lot more expensive. We think that it is a lot less costly to have a few servers with Tesla K80s, P40s, or P100s. Moreover, we think that there are a class of problems that are not trillion row problems – they are two billion, five billion, ten billion, or a hundred billion row problems that people need acceleration for just the same. So if you can cache that data on the GPUs, you will get orders of magnitude speedup then if you were trying to stream it off the CPUs – even if you had NVLink, and particularly if you are ganging up eight or sixteen GPUs where you might have many terabytes per second of vRAM bandwidth. So we are excited about NVLink because it means the working dataset can be much bigger than GPU memory, but our architecture already supports that data streaming in from the CPUs. What we find in real-world use is that certain segments of the dataset are being queried over and over in different ways, and we bring that into vRAM and caching is still a good strategy for that.”

From that article or the answers from MapD CEO I can’t see anything that says the same performance couldn’t be achieved on KnL as well.