
In the first part of this series on the proposed Cache Coherence Interconnect for Accelerators (CCIX) standard, we talked about the issues of cache coherence and the need to share memory across various kinds of compute elements in a system. In this second part, we will go deeper into the approach of providing memory coherence across CPUs and various kinds of accelerators that have their own local memory.
A local accelerator could potentially be anything. You want something to execute faster than what is possible in today’s generic processors, and so you throw specialized hardware at the problem. Still, as a simple case in point, an accelerator could potentially be nothing more than a reserved processor core used for one purpose, wherein the data being accessing is maintained completely within that processor’s cache. But it could be a lot more as well.
In the animation below, we start with the same system we looked at before but merely rename one of the chips as “accelerator.” This accelerator, just like the generic processors, is capable of talking over the SMP fabric to access memory and maintaining a system-wide coherent cache. We are not really saying here what the accelerator is since we don’t really need to. All we care about is that, as an accelerator, this unit it can do its work faster; additionally, it can access data faster by having pulled the accelerator into the system and made it a peer with the traditional SMP processors. And, again, the accelerator can have a completely different instruction set than that of the existing SMP’s processor; indeed, the instruction set might be nothing more than the operation “GO.”
Still, go ahead and mentally reconfigure that Accelerator chip for yourself. Rather than using the chip’s real estate as shown, perhaps it instead has:
- A set of GPUs.
- Just a few processors with most of the chip configured as cache, allowing what can be essentially on-chip memory.
- Hardware to drive typical database operations more rapidly.
- Network acceleration applications.
- Specialized circuitry to accelerated gene analysis.
- Specialized circuitry driving encryption and authentication
You could add many more to this list.
So, in this animation above we have an SMP core building an object, one here residing arbitrarily in four distinct data blocks. Because these SMP cores and the accelerator share the same memory and the cache is coherent, all that the SMP core needs to do to build an object for consumption by the accelerator is to build the object within its own cache and leave it there; no explicit data copying into the accerator’s memory is requried. Once built in any cache, the object is visible everywhere and to anything using that data’s real address. This is one of the natural attribtes of having coherent cache. Nothing more is required by the application building the object except perhaps to inform a consumer thread – one capable of running on an accelerator – that the object is available for consumption.
The accelerator, once informed of the work request, accesses the same data blocks which subsequently flow – think pull – over to the accelerator. The accelerator, using the real address of those blocks (a real address representing the blocks location in the DRAM), finds the most current data in a cache, and pulls the data from there. Once the blocks are in its own cache, the accelerator processes the object and alters the object as needed. Once complete, again nothing more need be done with the location of the object; it can remain in the Accerator’s cache indefinitely. If some one wants it, it remains visible in this cache just as it would be in any cache.
So then, we have the accelerator informs another thread – say one capable of executing on the SMP’s core – that it has completed it processing; some core of the SMP might even have been polling for such completion. With the accelerator’s operation complete, all the the SMP’s application needs to do is reaccess the object, using the same real address(es). The result of this access is that – since all cache is coherent – the data blocks flow back to an SMP core’s cache for processing there.
All accesses are using the same real address(es), the hardware does the rest. There is no software overhead here to create copies of data; copies are made, yes, and data is flowing, but its just part of normal cache coherence.
Please understand that all of these data blocks are really just newer versions of the data blocks originating in the SMP’s DRAM. In the fullness of time, as the cache ages out these data blocks from the cache, these data blocks – now updated by both the SMP core and the accelerator – will return to their orginal, real-addresed, location in the DRAM. Again, from a software point of view, from the point of view of programming languages, those DRAM locations are where this changing data had been perceived as existing all along; the cache is largely transparent from software’s point of view. But, as you have seen, the reality is that the changing data spent a fair portion of its lifetime in some cache.
Getting Accelerators Coherent
Now the reason for this rather awkward name begins to make some sense. From a hardware designer’s point of view, this must seem rather like a dream beginning to come true. It can’t be any fun to have their ideas for accelerated function to be shot down simply because it takes too long to communicate with their hardware.
But the job of the CCIX is not likely to be simple. The current cache coherence architectures really are proprietary, with each being different. Further, although there are some obvious basics as shown earlier, what underlies even those basics are mind-bendingly complex. Accelerators want to use the language of just one architecture and use it talk to any of many of even today’s SMP hardware. So how’s that going to happen? Yours truly doesn’t know, but I’ll be glad to provide a pound or two of conjecture.
I start by asking you to consider this figure from an article on The Next Platform called Inside Oracle New SPARC M7 Systems.
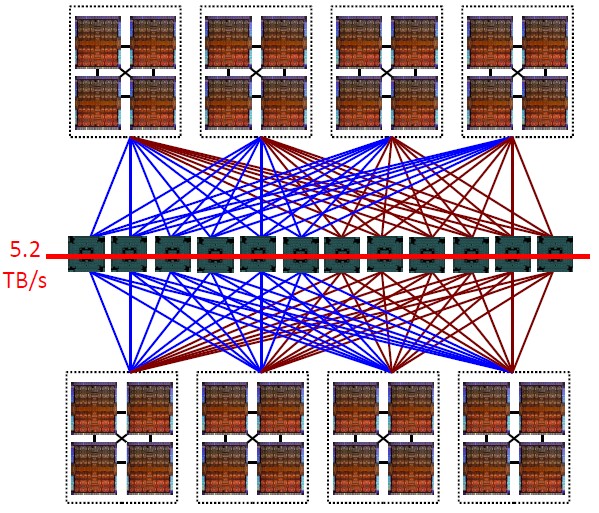
This figure happens to represents a 32-chip, 8-core per chip, cache-coherent NUMA SMP created by Oracle. All 256 of these cores can access any memory – and so any cache – throughout this system. To find a current data blocks location, every core on any chip can poll every other chip, some with a single hop, most by way of Oracle’s Bixby chip – the chips making up the horizontal row in the middle – with two or three hops. Yes, the extra hops add some nominal latency. Said differently, some arbitrary core on some arbitrary chip incurring a cache miss can ask all others whether their cache has its needed data block and do so within at most three hops. Sure, if we can limit such cache-coherency traffic to a single chip or a 4-chip node, accesses would be faster, but recall this article is about attaching accelerators. (We will, though, be discussing some coherency traffic filtering shortly.)
These, as with all SMPs, are homogenous, being made up of the same type of chips. So, as before, let’s instead mentally take at least one of these chips or nodes and make it an accelerator. The M7 and Bixby chips are here, sans accelerator, sharing a common cache-coherence architecture. But let’s say that your chosen accelerator node(s) use a different architecture to access memory. How are they going to communicate?
We trust that you are ahead of us here. These cache-coherence architectures are each doing essentially the same thing, they are largely just using a different language to say it. So they need a translator to communicate. That translator becomes part of the function of what is supported by the chips in the center. Your accelerator’s German goes into some of the chips in the center, the SMP’s English comes out.
Actually what’s needed is a configurable translator. As a case in point, the above homogenous system has no need to be multi-lingual; translation is only required when the system is heterogeneous. Making it still more difficult, is translation between two languages going to be enough? Not likely. So now we are talking poly-lingual with each chip being configured to handle the languages of only the attached chips.
So, the chip is a translator. That chip, though, is also likely to be a Filter.
To explain, you’ll recall we said that some cache coherence traffic can be limited to the cores of a chip or to the chips of a single node; successfully completing a “memory” access without leaving the chip means a faster access. For example, upon a cache miss, if the data block you want happens to reside only within the cache of a neighbor core, the cache coherency traffic need not leave the core’s chip. Knowing that your data accesses need not always require asking every chip provides the significant benefit of speeding data access and decreasing the cache-coherent fabric’s bandwidth utilization. Such accesses know that they can be limited in this way because they know a priori that no other node or chip has the requested data block.
So, let’s turn it around. Suppose that the system had a way of knowing that your chosen accelerator above does not have in its cache a needed data block. Does the remainder of the system then need to ask your accelerator whether it has that block? Such knowledge can be carried in a filter which, when asked, tells the system that the accelerator need not be polled; the Filter, acting as a proxy for the accelerator’s cache state, knows that the accelerator does not have the needed data block. The cache-coherence traffic can avoid going any further than the filter.
As with the translator capability, with the accelerator on one side of a chip and the SMP on the other, with this filter residing on the chip in the middle, the cache coherence traffic can avoid having to poll the accelerator.
Similarly, from the point of view of the accelerator, if the filter chip can tell the accelerator that no other chip in the system has a data block otherwise owned and accessed by the accelerator, the cache coherence traffic then hardly leaves the accelerator. Clearly, though, occasionally data really is being shared between the accelerator and the SMP and then cache coherency traffic must include the potentially large set of interested parties.
Of course, I’m not talking about simple stuff here, and I’ve not even touched on some interesting complexities with addressing, but you can see how the CCIX might make this needed cache coherency happen.
Of Addressing, Real And Otherwise
To finish off, let’s start by observing that, although cache hardware can manage cache coherency via real addresses – this being the type of address which uniquely represents every byte in addressable physical memory (e.g., DRAM) – far and away most programs don’t use real addresses. Instead programs work with a higher level address type which, at the very least, abstracts away the physical location of the objects being accessed by the program; the type of address used by programs is rapidly translated by hardware to a real address to complete the memory access, and such address translation is securely managed by the OS. This higher level address abstraction happens to also be key to the security and integrity of operating systems and the data they manage, but that is for another article. (See Addressing Is The Secret Of Power8 CAPI, which ran recently on The Next Platform.)
So why this strange transition to IBM’s CAPI? CAPI provides accelerators of various kinds the capability of securely accessing into a PCIe-attached Power SMP’s memory using such higher level addresses. With such addresses, the accelerator can directly interpret high-level objects. A Process executing in the SMP, creating such high level objects containing these addresses, can simply have the accelerator access such objects as though the accelerator were executing Threads within the same Process. Fast. In fact, quite a few accelerators have found this to their advantage. (See Several CAPI-Enabled Accelerators for OpenPower Servers Revealed.)
CAPI allows an accelerator to reach into and even change the SMP’s memory, being additionally aware of the SMP processor’s cache, while using such a high-level address. It’s great for performance for the accelerator to address the SMP’s memory that way, but the cache coherency is rather one-sided. Unlike a fully cache-coherent system, with CAPI-based accelerators, In order for the SMP to see that changes being made by the accelerator, the accelerator needs to put the data back into the SMP’s memory; the SMP cannot extract data from the accelerator. Further, as I recall, CAPI does not (yet?) allow the SMP’s processors the capability to access and then cache the contents of the accelerator’s memory. That’s what I mean by “one-sided.” Cache-coherence in an SMP tends to be symmetric across the SMP’s processors and memory; all processors can access all memory and the state of all data in the caches remains coherent.
Perhaps such enablement is partly why IBM is part of this CCIX consortium?

Before Long, Datacenter Will Be Nvidia’s Biggest Business
It is hard to remember sometimes way back when, in 2008, as Nvidia first took a stab at GPU compute in the datacenter with the original Tesla GPU accelerators and a very rudimentary CUDA programming environment for offloading parallel algorithms from CPUs to GPUs. It has been a long road …
How Nvidia Blackwell Systems Attack 1 Trillion Parameter AI Models
We like datacenter compute engines here at The Next Platform, but as the name implies, what we really like are platforms – how compute, storage, networking, and systems software are brought together to create a platform on which to build applications. Some historical context is warranted to put the Blackwell …
Crafting A DGX-Alike AI Server Out Of AMD GPUs And PCI Switches
Not everybody can afford an Nvidia DGX AI server loaded up with the latest “Hopper” H100 GPU accelerators or even one of its many clones available from the OEMs and ODMs of the world. And even if they can afford this Escalade of AI processing, that does not mean for …
These articles provide a pretty good description of how something like CCIX would work. The description of the filter could use a bit more clarification, though. In particular, ” upon a cache miss, if the data block you want happens to reside only within the cache of a neighbor core, the cache coherency traffic need not leave the core’s chip”. The only way the filter can know this is by effectively checking every other chip, so it can’t be done quite this way. What the filter *can* do is to make the status of cache blocks for the processors/accelerators/etc it covers visible to its peer filters. So, the processor you mention only has to keep its filter up to date. So, though status has to be propagated up to the filters, in many cases it does not have to be propagated back down and then back up. This is where you can get a performance win.