

Among the many challenges ahead for programming in the exascale era is the portability and performance of codes on heterogeneous machines.
Since the future plan for architectures includes new memory and accelerator capabilities, along with advances in general purpose cores, developing on a solid base that offers flexibility and support for many hardware architectures is a priority. Some contend that the best place to start is with C++, which has been gathering steam in HPC in recent years.
As our own Douglas Eadline noted back in January, choosing a programming language for HPC used to be an easy task. Select an MPI version then pick Fortran or C/C++, however, due to the growth of both multi-core processors and accelerators there is no general programming method that provides an “easy” portable way to write code for HPC (and there may never be). Indeed, it seems writing applications is getting more complicated because HPC projects often require a combination of messaging (MPI), threads (OpenMP), and accelerators (Cuda, OpenCL, OpenACC). In other words, to the HPC code practitioner things seem to be getting harder instead of easier. While Eadline was making the case for Julia as one language option, others are looking to keep building on a set standard.
According to teams at several research sites in Germany and the University of Louisiana, the momentum behind C++ and the need to create a standard, higher-level abstraction and programming model for parallelism in the language for heterogeneous environments is the best path toward meeting exascale requirements. In an effort to demonstrate the viability of such a shift, the team showcased the portability and performance results of such a higher-level abstraction against the STREAM benchmark. While the performance results didn’t blow other approaches based on devices (CUDA, for instance) away, the all-inclusive API had comparable performance in a more portable, flexible package. The effort was not necessarily meant to offer sound performance advantages, but rather, to “provide a single source, generic, and extensible abstraction for expressing parallelism, together with no loss in performance.”
The abstraction work focuses on systems with GPUs in particular and associated C++ hooks inside CUDA, along with other devices that use OpenCL (FPGAs for instance). As work toward the upcoming C++17 standard continues, the team will extend the effort to include support for different memory hierarchy configurations (i.e. Knights Landing with its high bandwidth memory) and extensions for GPUs that use different back-end approaches, including HCC and SYCL.
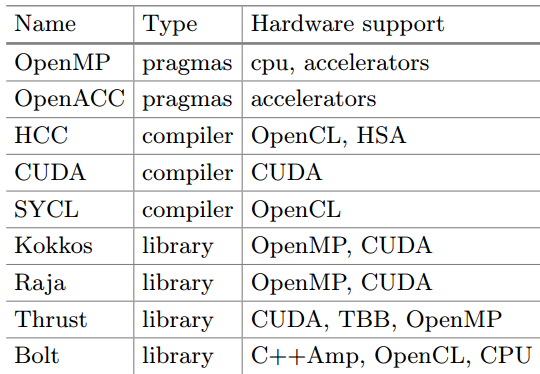
As seen in the table presenting the many different approaches to achieving portable performance on heterogeneous systems, there are many options, but most are pragma-based add-ons (OpenMP, OpenACC). As the team argues, these do not offer good support for C++ abstractions and require the need for new toolchains that directly support the language (as found in the newest versions of CUDA, SYCL, or the new HCC compiler). Less familiar abstractions in the list are based on libraries (Kokkos, Thrust, Bolt, and Raja) which all “offer higher level interfaces similar but not conforming to the parallel algorithms specified in the upcoming C++17 standard.”
The goal with the team’s effort is to wrap around these standards with “Truly heterogeneous solutions, enabling transparent locality control, a feature that is not available for those listed existing libraries.” Additionally, the team hopes to create an alternative for all of the existing accelerator architectures that is not limited to just CUDA or OpenCL within a C++ face to the world.
One of the challenges of creating such an abstraction while preserving performance is keeping the data close to the processing. Any API has to be able to express placement and movement of data to exact memory locations—something that will get more challenging as the memory hierarchy grows more complex at exascale. To address this, the APIs are that are based within C++ need to create “an expressive, performant, and extensible way to control locality of work and data by refining the allocator concept defined in the C++ standard, as well as using a proposed ‘executor’ concept.” These are meshed by defining targets, or places within the system, that are used to assign data placement and execution. These targets can be groups of CPUs for NUMA problems, different memory areas, or accelerators.
In the full paper, the team describes how the API approach can work to control memory placement, execution locality, and handle parallel algorithms and distributed data structures, as well as offer support for NUMA-aware programming. The STREAM benchmark results they provide from their API, as presented via the HPX parallel runtime system, have been ported to the parallel algorithms shows in their new C++ incarnation.

Is Mojo The Fortran For AI Programming, Or More?
When Jim Keller talks about compute engines, you listen. And when Keller name drops a programming language and AI runtime environment, as he did in a recent interview with us, you do a little research and you also keep an eye out for developments. The name Keller dropped was Chris …
AMD Lays Software Foundation For Renewed Hybrid Push
Having the best compute engine – meaning the highest performance at a sustainable price/performance – is not enough to guarantee that it will be adopted in HPC, hyperscale, or enterprise settings. It is arguable, for instance, that chip maker AMD has held the performance lead over rival Nvidia on raw …
C++ is almost a dead horse, they should use RUST or maybe something more exotic like PARLANSE aka PARallel LANguage for Symbolic Expression.
hehe your being ironic right? =D
Its hard to tell on the internets
Hello, not at all!
The history do exhibit this nasty behaviour from time to time and repeat herself.
P.S.
“…the number of UNIX installations has grown to 10, with more expected…”
Dennis Ritchie and Ken Thompson, June 1972
Haskell our other pure functional language get exactly past the conundrum of pure parallel execution. This has been known by programming language researcher since decades but unfortunately mostly ignored by the HPC and general computing community