
It is a coincidence, but one laden with meaning, that Nvidia is setting new highs selling graphics processors at the same time that SGI, one of the early innovators in the fields of graphics and supercomputing, is being acquired by Hewlett Packard Enterprise.
Nvidia worked up from GPUs for gaming PCs to supercomputers, and has spread its technology to deep learning, visualization, and virtual desktops, all with much higher margins than GPUs for PCs or any other client device could deliver. SGI, in its various incarnations, stayed at the upper echelons of computing where there is, to a certain extent, less maneuvering room and more intense competition. In fact, systems using Nvidia’s GPU motors have given the shared memory and clusters – many of the latter using Nvidia’s Tesla accelerators to improve their computational efficiency – made by SGI a run for the money. SGI is no doubt wishing it had made GPUs for all kinds of devices and had transformed its OpenCL environment into something akin to CUDA.
Nvidia has just turned in its financial results for the second fiscal quarter, which ended on August 1, and the numbers are very good. The company is firing across all of its various cylinders and has gotten itself back on track with gross margins that are the envy of many hardware manufacturers and profits that represent a very respectable portion of its overall revenues.
Given that this is just the beginning of the wave of devices that are based on the “Pascal” GPUs, and that the appetite for visualization, desktop virtualization, and compute are not abating and that AMD is not much of a threat with its own GPUs (particularly on the compute front), it is reasonable to expect that Nvidia will be able to sustain its trajectory of rising revenues and profits in the coming quarters as Pascal products ramp.
Nvidia co-founder and CEO Jen-Hsun Huang said on a call with Wall Street analysts that all of the variants of the Pascal GPUs have taped out, meaning they are ready to be put into production, but not all of them have been launched as yet. (More on that in a moment.) Our point is that it is always hard to guess how yields on complex products will improve, and Huang said as much. The fact is, the Pascal GPUs are by far the most complex devices Nvidia has ever made and they rival the most innovative products that Intel and AMD have brought into the field with their respective “Knights Landing” Xeon Phi and “Polaris” FirePro S9300 x2 compute engines. So you can understand why looking ahead Nvidia is only providing financial guidance for the third fiscal quarter, which will end in early November.

In the second fiscal quarter just ended, Nvidia’s overall sales climbed 24 percent to $1.43 billion, and against a very easy compare Nvidia showed a very impressive 873 percent increase in net income year-on-year to hit $253 million. In the year ago period, however, Nvidia took an $89 million writeoff after deciding to shutter its Icera modem business and to cover a recall on its Shield tablets. Still, even without these charges, Nvidia’s net income would have at least more than doubled, and when you have profits growing 10X faster than revenues, this is always a beautiful thing.
While Nvidia’s Tegra processor business is still small, it is seeing traction as it is being deployed in uses cases ranging from tablets to self-driving cars to drones to gaming devices like its own Shield product. Revenues derived from straight GPU products – including GeForce desktop GPUs, Quadro workstation GPUs, GRID visualization and virtualization GPUs, and Tesla compute GPUs – rose by 25 percent in the quarter to kiss $1.2 billion. The Tegra line of chips, which marry ARM cores to its GPUs in a system-on chip design, grew by 30 percent to $166 million. Helping bolster this Tegra business is good engineering, with the Tegra X1 offering 1 teraflops of floating point performance. Nvidia is still getting $66 million a quarter in royalty payments from Intel, which settled a lawsuit in January 2011 for $1.5 billion.
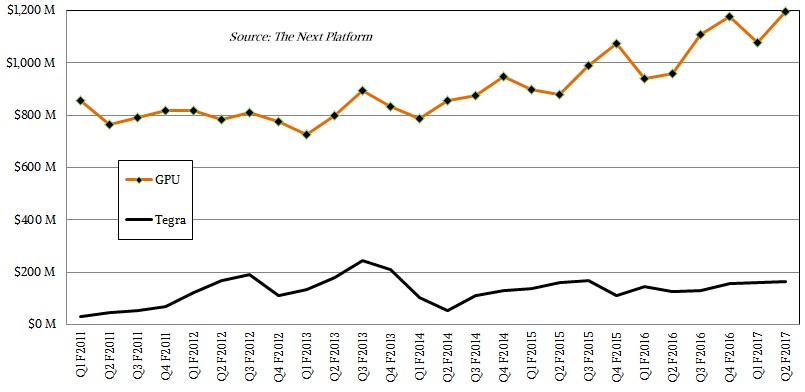
Starting with fiscal 2016 in April of that year, Nvidia has been providing a bit more insight into its various business lines.
Here at The Next Platform, we believe that the most important product lines are in Nvidia’s Datacenter division, but the Gaming and Professional Visualization provide the mass markets that allow Nvidia to ramp up volumes and spread the cost out for GPU innovations that are leveraged in datacenters and that eventually trickle down to other markets like the automotive industry or other OEM customers. It is the synergy between products and across divisions and customer sets that makes this a more stable business. This also allows Nvidia to continue to sell older generation technologies in one line, such as GRID virtualization or automotive processing, while pushing cutting edge products, such as the Pascal GPUs to deep learning and supercomputing accounts.
Here is a case in point. The Pascal GP100 GPUs made their debut back in April, and the vast majority of the devices that Nvidia could ship went to hyperscalers for their deep learning workloads, particular for the training of their algorithms. Performance has been bottlenecked for these applications, the world’s largest hyperscalers were presumably happy to pay a premium for the Tesla P100 cards. We estimate they have a list price of around $10,500, based on the configuration of Nvidia’s own DGX-1 machine learning appliance. In May, Nvidia rolled out a new Tesla GRID card, which was able to host more virtual desktop infrastructure (VDI) instances than its predecessors, but this was not based on Pascal GPUs, but rather on a variant of the prior “Maxwell” family of GPUs, which incidentally never came in a variant with any floating point performance suitable for HPC workloads that need double precision. But those Maxwell GPUs are mature and their manufacturing processes are well understood, and that is why Nvidia has plunked four of them on a single card to create the new Tesla M10 GRID motor. Check it out:
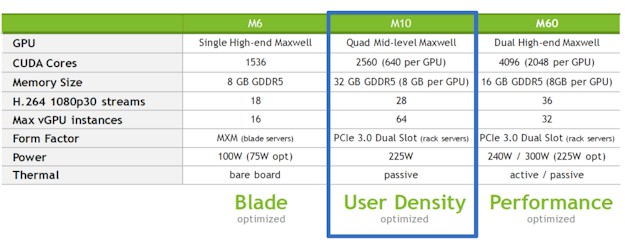
The Tesla M10 is interesting in that it shows how Nvidia can make use of older and less capacious devices in clever ways to expand its market and to boost earnings. By putting four Maxwell GPUs on the card with only 640 CUDA engines, the yield per device presumably goes up relative to the much larger GPUs in the Maxwell and Pascal families, and therefore Nvidia can drive VDI adoption into newer markets and still deliver a heftier VDI experience, perhaps with the Tesla M60, for those who need it. Ditto for deep learning, where double precision floating point is not particularly useful. In this case, the Maxwell-based Tesla M4 and M40 GPUs can be offered at a very attractive price for those hyperscalers that might otherwise move to other options for deep learning inference and training. We don’t follow the GRID products as closely as the other members of the Tesla family, but what we can safely say is that as GRID adoption grows, it will make Nvidia’s overall datacenter business stronger because it will be more diverse and on a different product cycle and adoption curve than the proper Teslas used in HPC and hyperscale.
During the second fiscal quarter, Nvidia was not just making high-end Tesla P100 GPUs that were scarfed up by hyperscalers and deep learning researchers (the first DGX-1 has just shipped), but was starting to spread the Pascal GPUs to other parts of its line. In the GeForce GTX 1070 and 1080 and the PCI-Express variants of the Tesla P100 cards, the Pascal GPUs do not have NVLink interconnects and they talk to GDDR5X frame buffer memory instead of the High Bandwidth Memory (HBM) used in the high-end Pascal Tesla P100s. (We covered the PCI-Express Tesla P100s here.) The Quadro P5000 and P6000 workstation chips, which are rated at 12 teraflops and 8.9 teraflops single precision, just launched in July, and are only beginning to help bolster revenues. Nvidia doesn’t think of the Quadro cards as compute engines, but some of its biggest customers do, and ditto for the GeForce graphics cards.
When these products are sold to customers doing simulation, modeling, or machine learning, they don’t get counted in the Datacenter division at Nvidia. The dividing line is by product, not by customer use case. The fact that all of the Nvidia cards support CUDA doesn’t stop them, but the Tesla products have more features aimed at enterprise customers, which Nvidia believes justifies the premium that it charges for them, and to a large extent, customers seem to agree.
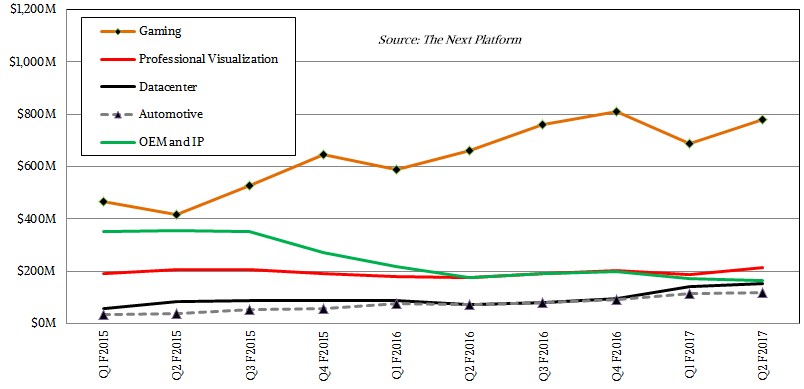
In the quarter just ended, the Datacenter division posted sales of $151 million, up 110 percent. Huang said on the call that about half of the revenues for this division came from machine learning customers, with 35 percent coming from traditional HPC shops and the remaining 15 percent coming from GRID virtualization engines. Huang characterized the HPC part of the business as growing and steady, and said that the GRID portion had also more than doubled in the quarter. In other words, HPC as we know it is not as big of a driver. But if we do the math for the second quarter of last year, when the Datacenter division had a 13 percent decline year on year, it turns out that the HPC business has to more than double for the math to work. But against what would have been a more typical quarter, this HPC segment of the Datacenter division would have grown maybe 65 percent or 70 percent. We take his point. The key thing is that this business as a whole probably has gross margins in the range of 75 percent, based on data Nvidia released on 2015, which makes it a very lucrative business indeed. Perhaps one of the most profitable hardware businesses around these days, even with the cut-throat pricing that HPC shops and hyperscalers must surely insist on.
Nvidia helped create deep learning that actually worked, and it deserves credit for that, and its financial results reflect this. And Huang believes that what is going on at the hyperscalers is but a preview of what a future enterprise datacenter will look like, and therefore a leading indicator of how much more market there is left for Nvidia to capture.
“If you think about datacenter traffic going forward, my sense is that the workload is going to continue to be increasingly high throughput, increasingly high multimedia content, and increasingly of course powered by deep learning,” Huang explained. “And so I think that’s number one. And second is that the architecture of the datacenter is recognizably and understandably changing because the workload is changing. Deep learning is a very different workload than the workloads of the past. And so the architecture, it’s a new computing model, it is recognized that it needs a new architecture, and accelerators like GPUs are really a good fit.”
Interestingly, Huang threw a compliment Intel’s way – and did not mention the OpenPower collective – when asked if Nvidia saw a need for a unified CPU and GPU architecture in the datacenter as it once was going to do through “Project Denver” and which it still does with the Tegra line.
“My sense is for datacenters, energy efficiency is such a vital part,” said Huang. “Although the workload is increasingly AI – and increasingly live video and multimedia where GPUs can add a lot of value – there is still a lot of workload that is CPU-centric, and you still want to have an extraordinary CPU. And I don’t think anybody would argue that Intel makes the world’s best CPUs. It’s not even close, there’s not even a close second. And so I think the artfulness of, and the craftsmanship of, Intel CPUs is pretty hard to deny. And for most datacenters, I think if you have CPU workloads anyways, I think Intel Xeons are hard to beat.”
There are more than a few partners of Nvidia, including IBM with Power and Cavium and Applied Micro with ARM, that are going to try to do just that. Competing with Intel is, as far as CPU processors go, the only game in town, and Huang no doubt wants them to do their best. It will help his company’s top and bottom line if they do.
As for deep learning continuing to be half of the Datacenter division business over the long haul, we would point out that the hyperscalers buy in big lots and they were at the front of the line for the Pascal Tesla P100 GPU accelerators, which cost many times more than even an expensive graphics card in the GeForce or Quadro lines. So, yeah, there was going to be a big bump in the second quarter as there was in the first, and we think an equally large portion of the fiscal Q1 revenues were driven by deep learning, too. But at some point, these hyperscalers will have built out their clusters.
We would not be surprised if the revenues hit an equilibrium (measured over the course of a 12 or 18 months) where deep learning, HPC, and GRID all contribute about a third of the revenues in the Datacenter division. It will be good for Nvidia – and all of its customers – if it has many revenue streams rising and falling at different cycles rather than all at once. This makes for a steady business that can keep innovating and that can keep Wall Street happy, too.


One Way To Bring DPU Acceleration To Supercomputing
That is not a typo in the title. We did not mean to say GPU in title above, or even make a joke that in hybrid CPU_GPU systems, the CPU is more of a serial processing accelerator with a giant slow DDR4 cache for GPUs in hybrid supercomputers these days …
After The 2022 Bump, Arista Is Back To The Grind In 2023
For Arista Networks, the poster-child of hyperscaler and cloud build networking that, more than any other vendor, has championed merchant silicon and Linux as the basis of a modular network operating system, 2022 was a bumper crop year. This year, there are many new things going on, but the compares …

Los Alamos Pushes The Memory Wall With “Venado” Supercomputer
Today is the ribbon-cutting ceremony for the “Venado” supercomputer, which was hinted at back in April 2021 when Nvidia announced its plans for its first datacenter-class Arm server CPU and which was talked about in some detail – but not really enough to suit our taste for speeds and feeds …
@TP Morgan. Really great summary of Q2 earnings, thank you. Your comment about 1/3 each rev contributions in the last paragraph was interesting. Personally I think deep learning has far more potential over the long term. CEO made an interesting point in earnings call about the scaleability of the platform that reaches from data center to handhelds. I can see that vision. And Tim Cook does as well in a recent interview with Wash Post. AI is going to explode in the next few years. cheers