

As supercomputers expand in terms of processing, storage, and network capabilities, the size and scope of simulations is also expanding outward. While this is great news for scientific progress, this naturally creates some new bottlenecks, particularly on the analysis and visualization fronts.
Historically, most large-scale simulations would dump time step and other data at defined intervals onto disk for post-processing and visualization, but as the petabyte scale of that process adds more weight, that is becoming less practical. Further, for those who know what they want to find in that data, using an in situ approach to finding the answer is becoming more common.
In situ analysis does some critical computing on the fly while the simulation is running (versus being thrown out to disk and picked through later). While this might sound like the natural thing to do, especially to avoid the big drag on file I/O with so much read and write activity, in situ analysis on HPC systems still isn’t the norm. As Kitware’s Andrew Bauer tells The Next Platform, there are several reasons why there is a lag in adoption of in situ approaches to analysis, from codes that are hard to cook this kind of intelligence into to the biggest barrier, which is understanding what the important elements of the data are so only those can be captured for on-the-fly analysis and re-analysis from disk.
In some cases, for example, in determining the lift on an airplane wing, researchers know what data they’re looking for in the compute process and can relatively easily work that into an in situ analysis definition of parameters as the simulation is being set up. But for truly efficient in situ analysis, there needs to be more sophisticated feature extraction, which will help centers that know there’s something important going on as their simulation runs, but don’t know what, when, or where it is. This is the next step in the evolution of in situ analysis and it’s one that will need to keep improving to keep up with ever-growing machine sizes, Bauer says.
“Moving data around is expensive in terms of energy, and disks and I/O fabric are also expensive, as is having separate computational infrastructure for performing visualization and analysis…having means to interact with a simulation, to gain quick feedback on how a change in an input parameter will affect the simulation, or perform on-the-fly debugging, is a significant capability that can, in the long run, result in more efficient use of computational resources.”
The big challenge for in situ analysis is that in some cases, centers don’t know what they’re looking for when they’re running a simulation, which is where feature extraction helps. But Bauer says even still, HPC systems are generating so much data that they’re not writing the full amount of it to disk for later analysis because of resource constraints. By adopting in situ analysis into the workflow, however, he says it is possible to have more access to data in memory (without the extensive reads/writers) so finding what that needle might be in the haystack is a bit easier—something that is more important as scale mounts.
“In situ is not as common as it could or should be given the efficiency it can create,” Bauer explains. “Most codes don’t have the capability for this built in and while there has been research for codes that have instrumented their own specific in situ output, it’s specific to that code only.”
Taking an in situ approach to analysis of simulation data is even more important for HPC because one of the most pressing bottlenecks cited for the pre-exascale and future exascale systems is file I/O. There have been workarounds for this presented in the storage subsystems and other parts of the stack, but since the application level details are so disparate, presenting a one-size-fits-all solution is a challenge. But according to Bauer, integrating an intelligent approach to analysis that doesn’t require massive reads and writes for later analysis and post-processing is a clear shot at increased efficiency.
As Bauer and team wrote in this paper on the future of in situ analysis in HPC, “An ongoing trend in HPC is to create an exponential increase of the computational throughput of the machine, but a comparatively much smaller increase in the bandwidth to the disk storage system. This has led to a very large disparity between the computation bandwidth and the storage bandwidth even today.”
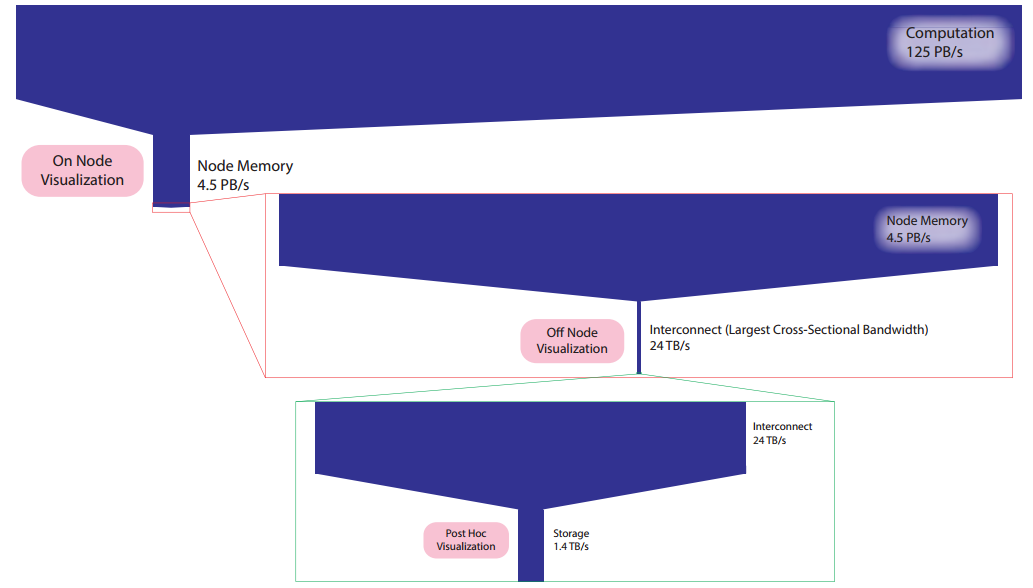
As seen above, there is a significant disparity on a machine like Titan and as that grows, Bauer says simulations can only write smaller portions of data generated from simulations. Further, with enough of a gap between the compute versus storage bandwidth, simulations might not be able to write out enough to allow adequate analysis later. As we’ve seen with future systems, this disparity is not going to change in systems, so a fresh approach with in situ analysis at the center can add to efficiency—at least for when is possible given the codes.
One might think too that the increased capability of systems might mean a better chance at integrating in situ analysis into existing workflows, especially when there is more memory on systems to handle some of the in-flight compute. But for Bauer, who has worked with teams at Argonne on the Mira supercomputer, as well as with the Titan system at Oak Ridge National Lab, this is a deceptive figure. “If you look at Mira, for instance, there are 256 MB of memory per MPI rank. In aggregate that seems huge since there are many nodes and cores, but you don’t get that much per MPI rank.” And for a machine like Titan, he says, it’s hard to get simulation and something like ParaView Catalyst to work together to reduce the memory used by the in situ tool.
While it’s not a perfect approach, especially for those who don’t already know exactly what they’re looking for during the simulation iterations, feature extraction and other intelligent features cooked into the on the fly analysis can continue to push efficiency on forthcoming machines.


The GPU Database Evolves Into An Analytics Platform
As the name of this publication suggests, we are system thinkers and we like to watch the evolution of a collection of tools into a platform. That’s the neat bit, when all the propellerheads have done the work on the components and the integration and when those tools can be …

Accelerating the Shift to Software Defined Visualization
Advances in visualization are essential for managing—and maximizing value from—the rising flood of data, the growing sophistication of simulation codes, the convergence of machine learning (ML) and simulation workloads, and the development of extreme-scale computers. Software-defined visualization (SDVis) has emerged as one of the most promising and practical ways to …

CPU, GPU Potential for Visualization and Irregular Code
Conventional wisdom says that choosing between a GPU versus CPU architecture for running scientific visualization workloads or irregular code is easy. GPUs have long been the go-to solution, although recent research shows how the status quo could be shifting. At SC 16 in Salt Lake City in a talk called …
Be the first to comment