

The supercomputing industry is as insatiable as it is dreamy. We have not even reached our ambitions of hitting the exascale level of performance in a single system by the end of this decade, and we are stretching our vision out to the far future and wondering how the capacity of our largest machines will scale by many orders of magnitude more.
Dreaming is the foundation of the technology industry, and supercomputing has always been where the most REM action takes place among the best and brightest minds in computing, storage, and networking – as it should be. But to attain the 100 exaflops level of performance that is possible within the next fifteen years, the supercomputing sector is going to have to do a lot of hard engineering and borrow more than a few technologies from the hyperscalers who are also, in their own unique ways, pushing the scale envelope.
This, among other themes, was the focus of a recent talk by Al Gara, chief architect for exascale computing at Intel, at the ISC16 supercomputing conference in Germany. Gara, who was one of the architects of IBM’s BlueGene family of massively parallel supercomputers before joining Intel, mapped out the scalability issues that the supercomputing industry faces as it tries to push performance ever higher. And the result of his detailed presentation was both optimistic in that he thought the industry, working collaboratively, could hit the 100 exaflops performance level by 2030 and somewhat pessimistic in that such a performance gain fifteen years from now – about 1,000X if you round generously – was nothing like the 50,000X we have seen in the past fifteen years.
“When I think about where we were fifteen years ago, and when we talk about where we were going to be today, we have come about 50,000 times more in terms of our Linpack numbers,” Gara explained. “It is pretty incredible, and it is obviously with a lot of risks that one projects another fifteen years. But I thought I would give it a try and give a sense of some of the challenges that we see and how things are going to scale as we go forward.”
A system is not just compute, of course, although we tend to focus on that because this is the easiest capacity to grasp about a system. So Gara walked through how various capacities of high-end supercomputers – general and specialized compute, memory capacity and bandwidth, interconnect fabric bisection bandwidth and injection rates, and power consumption – might scale in the next decade and a half.
Interestingly, Gara spent a lot of time talking about memory and fabrics, something that might seem peculiar coming from a chief architect at the world’s largest CPU chip manufacturer. But Intel not only has aspirations in both memory and fabrics as it seeks to expand its reach in supercomputing centers and all large-scale datacenters, and it also knows that memory and interconnects are the key to squeezing more performance out of the compute that Intel and others will bring to bear in the coming fifteen years.
The Memory Wall
Over the decades, the fundamental shift that has occurred in systems is that more and more elements of the system have been integrated onto the central processor and the remaining components that are in the system have been pulled closer and closer to the compute. The big advance that is making exascale computing possible is getting DRAM memory chips and very wide memory buses onto the same physical packaging as the CPU. Fujitsu was on the cutting edge with this last year, when it packaged its 32-core Sparc64-XIfx processor with two blocks of Hybrid Memory Cube 2 (HMC2) memory from Micron Technology, and Intel is using a derivative of HMC co-developed with Micron on its now shipping “Knights Landing” Xeon Phi 7200 series parallel X86 processors. Nvidia is using an alternative on-package and parallel memory technology called High Bandwidth Memory, or HBM, developed in conjunction with AMD and Samsung, on its new “Pascal” GP100 GPU coprocessors. AMD is using HBM2 memory on package with its “Polaris” GPUs and is rumored to be planning to use it on its future “Zen” Opteron CPU-GPU hybrids due in 2017 as well.
The transition away from DRAM linked to the CPU and to other kinds of higher bandwidth memory was already underway with GDDR5 frame buffer memory used on graphics coprocessors, as this chart illustrates, and importantly, shows that the industry is reversing a downward trend of the ratio between the aggregate Linpack flops ratings of the biggest machines on the Top 500 list and their memory bandwidth:
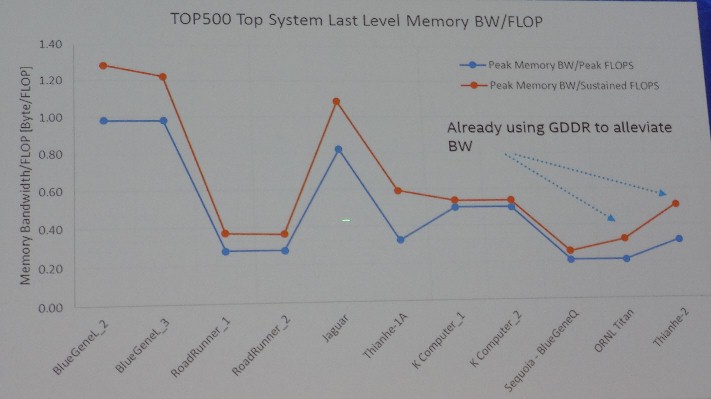
Gara also trotted out a chart he used in a presentation at the ISC15 supercomputing conference that talked about the shift away from DRAM DIMMs in systems to various kinds of high bandwidth memory (generally speaking and including both the HBM and HMC variants), which showed that this high bandwidth memory cost somewhere between 20 percent to 50 percent more than DRAM DIMMs commonly used in servers, but the cost per bandwidth was anywhere from 10X to 40X lower and that the power per bit was anywhere from one tenth to one half that of regular DRAM.
“I think that some of the directions that DRAM has been going have been enormously positive,” Gara said. “The ability to have in-package memory, which has a tremendous drop in power consumption per bit, but also really the key metric here if you want to look at performance is really the cost per bandwidth. If we can’t improve that we are not going to get very far. So that is really a key metric. But we have taken a big step with that with the high bandwidth memory. You can see that we have a 10X to 40X improvement just by going to high bandwidth memory and that is a step function in memory that is going to really help us to address the memory wall that we have been struggling with for so long.”
Fabric Weaving 101
The issue that supercomputer architects all face is that jacking up the bandwidth is relatively easy, but boosting the capacity of that high bandwidth memory is not.
“I think that we have a compelling bandwidth story through 2030, but really that slow capacity growth is what is stressing us,” Gara continued. “But this is not anything new. As a community, we have been saying for the last ten years at least that we need to get more performance out of the same capacity, and through software techniques and hardware advancements, we have always been stressing threading. And I think that will continue to be the case, and we are going to fundamentally need to get more performance out of the same capacity or we are not going to be able to scale. That is the fundamental thing that I see, and I don’t think that the new memory technologies will replace DRAM, but rather that they will be in the memory I/O space.”
A case in point is the “Aurora” supercomputer being built by Intel and Cray for the US Department of Energy’s Argonne National Laboratory, which is based on Intel’s future “Knights Hill” Xeon Phi processors slated for 2018, high bandwidth memory will be augmented by giant gobs of 3D XPoint memory that sits between the parallel file systems and the main memory in the cluster. These augmenting memories – and there will be others – will be necessary to keep increasingly parallel compute well fed with data to chew on. But make no mistake. Gara says that DRAM, as exemplified by the high bandwidth memory approach, is here to stay at the heart of clusters because it will offer the right mix of price, performance, capacity, and bandwidth to be the chunk of memory that sits next to the processor.
On the fabrics front, Gara thinks that the challenges that the industry faces are somewhat more severe than what we are confronting with memory capacity and memory bandwidth, and for supercomputers in particular, the key issues are that the scalability of some applications scales with bi-section bandwidth on fabrics and that the ratio of bi-section bandwidth to aggregate compute in supercomputers has been falling. These are tough trends to reckon, and complicating matters over the long haul in the next fifteen years, fabrics will have both cost and power barriers that will need to be dealt with.
Here is how Gara sees the situation: “From my perspective, fabrics are what supercomputing is about. If we don’t have a fabric we don’t really have a supercomputer, and right now fabrics are a cost problem. I would love to say it is a power problem – which it is not yet. If we could get the cost down it would become a power problem. But right now it is not there. So trying to address this is a fundamental challenge, and over time the bandwidth into the fabric relative to performance has continued to drop. I think that we are putting a lot of stress on applications by not being able to drive the cost down on that fabric.”
The biggest cost in fabric interconnects for supercomputers are the optical cables and transceivers that are used to make the long jumps between racks of gear, and Gara said that it optics were suddenly and magically a quarter of the price tomorrow, supercomputers would be built with three times the bandwidth because that would make the overall cost of the fabric the same.
“So that is a huge change that we could really force just by changing the cost of optics,” Gara said. This is a familiar argument that we have heard from the hyperscalers, with Facebook being the most vocal of the bunch and actually doing things to advance the technology such as adapting single-mode fiber used for long haul network links for use within datacenters.
The bandwidth that a supercomputer needs is enormous, and to make his point, Gara flashed up this chart, which shows the bandwidth required by the Internet over time compared to a single supercomputer circa 2012:
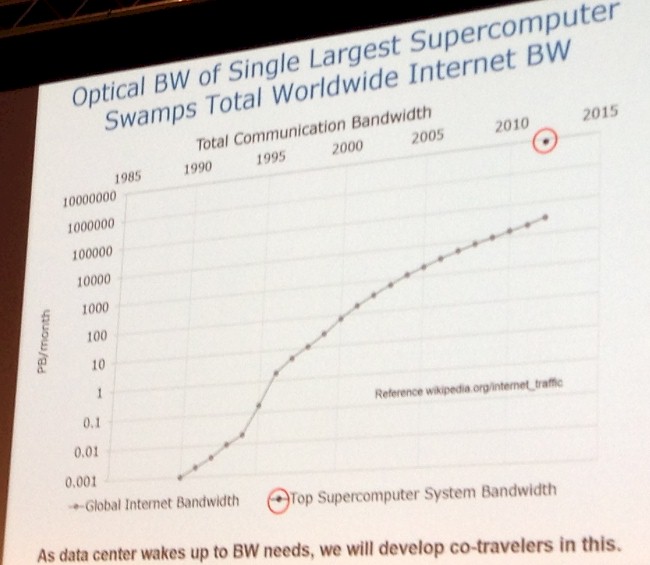
“And you see that we are driving a lot of optics,” Gara said with a laugh. “Now, the datacenter is also adopting optics, which is really good for us as a community since they are co-travelers on this optics push that we all need to do. But we really have a ferocious appetite for the amount of optics we need to put into our machines.” (When Gara says datacenter, he means hyperscaler as we use the term here at The Next Platform.)
Exactly how the optics play out in supercomputers over the coming years will have a big impact on the topology of systems, much as it has now. The dragonfly topology created by Cray for its Aries interconnect and a fat tree topology commonly used by InfiniBand networks already have a large number of ports linking devices (meaning they have some big fat pipes), and if the cost of big pipes gets cheaper still, then the topologies might have to switch to something like a torus interconnect (favored by IBM with BlueGene and Fujitsu with the Tofu interconnect used in the K supercomputer) that aggregates ports.
As an example, Gara said that if you could suddenly put 20X the bandwidth down a single fiber using wave division multiplexing and if the cost also went down by 20X, then we just basically put in the same number of fabric ports into the system with the same topology and have 20X the bandwidth. But what Gara predicts is that the cost of bandwidth on skinny pipes relative to fat pipes is going to rise, not fall. “This can become a pretty major factor and tends to push you into one topology versus another,” Gara said. “And we already find for very large systems with a dragonfly interconnect, which is a fairly distributed fabric, that when we look at the ports we have very few ports that are connected to other ports so that if we suddenly wanted to divide those, we can’t divide them very much. We are already near the limits of this.”
That said, Gara is predicting that the industry will take “a significant leap forward” with optics around 2020 or so in terms of the cost per gigabit with strong improvement through 2030. But, over the fifteen year span, the cost per gigabit will probably only improve on the order of 20X to 50X, compared to the 1,000X improvement in aggregate peak flops to the 100 exaflops level.
That leaves compute scaling as the remaining factor to be considered for a 100 exaflops system that could be delivered around 2030.
While Moore’s Law has not stopped, it has certainly slowed, and Gara showed a chart that compared how specialization on chips would be driven by the fact that I/O and energy bottlenecks are more intense than transistor scaling limits.

The HPC market is big enough, and growing faster than the rest of the industry as we have pointed out recently, and that means there will be funds to invest in research and development to advance compute. (As well as memory and fabrics.)
“In the future, there will be ways of doing computing that we did not conceive of five years ago that will really allow us to get to those big steps in performance to hit those exascale targets that ten years ago seemed impossible to hit,” Gara said. “We were all waving our hands, saying that we hoped we would get there, and we didn’t know how we were going to get there. We actually now have a pretty good idea about how to get there.”
Getting 100X more compute at the same power and cost will be a tough slog, however, and Gara conceded that “we don’t see any magic that we are going to be running at 100 THz.” The trick will be to find and exploit more concurrency than ever before in the hardware and the software, which has been the story of the past fifteen years. And, we will also probably have to raise the power cap on such systems, and Gara put a number on it, saying he expected an 80 megawatt power cap eventually, not the 20 megawatt cap that everyone is shooting for. And reaching that 80 megawatt power cap will require cutting the annual cost of a megawatt from $1 million to $500,000 so the energy to run the machine will cost no more than half the total budget for the 100 exaflops supercomputer.
A supercomputer of the 100 exaflops era could be a different kind of hybrid than we see today, with various kinds of specialized compute, possibly including quantum computing and neuromorphic computing, to augment the CPU, as far as Gara is concerned.
“The way I tend to look at this is that there are two paths,” he explained. “You can build a special-purpose device or you can augment traditional computing. And to me, the difference is really a power efficiency question. If you have got a device that when it is utilized that takes a lot more power than the rest of the compute, you sort have built a special purpose device that would not be very competitive as a general system because you would not want a system that would run at a tenth of the power when it is doing normal compute and only gets to use the full power when you are doing some special algorithm. My own feeling is that the way that this is going to play out is that these new techniques and new disruptive computing will come in as an augmentation to computing. And I think that is the most efficient way to get there, and there is going to need to be compromises to get there. And there are cultural and real technology challenges to put together very different technologies. But in the end, that is the way that I think we will go.”
The Path To 100 Exaflops In 2030
With these scaling trends pointed out, Gara proceeded to draw the lines between the “Sequoia” massively parallel BlueGene/Q system from 2012 to the 180 petaflops Aurora system due in 2018 and then in four-year increments beyond then. Take a look:
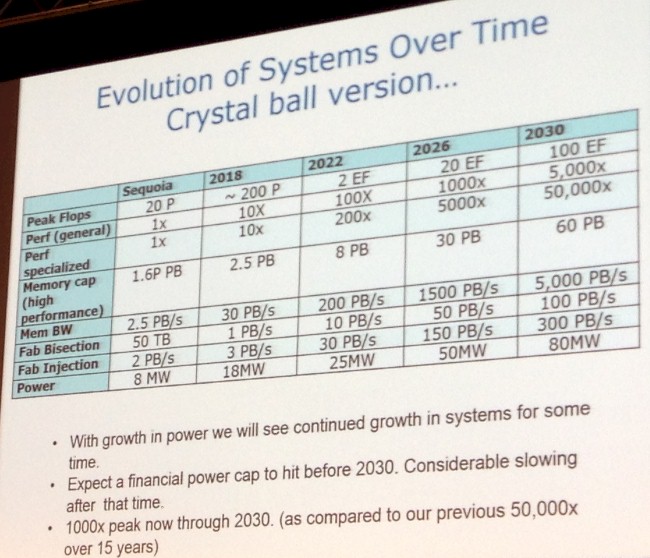
As you can see, the power consumption on these systems is rising, but not as fast as the performance of the systems is, which means it is feasible to think about such machines actually being built. You will also not that the specialized performance in these systems will scale over the next fifteen years at the rate that we have seen for general performance in the past fifteen years.
“I think there will be room for specialized performance to really scale up,” Gara summed up. “But again, it won’t be general purpose performance as we currently think about it. I also think that one of the challenges will be that memory capacity will not grow very quickly although with the memory bandwidth we will have the ability to scale that. The fabric will struggle a bit, but will probably be in the usable range assuming that we can get to power numbers of this scale. You can see that somewhere around 80 megawatts, the numbers taper off quite a bit. When all is said and done, when I map all of the scaling behaviors in, that 50,000X we got over the past fifteen years, I can maybe see us getting to 1,000X in the next fifteen years. That is not so bad even if it is not what we got before, and it still gets us to some really interesting, aggressive performance numbers that would be great to see and keep us all going for quite a while.”
Others, no doubt, have their own opinions, and we will be tracking them down.




Be the first to comment