

A first wave of benchmarks and real-world application runs on Intel’s Knights Landing has hit the shores and while not all the codes will be familiar or widely used, the takeaway of significant performance gains between the new generation and its Xeon Phi predecessor are clear.
As we described earlier this summer, the performance projections Intel released about Knights Landing were spot on and now that researchers are getting devices in their hands, these results will be put to further test. And as detailed previously, there are stark differences between Knights Corner and its bigger, badder successor, Knights Landing.
Take for instance a particle-in-cell laser plasma simulation code called PICADOR, which is used in several domains where laser/plasma interaction are analyzed. The C++ code has been tested on both generations of the Xeon Phi by a team of researchers in Russia and Sweden. The code had already been ported and optimized for Knights Corner (the first generation Xeon Phi), but was reworked for Knights Landing for a net result of a 2.43X speedup over the previous generation using the same configuration. On the newest generation Xeon Phi, the code achieved 100 GFLOP/s of double precision performance—a noteworthy metric for any simulation code.
The particle-in-cell method has already been successfully implemented on GPUs as well as earlier generation Xeon Phi. The team already benchmarked the Knights Corner variant of Xeon Phi and found that while it was relatively simple to port their existing codes, getting leaps in performance over those multicore CPUs would take extra effort, particularly in terms of vectorization.
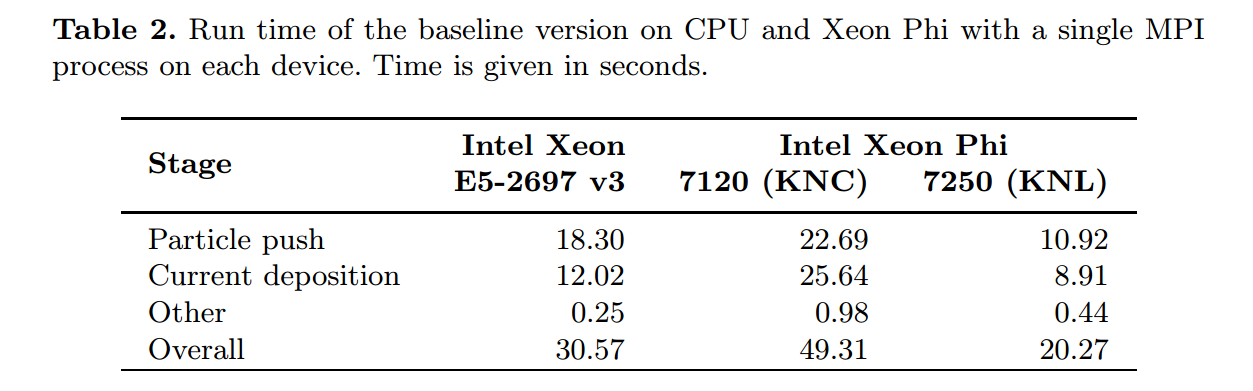
Testing of the code took place across a 14-core Haswell CPU, a first generation Xeon Phi (61 core Knights Corner), a Knights Landing processor with 68 cores (1.4 GHz) and an Intel Xeon Phi 7250 in Quadrant cluster mode with all data placed in MCDRAM.
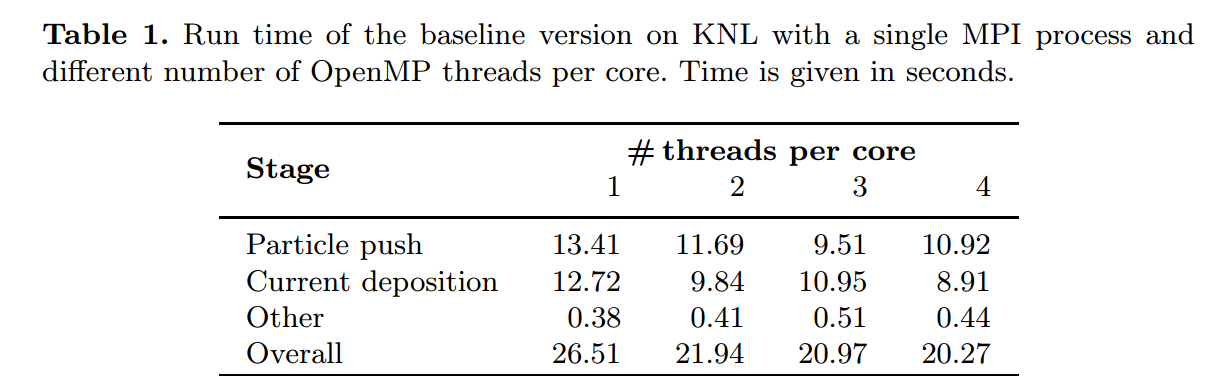
Based on the above, the team says, “just rebuilding the code for Knights Landng with no additional optimization results in a significant speedup compared to Knights Corner,” which is not a surprise since the Knights Landing projected peak performance is almost triple that of its predecessor.
According to the team, although there was a 2.43X speedup compared to the Knights Corner coprocessor by a simple rebuild of the code, “choosing the optimal configuration of processes and threads for Knights Landing and applying several techniques to improve performance leads to a 1.89X speedup on Knights Landing compared to the baseline version.” They also note that auto-vectorization of one particular bottleneck in the parallel code, which led to a significant slowdown on Knights Corner was resolved on Knights Landing due to capabilities new to the AVX-512 instruction set.”
Ultimately, the performance of the optimized on the optimized Knights Landing code is 2.35X over a 14-core Haswell CPU and 3.47X compared to a 61-core Knights Corner coprocessor. There are several speedups stated for different optimization levels and while the full results with various stages are detailed in the paper, it does show Knights Landing is primed for simulations of this nature—that is, following the code footwork required beyond optimizations made for Knights Corner.
“Overall, the results show that Knights Landing is a promising platform for particle-in-cell plasma simulation. Compared to the previous generation Knights Corner, it opens new prospects for performance improvement,” the team concludes. “Same as for Knights Corner, approaches to optimization are mostly shared with CPUs. It allows maintaining a single version of the code for CPUs and Xeon Phi, probably with some minor changes.”
The full results and details about the code and optimizations can be found here.


DUG Sets Foundation For Exascale HPC Utility With Xeon Phi
While exascale systems, even at the single precision computational capability commonly used in the oil and gas industry, will cost on the order of $250 million, that cost pales in comparison to the capital outlay of drilling exploratory deep water wells, which can cost $100 million a pop. The trick …

Knights Landing Can Stand Alone—But Often Won’t
It is a time of interesting architectural shifts in the world of supercomputing but one would be hard-pressed to prove that using the mid-year list of the top 500 HPC systems in the world. We are still very much in an X86 dominated world with the relatively stable number of …

Early Benchmarks on Argonne’s New Knights Landing Supercomputer
We are heading into International Supercomputing Conference week (ISC) and as such, there are several new items of interest from the HPC side of the house. As far as supercomputer architectures go for mid-2017, we can expect to see a lot of new machines with Intel’s Knights Landing architecture, perhaps …
Be the first to comment