

In the last couple of years, we have examined how deep learning shops are thinking about hardware. From GPU acceleration, to CPU-only approaches, and of course, FPGAs, custom ASICs, and other devices, there are a range of options—but these are still early days. The algorithmic platforms for deep learning are still evolving and it is incumbent on hardware to keep up. Accordingly, we have been seeing more benchmarking efforts of various approaches from the research community.
This week yielded a new benchmark effort comparing various deep learning frameworks on a short list of CPU and GPU options. A research team in Hong Kong compared desktop and server CPU and GPU variants across a series of common deep learning platforms.
“Different tools exhibit different features and running performance when training different types of deep networks on different hardware platforms, which makes it difficult for end users to select an appropriate combination of hardware and software.”
Specifically, the team used the desktop-class Intel i7-3820 (3.6 GHz, 4 cores) and the server-class Xeon E5-2630 v3 (16 cores) using different thread counts as well as three GPUs; the Nvidia GTX 980 (Maxwell architecture); the GTX 1080 (Pascal architecture) and the Kepler-generation K80 GPU. It is worth noting that in their benchmark results, they are only use on of the two GK210 chips in the K80.

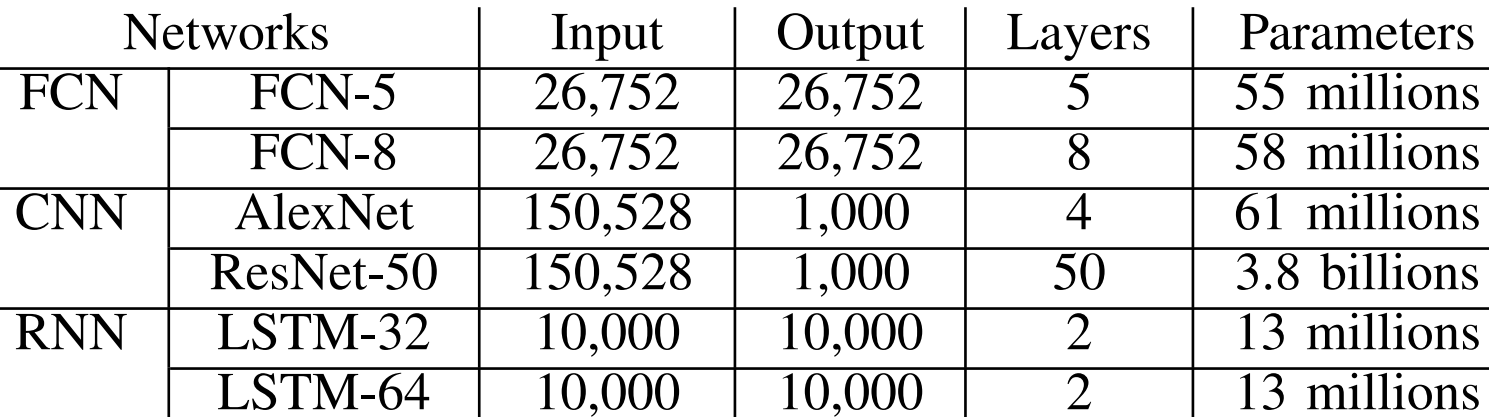
Overall, they found that when it comes to manycore CPUs, not all deep learning frameworks scaled well. For instance, in the benchmarks, there was not much difference in the performance of the 16-core CPU versus the one with only four cores. However, all of the frameworks tested were able to achieve a boost using GPUs with Caffe and TensorFlow showing the most remarkable results. Interestingly, for these workloads, the best-performing GPU was the GTX1080 in these results—noteworthy because it was not necessarily designed for deep learning (rather, the M40/M4, TitanX, and other GPU accelerators tend to be used for these purposes).
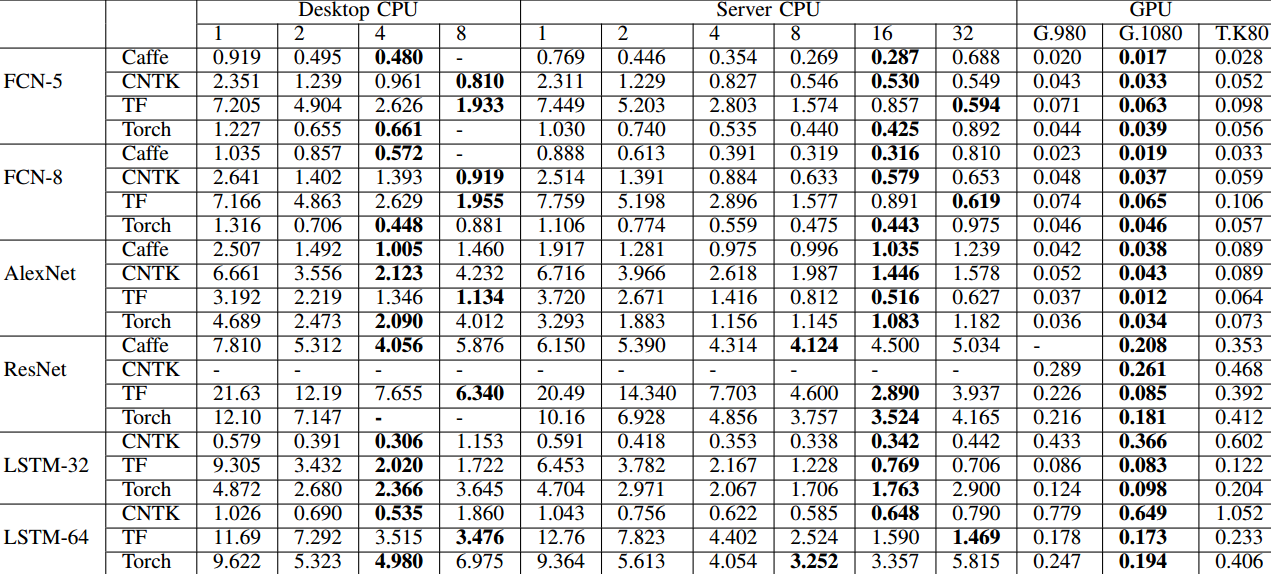
“With GPU computing resources, all the deep learning tools mentioned achieve very high speedups compared to their CPU only versions because of high parallelization on lots of CUDA cores,” the team notes. “The theoretical performance of GTX 1080 is up to 8873 GFlops, which is much higher than 4 or 16 core CPUs, so that the maximum speedup can reach 112X in TensorFlow with the GTX 1080 card. As one might imagine, the performance of the GTX 1080 us better than the 980, but what might surprise some is how much better the 1080 is over the Tesla K80 (although again, it is just using a single one of the two GK210 chips).
The team says that GPU memory capabilities are a major factor in the results for large networks in many frameworks, including Caffe, CNTK and Torch, which can’t run ResNet-50 at the 32 mini-batch size or more on the memory-limited GTX 980 card (only 4GB of memory). They note that TensorFlow is good at managing GPU memory (as seen above). For CPU only runs, Caffe showed the best parallelization results and TensorFlow also can exploit the capabilities offered by multiple threads.
We are always on the lookout for research benchmarks of this nature, particularly those that show the relative performance for various GPU architectures, including the new Pascal-based chips and the M40 and M4, which were specifically designed for deep learning training and inference.
For more details on the above benchmark, including detailed breakdowns of the GPU generations and the relative performance of each using different frameworks, the full paper is here.

Not quiet fair comparison to be honest. As in Caffe and Torch only the parts that use BLAS are parallel that means it is only for back and forward propagation used. Not for the individual layers which are pure CPU serial code at the moment. While these are run parallel on the GPU as well as they have special CUDA implementations. It probably would be fairer to run the CPU optimized branch that has been created by Colfax Research
The forward and backward propagation are the main steps in Deep Learning, the other overhead should be negligible.
I also note that they’re using an old version of CUDNN (v4), they would have gotten a lot more speedup with the latest V5.
It is still very early to compare GPU and CPU in Deep Learning. As it has been said, the bottleneck in most Deep Learning networks is the convolution done in the forward (computation of the objective function) and backward (computation of its gradient) propagation.
A convolution is a very simple algorithm but extremely tricky to optimise because of the memory hierarchy. In order to avoid this kind optimisation, many frameworks use matrix multiplication (BLAS3) to implement their convolution ( https://github.com/Yangqing/caffe/wiki/Convolution-in-Caffe:-a-memo ). Even if you use an efficient BLAS such as the one in MKL, you’ll be slower than a carefully written convolution algorithm.
So this paper compares :
– GPU + convolution algorithm (CUDnn)
– CPU + convolution implemented as matrix multiplication + OpenBLAS
The first “baby step” to have a better comparison should be to replace OpenBLAS with MKL (although OpenBLAS is quite good, it does not scale as well as the MKL when you have a lot of cores). But a better one should be to replace the matrix multiplication by a direct convolution implemented in MKL-dnn.
Well or you can replace the convolution with a FFT as Facebook has done and then it changes it playfield again. But I agree I would have liked to see a comparison with Intel MKL even if OpenBlas proclaims there is not much of a difference between the two
I found numbers from best in class regarding hardware & software from Nvidia and intel respetively.
Intel boasts 8796 images/sec on AlexNet on KNL with their latest software.
Meanwhile nvidia boasts 23 090 images/sec on their P100.
This is really the best hardware and software from the foremost CPU & GPU vendors so its a pretty good benchmark. Intel has definetly improved the software by a lot!