

MPI (Message Passing Interface) is the de facto standard distributed communications framework for scientific and commercial parallel distributed computing. The Intel MPI implementation is a core technology in the Intel Scalable System Framework that provides programmers a “drop-in” MPICH replacement library that can deliver the performance benefits of the Intel Omni-Path Architecture (Intel OPA ) communications fabric plus high core count Intel Xeon and Intel Xeon Phi processors.
“Drop-in” literally means that programmers can set an environmental variable to dynamically load the highly tuned and optimized Intel MPI library – no recompilation required! Of course, Intel’s MPI library supports other communications fabrics including InfiniBand as well. Programmers can also recompile using the Intel MPI library to transition from OpenMPI and other non-MPICH binaries.
Training a machine learning algorithm to accurately solve complex problems requires large amounts of data. Previous articles in this series discussed an exascale-capable machine learning algorithm and how the Lustre file system supports the scalable preprocessing and load of large training datasets with TB/s (terabyte per second) data rates.
Once the training data is prepared, a distributed MPI application is then used to adjust the parameters of the machine- or deep-learning model through a ‘training’ or optimization procedure. All distributed communications pass through the MPI library, which means that the motivation and investment in TF/s (teraflop per second) computational hardware, numerous computational nodes, and a low-latency high-bandwidth network framework will be for naught if the MPI implementation isn’t performant.
This article will focus on the performance and scalability work performed by the Intel MPI team and how it benefits machine learning. However, MPI is so intimately tied to scientific and commercial HPC that the benefits of the Intel MPI library extend far beyond what is discussed in this article.
Scalability and binary compatibility
Intel has verified the scalability of the Intel MPI implementation to 340,000 MPI ranks [1] which represents a greater than 100x increase beyond the 3,000 node machine learning results discussed in the previous article that delivered 2.2 PF/s of average sustained performance. Each MPI rank is a separate process that can run on a single core or in a hybrid multi-threaded model where each MPI process uses threads to take advantage of multiple cores in a node.
Machine learning and deep learning applications utilize a hybrid MPI/multi-threaded model to exploit all the vector and parallel capabilities of the hardware. Many legacy HPC MPI applications are transitioning to the hybrid model to better exploit vector floating-point capabilities. For example, utilizing the full AVX-512 floating-point capability can result in a potential 8x speedup over a non-vector floating-point dominated code. Machine learning training is very floating-point intensive and parallelizes well, which means it fits well in the lower right hand side of the following Intel performance schematic.
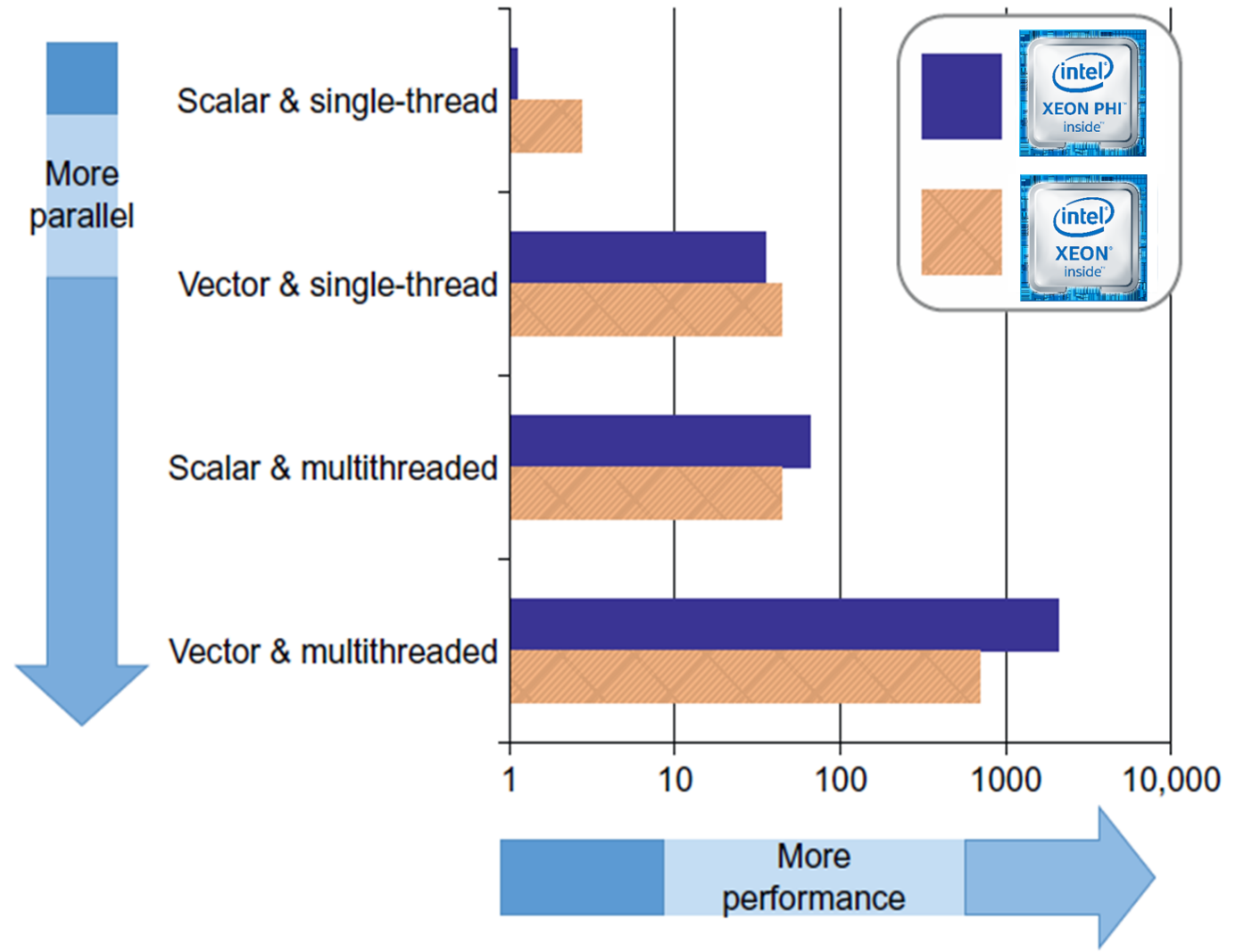
Figure 1: Benefits of a hybrid model (Image courtesy Intel [1])
The Intel MPI library supports the latest MPI-3 standard and is binary compatible with existing MPI-1.x and MPI-2.x applications. This means that even legacy HPC applications can use the Intel MPI library without recompiling to run efficiently on the latest generation Intel hardware.
Further, the Intel MPI effort is an active participant in the MPICH ABI Compatibility Initiative. The MPICH Application Binary Interface, or ABI, is the low-level interface that determines such details as how functions are called and the size, layout and alignment of datatypes. With ABI compatibility, programs conform to the same set of runtime conventions, which ensures that any MPICH-compiled application – regardless of which vendor library was used for compilation – can use the Intel MPI runtime.
Broadcast performance and scalability
Deep learning networks can contain millions of parameters that must be broadcast to all the distributed processors during each step of the training procedure. For example, the ImageNet deep convolutional neural network that is used to classify 1.2 million high-resolution images contains 60 million parameters [2]. Very deep convolutional networks can contain 138 million parameters [3]. Each of these parameters can be expressed with a four-byte single-precision or eight-byte double-precision number.
The following graph shows how the Intel MPI team has achieved an 18.24x improvement over OpenMPI. This added performance can help to speed the training of deep and very-deep image recognition neural networks. In particular, the 524,288 message size can broadcast the parameters for big convolutional neural networks.
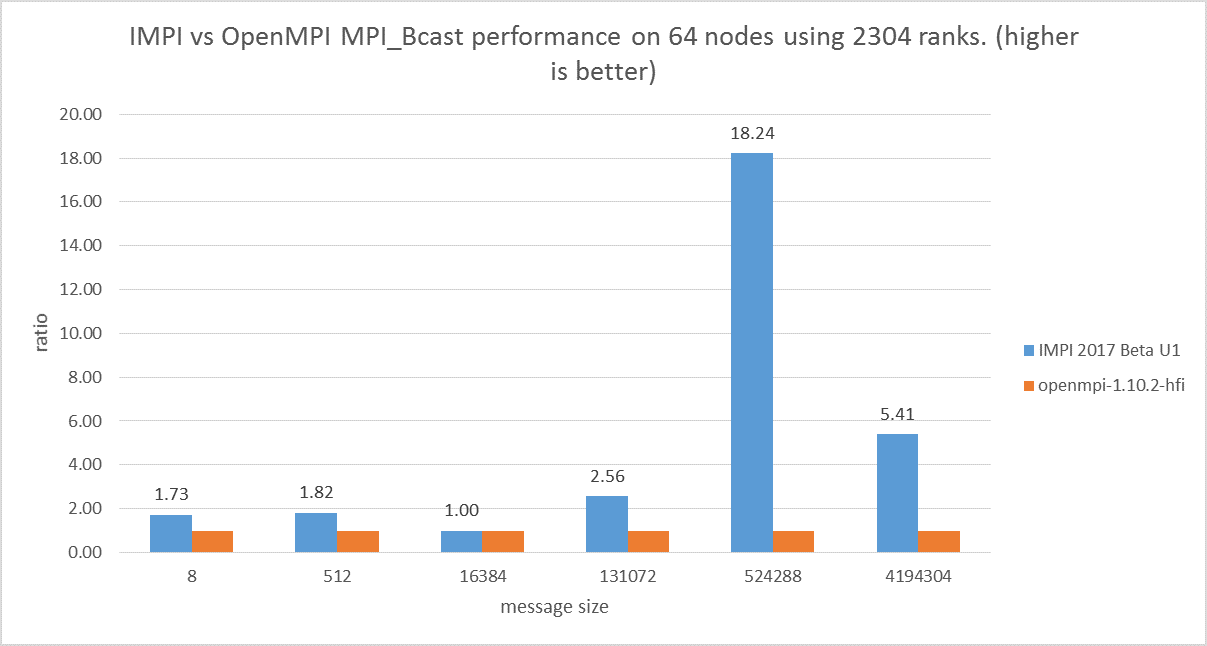
Figure 2: MPI Broadcast performance relative to message size (Results courtesy the Intel MPI team)
Reduction performance and scalability
Reduction performance becomes ever more important as the number of computational ranks in the job increases. In particular, data scientists can decrease the amount of data per computational node to decrease the time it takes each node to perform a training step as discussed in the second article in this series. However, the MPI_Reduce() library call that is used to perform the reduction can become the rate limiting step as the number of computational nodes (e.g. MPI ranks) increases.
The Intel MPI team has tuned the reduction operations to deliver greater performance than the OpenMPI MPI_Reduce() implementation. Reductions are particularly tricky to optimize as they tend to be latency rather than bandwidth limited and utilize small messages. For example, machine learning (and many other HPC applications) tend to perform arithmetic reductions using double-precision values to preserve as much precision as possible. This means that potentially large numbers of 8-byte messages can flood the communications fabric.
Not much can be done about the speed-of-light latency limitations of the communications fabric. However, the Intel MPI library can pick among a variety of algorithms and tuned implementations depending on the network topology and processor architecture to reduce both the number messages transmitted and the software latency of the library itself. Shared memory in particular can be used on high-core count processors to ensure that only a single value needs to be transmitted from each node.
The following graph shows a 1.34x performance improvement when using the Intel MPI library as opposed to OpenMPI. For reduction limited applications, this translates to a significant time-to-model improvement simply by “dropping in” the Intel MPI library for MPICH compatible binaries (or simply recompile to transition from non-MPICH libraries like OpenMPI).
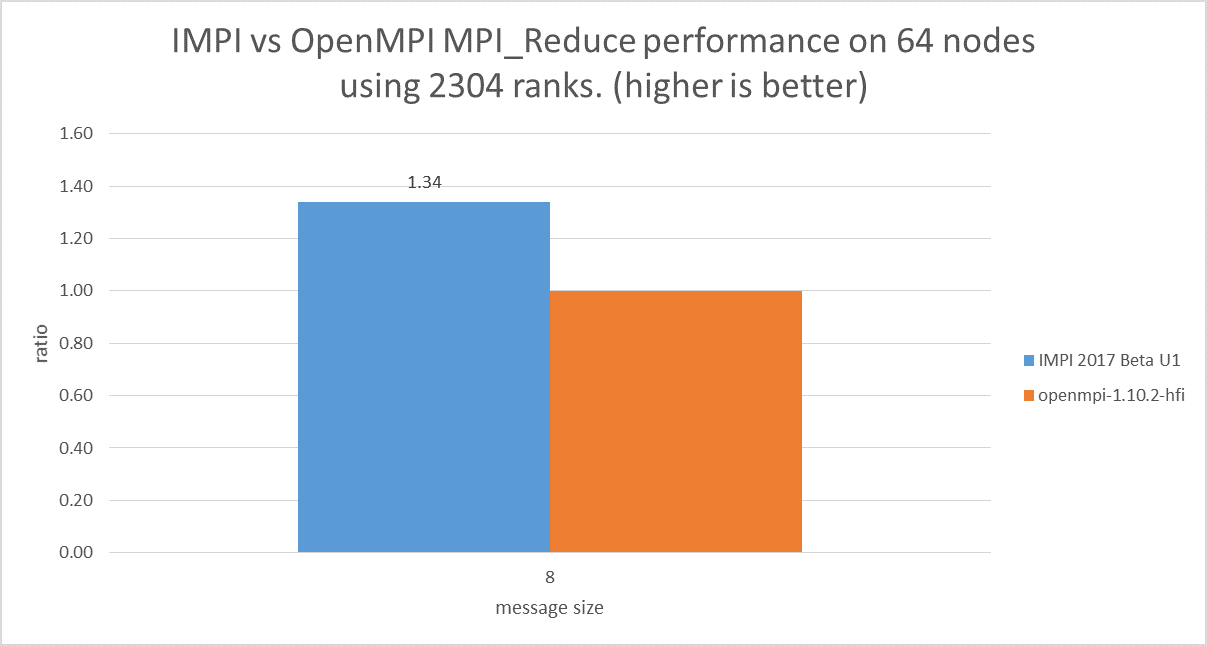
Figure 3: Reduction performance of Intel MPI relative to OpenMPI (Results courtesy the Intel MPI team)
Intel specific tuning and compatibility testing
The Intel MPI team has spent a significant amount of time tuning the Intel MPI library to different processor families plus network types and topologies.
Shared memory is particularly important on high core count processors as data can be shared between cores without the need for a copy operation. DMA mapped memory and RDMA (Remote Direct Memory Access) operations are also utilized to prevent excess data movement. Only when required are optimized memory copy operations are utilized depending on the processor uArch. This is the case with very small messages. Special support is also provided for the latest Intel Xeon Phi processor (codename Knights Landing) near and far memory. Near memory is close to the processor and resides in fast MCDRAM memory while far memory is further away from the processor that resides in conventional DDR4 memory.
MPI is a fundamental building block, which is why Intel follows a quarterly release cycle to ensure that customers have access to all the latest performance optimizations. To support this, the Intel MPI team runs aggressive regression tests to ensure that all configurations run correctly, quickly, and are conformant to the MPICH and ABI specifications. Regression test suites run nightly and weekly using a more comprehensive test suite.
MPI startup time
Running large scale Intel MPI applications means that close attention needs to be paid to the MPI_Init() routine. Running with many thousands of ranks means that infrastructure management operations can consume a large part of the MPI initialization time. In other words, the initialization of the MPI environment to provide all the ranks with a common, consistent environment must scale as well.
There are several factors which lead to the increased startup time. This includes extra communication over the PMI (Process Management Interface) before the fabric is available. In addition there are initial global- collective operations which may lead to high fabric load during the startup phase. The amount of messages passed across the fabric can increase dramatically as the MPI rank counts increase, thus causing long startup times at scale. Ensuring fast startup times is one of many reasons why Intel validated their MPI library to 340,000 MPI ranks. Succinctly new approaches and algorithms are required for even seemingly mundane tasks like starting large numbers of MPI tasks at scale.
Profiling and tuning
Intel provides a number of MPI profiling tools such as the Intel Trace Analyzer and Collector and the MPI Performance Snapshot tool. The latter is especially important for examining MPI behavior at scale as it lets developers understand performance when scaling out to thousands of ranks. The MPI Performance Snapshot tool combines lightweight statistics from the Intel MPI Library with OS and hardware-level counters to categorize applications including reports of MPI vs. OpenMP load imbalance, memory usage, and a break-down of MPI vs. OpenMP vs. serial time.
Summary
MPI offers programmers the ability to compute in distributed environments with high efficiency within a variety of environments from individual machines to organizational clusters and the world’s largest supercomputers. MPI also runs in the cloud and will certainly be available on exascale class supercomputers. The ability to run in most environments plus the availability of highly optimized libraries like the Intel MPI library that support efficient global broadcast and reduction operations makes MPI a natural distributed computing framework for machine- and deep-learning. Binary compatibility means that customers of the Intel MPI library will stay current with the latest optimizations and performance tuning by Intel, plus most customers will never exceed the validated scaling envelope.
For More Information
Volume 21 of the Intel magazine “The Parallel Universe” that is dedicated to MPI provides an excellent source of additional information for those interested in more details about the Intel MPI library.
References
[1] Chapter 7, “Deep-Learning Numerical Optimization”, High Performance Parallelism Pearls, volume 1, Morgan Kaufmann, 2014, ISBN 9780128021187.
[3] Very Deep Convolutional Networks for Large-Scale Image Recognition: http://arxiv.org/pdf/1409.1556.pdf


The Next Wave Of AI Is Even Bigger
Artificial intelligence is a broad area, covering diverse fields such as image recognition, natural language processing (NLP), and robotics. AI technologies are also developing at what sometimes seems like a frenetic pace, so that it can be difficult to keep up to speed with everything that is happening. Unsurprisingly, many …
Maybe Nvidia Should Buy VMware Instead Of Intel
It is hard to imagine how anyone could run Nvidia better than it is being run right now. Even if the $40 billion acquisition of Arm Holdings falls apart because of regulatory concerns, nothing about Nvidia’s current strategy has to change for it to become even more of a powerhouse …
HPE Creates Its Own AI Stack For Large Enterprises
While the hyperscalers have been running AI workloads against vast datasets in production for a decade and a half, many large enterprises have lots of data they think is relevant but they are not at all experiences with AI and the system requirements it has. That’s where companies like Hewlett …
Be the first to comment