
Any time a ranking of a technology is put together, that ranking is always called into question as to whether or not it is representative of reality. Rankings, such as the Top 500 list of the top supercomputers in the world, has been the subject of such debate with regards to the Linpack Fortran performance benchmark that is used to create the rankings and its relevance to the performance of actual workloads. When it comes to networking, the changes in the list in recent years are likely a better reflection of what is going on in high performance computing in its most general sense.
Over the past several years, the Linpack test has been run by various cloud and hyperscale companies to show off the performance of their clusters, and most of these systems do not use InfiniBand or proprietary interconnects to lash server nodes together, but rather Ethernet, which is by far the standard interconnect used by enterprises, telecommunications companies, cloud builders, and hyperscalers. The Linpack test is basically irrelevant to these customers (unless they are using their clusters for simulation and modeling as well as for other parallel workloads), but the clusters are absolutely real and the same issues that traditional HPC shops are wrestling with in terms of applying bandwidth and low latency to adapters and switches to squeeze more performance out of clusters are driving networking choices at these shops outside of traditional HPC.
So, ironically, the political and corporate motives that have driven companies that have thus far ignored the Top 500 test and have recently sought to have their clusters ranked is probably making the list a better reflection of the upper echelon of cluster computing, whether or not the systems are being used to what we think of as HPC. The rankings continue to demonstrate that InfiniBand and other interconnects have a place in distributed computing and set the stage for some hyperscalers and cloud builders to switch to InfiniBand and possibly other technologies as they create clusters that have special needs in terms of bandwidth and latency.
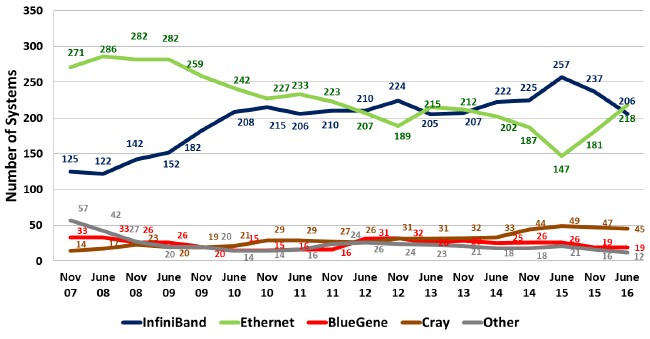
The trend lines in the Top 500 list over the past decade reflect this change. There has been a resurgence of Ethernet, as you can see in the chart below, but not so much because traditional HPC shops are moving away from InfiniBand and other interconnects like the “Aries” interconnect from Cray and the Omni-Path interconnect from Intel, but because non-traditional companies that deploy Ethernet are submitting test results to the Top 500 administrators so they can brag about the performance of their clusters. Because of this, Ethernet has once again surpassed InfiniBand as the most popular interconnect on the list with the June 2016 rankings.
Drilling down into the Top 500 data by sector and user class is illustrative and shows the marked contrast between in interconnect usage patterns among research, academic, and industry sectors as well as traditional HPC and other clusters that run the Linpack test for bragging rights.
As an aside. It is important to realize that the Top 500 list is a voluntary one, and does not include some of the largest traditional HPC systems in the world and also does not include many data analytics clusters in use by governments and hyperscalers that, had they run the Linpack test, would no doubt be ranked. For instance, the Facebook clusters based on its “Big Sur” CPU-GPU systems have a collective 40 petaflops of raw single-precision computing, but because the Tesla M40 GPUs that they employ only support single-precision math, they can’t run the Linpack test and yet they clearly constitute a distributed, capacity class supercomputer. Similarly Google has well above 1 million servers, with many of its clusters having 10,000 nodes and many having as many as 50,000 nodes. If Google decided to run Linpack on these systems in succession, all of them would rank in the top ten of the list, and some of them would rank as high as number two on the list but probably not beat the 93 petaflops Sunway TaihuLight system that China just fired up. But here is the thing: Google could put somewhere between 50 and 100 petascale-class machines on the list if it was so inclined. This would skew the demographics of the Top 500 list, since Google only uses Ethernet for its interconnects. Now think about what happens if Amazon, Microsoft, Facebook, Baidu, Tencent, and Alibaba all did the same thing.
Only the most powerful HPC systems, using InfiniBand, Omni-Path, Aries, and high-speed Ethernet would stay on the list. This, in our estimation, would probably be a more accurate ranking of “high performance distributed computing” and we think maybe there ought to be a Top 2000 list that ranks machines in some other way besides Linpack (but still including Linpack). Maybe by cluster size alone in terms of peak theoretical integer and floating point performance with a node count floor of 1,000 or 2,000 machines. You could then group machines by whether they are running MPI, Hadoop, Spark, Mesos, or some other distributed computing framework.
That is an issue for another day. We were just making a point that this comes down to definitions.
What is clear from the most recent Top 500 list is that interconnect choices depend on what kind of organization is running the system and what kind of workloads they are actually running in production.
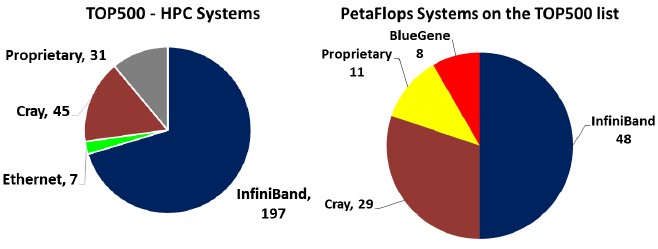
If you carve out the machines used by telcos, hyperscalers, cloud builders, and others and look at traditional HPC machines only, then InfiniBand is by far the most popular interconnect on the list, with 197 machines out of 280 machines. Proprietary interconnects (including IBM’s BlueGene, Fujitsu’s Tofu, and SGI’s NUMALink switching) account for 31 machines and several generations of Cray interconnects (mostly its “Gemini” XT and Aries XC networks) comprise the other 83 machines on the June Top 500 list. BlueGene systems will eventually fall off the list since IBM has stopped investing in BlueGene systems, and over a much longer haul, Cray will adopt Omni-Path 2 as its core interconnects and Gemini and Aries systems will be upgraded to this.
The distribution of networking types by industry segment is particularly interesting and no doubt correlates to what most of us expect:
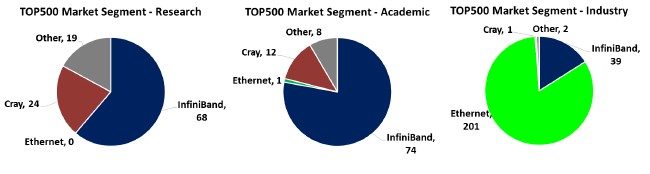
On the June 2016 list, InfiniBand dominates in the research and academic sectors, with Cray interconnects coming in a strong second and Ethernet basically being non-existent. If jump over to industrial users on the Top 500 list, InfiniBand is only on 39 of the 243 systems on this subset of the list and Ethernet, with 83 percent share, utterly dominates. In effect, we already have two very different lists encapsulated inside the Top 500 list.
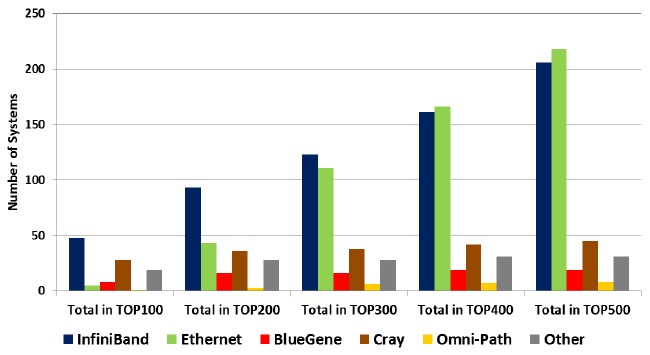
In general, whether you look at traditional HPC systems or the overall list, the larger the machine the more likely it is to be using InfiniBand, Cray, or another proprietary interconnect and the less likely it is using Ethernet. Take a look at this scatter bar chart that shows the number of machines running traditional HPC jobs as you expand from the Top 100 machines in increments of one hundred out to the full Top 500 list:
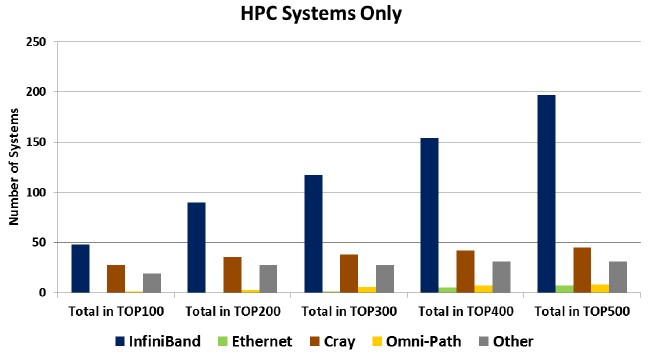
As you can see, the prevalence of InfiniBand among the traditional HPC clusters ranked by Linpack on the Top 500 list increases as you move from the most powerful systems at the top of the list to the wider list. This is another way of saying that other interconnects tend to be at the top of the list and have not been able to penetrate to the lower performance levels. We think this has more to do with the nature of the applications and deep-seated networking preferences on the wider part of the list. We also believe that, over time, Intel will be able to get traction with its Omni-Path networking, particularly once it has embedded Omni-Path controllers available for its current “Knights Landing” Xeon Phi processors and future “Skylake” Xeon E5 v5 processors. The question is whether Omni-Path will displace Ethernet or InfiniBand on the list. (There are those who would argue that Omni-Path is essentially a modified variant of InfiniBand.)
What we can say for sure is that Intel wants to radically increase its share of networking in the datacenter, and it is starting with HPC shops and expanding out to machine learning and other distributed workloads. It is a reasonable guess that Intel will target existing InfiniBand shops, including its own True Scale InfiniBand users as well as those employing Switch-IB gear from Mellanox Technologies. It may be easier for Intel to sell against Ethernet than it can against InfiniBand, oddly enough, and the Ethernet target is certainly juicier at the bottom two-thirds of the list where Omni-Path could meet less resistance if organizations can get over their preference for Ethernet. Again, it comes down to applications and how easy it will be to port from Ethernet to Omni-Path. The easier and more transparent this is for applications, the more Ethernet can be displaced within large-scale clusters. We think that Mellanox will have a very aggressive technology roadmap for InfiniBand and will prove to be a tough contender as Intel pushes harder into HPC. Cray will continue to get its share with Aries and SGI with NUMAlink, too.
We know another thing for sure: All of this advancement of technology and competition will be good for customers, allowing them to scale out their clusters faster – and more affordably – than they might have been able to do otherwise.


Intel’s Datacenter Decline Not As Bad As Expected
Incoming chief executive officer and long-time Intel employee Pat Gelsinger is talking the helm of a chip company that has plenty of issues to sort out, but there is some good news as Intel reports its financial results for the fourth quarter of 2020 and Gelsinger gets ready to take …

At Long Last, HPC Officially Breaks The Exascale Barrier
Significant business and architectural changes can happen with 10X improvements, but the real milestones upon which we measure progress in computer science, whether it is for compute, storage, or networking, come at the 1,000X transitions. It has been nearly two decades since the “Roadrunner” hybrid Opteron-Cell was fired up at …

Cache Is King
The gap between the performance of processors, broadly defined, and the performance of DRAM main memory, also broadly defined, has been an issue for at least three decades when the gap really started to open up. And giving absolute credit where credit is due, the hardware and software engineers that …
Be the first to comment