

Over the last couple of years, the idea that the most efficient and high performance way to accelerate deep learning training and inference is with a custom ASIC—something designed to fit the specific needs of modern frameworks.
While this idea has racked up major mileage, especially recently with the acquisition of Nervana Systems by Intel (and competitive efforts from Wave Computing and a handful of other deep learning chip startups), yet another startup is challenging the idea that a custom ASIC is the smart, cost-effective path.
The argument is a simple one; deep learning frameworks are not unified, they are constantly evolving, and this is happening far faster than startups can bring chips to market. The answer, at least according to DeePhi, is to look to reconfigurable devices. And so begins the tale of yet another deep learning chip startup, although significantly different in that its using FPGAs as the platform of choice.
DeePhi is a relatively new company (launched March 2016) based on efforts from teams at Stanford and Tsinghua University, As the startup’s CEO and co-founder, Song Yao, described at Hot Chips this week in his introduction of DeePhi (which is short for the phrase “discovering the philosophy behind deep learning computing”), the economics and time to market pressures matched with the rapid evolution of deep learning frameworks make non-FPGA approaches more expensive and less efficient. [For insight on the economics of this see Nervana’s path with an ASIC]. Yao says that CPUs don’t have the energy efficiency, GPUs are great for training but lack “the efficiency in inference”, DSP approaches don’t have high enough performance and have a high cache miss rate and of course, ASICs are too slow to market—and even when produced, finding a large enough market to justify development cost is difficult.
“FPGA based deep learning accelerators meet most requirements,” Yao says. “They have acceptable power and performance, they can support customized architecture and have high on-chip memory bandwidth and are very reliable.” The time to market proposition is less restrictive for FPGAs well since they are already produced. It “simply” becomes a challenging of programming them to meet the needs of fast-changing deep learning frameworks. And while ASICs provide a truly targeted path for specific applications, FPGAs provide an equally solid platform for hardware/software co-design.

To address the elephant in the room here, if all of these things are true, why aren’t we seeing more FPGAs appear in deep learning acceleration conversations? Because, indeed, they’re still awful to program.
Yao says that traditionally, FPGA based acceleration via hand coding took a few months; using OpenCL and the related toolchain brings that down to one month. Even still, experimental teams were not getting the performance or energy efficiency numbers they desired. With these facts in mind, the team set about to build workarounds for both the performance and efficiency problems while simultaneously tackling the programmatic complexity.
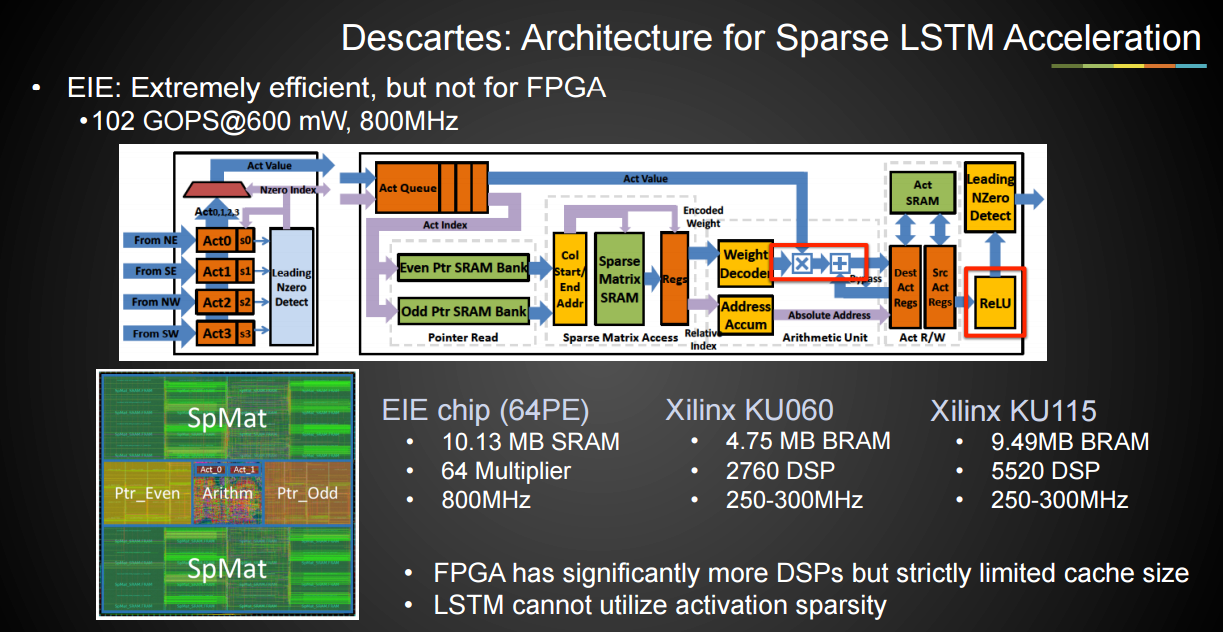
To these ends, DeePhi has produced two separate FPGA based deep learning accelerator architectures. The first is Aristotle (below), which is aimed at convolutional neural network (CNN) acceleration, the second is called Descartes, which is directed at sparse LSTM (long short term memory) deep learning acceleration. These are matched against work that has been done on model compression and “activation quantization” wherein the team found that getting the precision down (8 bits) is perfectly reasonable—at least on this architecture.
The company’s own custom built compiler and architecture is used instead of OpenCL. As Yao says, “the algorithm designer doesn’t need to know anything about the underlying hardware. This generates instruction instead of RTL code, which leads to compilation in 60 seconds.” This is the result of the hand-coded IP core and design of the architecture as well as the deep compression techniques for model compression. “Deep compression is useful in real-world neural networks and can save a great deal in terms of the number of computations and the bandwidth demands.”
Below is the Aristotle architecture, which is designed for CNN acceleration, followed by an architecture drawing of the Descartes processing element.
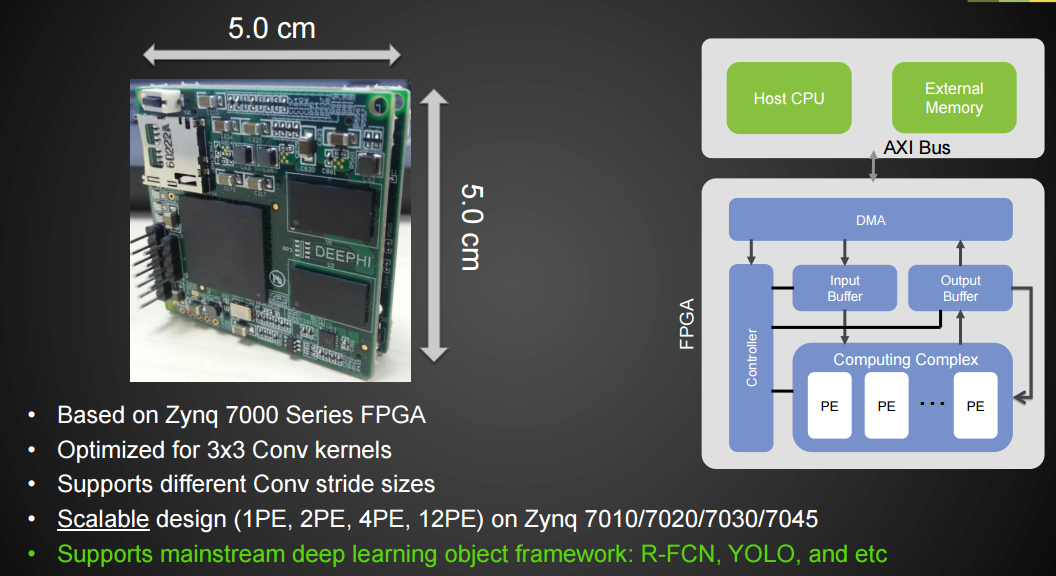
The concepts from the Descartes processing element might look familiar to regular readers due to the addition of the EIE processing element. For a refresher, take a look back at our conversation with Song Han from Stanford (who has since gone on to be a co-founder of DeePhi) and his architecture for a deep learning processor. This did not use FPGAs initially but does find a place in this architecture.
Given the brevity of the presentation and focus mostly on the model compression and other factors, we are still a bit in the dark about how these architectures work in real-world applications. We will be talking with the company well before their test and development boards are released for select users at the beginning of October. Suffice to say, despite the lack of depth into the architectures themselves, the company has done some internal benchmarking for key deep learning workloads to gauge relative performance and efficiency.

Deep compression and data quantization are employed to exploit the redundancy in algorithm and reduce both computational and memory complexity. For both Aristotle and Descartes, evaluated on Xilinx Zynq 7000 and Kintex Ultrascale series FPGA with real world neural networks, the team notes up to 10 times higher energy efficiency can be achieved compared with mobile GPU and desktop GPU. Of course, whether or not this is a fair comparison for server-class deep learning workloads is up to debate since, as we are aware from many interviews, most work at Baidu and other companies is happening on Maxwell TitanX or, at other shops, M40/M4 combos. Nonetheless, especially for lighter-weight use cases, the results are noteworthy.
Again, deep dive details on the architecture are forthcoming post Hot Chips, but for now, it’s useful to point out that while custom ASIC based approaches have been getting a great deal of attention due to some advantages over general purpose hardware and accelerators, there could be cheaper and, with the right software tools in place, easier options on the horizon. For now, DeePhi has an unstated funding sum from GSR Ventures and Banyan Capital to keep pushing ahead on its vision of FPGA-based deep learning. While it might start small (literally, inside of robotic devices), like so many technologies we’ve seen evolve over the last few years, the server story is likely not far off.
Never fun for us not to get the full gore architecture skinny on something in-depth, but this is a good starting point for detail and an interesting talking point: Where’s the benefit to ASIC over reconfigurable devices? Over GPUs? And don’t forget about DSPs….




Be the first to comment