

As the world is now aware, China is now home to the world’s most powerful supercomputer, toppling the previous reigning system, Tianhe-2, which is also located in the country.
In the wake of the news, we took an in-depth look at the architecture of the new Sunway TiahuLight machine, which will be useful background as we examine a few of the practical applications that have been ported to and are now running on the 10 million-core, 125 petaflop-capable supercomputer.
The sheer size and scale of the system is what initially grabbed headlines when we broke news about the system last week at the International Supercomputing Conference (full coverage listing of that event here). However, as details emerged, it became quickly apparent that was no stunt machine designed to garner headlines by gaming the Top 500 supercomputer benchmark. Rather, this system rolled out with full system specs backed by news that several real-world scientific applications were able to run on the machine, some of which could use well over 8 million cores—a stunning bit of news in a community where application scalability and real-world performance often is at dramatic odds with projected theoretical peak performance.

Despite the availability of millions of compute cores, sometimes boosted by accelerators, getting real-world codes to scale to make full, efficient use of such resources is ongoing, pressing challenge. In fact, this is one of the great questions as the impetus builds for exaflop-capable systems—even with such power, how many codes will be able to scale to advantage of that capability?
In addition to the Gordon Bell prize submissions (more on those below), Dr. Haohuan Fu, Deputy Director of NSCC-Wuxi, where the Sunway TaihuLight supercomputer is housed, shared details and performance results for some key applications running on the new machine in a session at ISC 16. The Next Platform was on hand to gather some insight from this talk and share a few slides.
Deep Learning Libraries, Large-Scale Neural Networks
Although supercomputing applications are still just out of reach of the influence of deep learning (something we expect will shift in the next couple of years) the TaihuLight supercomputer is being harnessed for some interesting work on deep neural networks. What is fascinating here is that currently, the inference side of such workloads can scale to many processors, but the training side is often scale-limited hardware and software-wise.
Fu described an ongoing project on the Sunway TaihuLight machine to develop an open source deep neural network library and make the appropriate architectural optimization for both high performance and efficiency on both the training and inference parts of deep learning workloads. “Based on this architecture, we can provide support for both single and double precision as well as fixed point,” he explains. The real challenge, he says, is to understand why most existing neural network libraries cannot benefit much from running at large scale and looking at the basic elements there to get better training results over a very large number of cores.
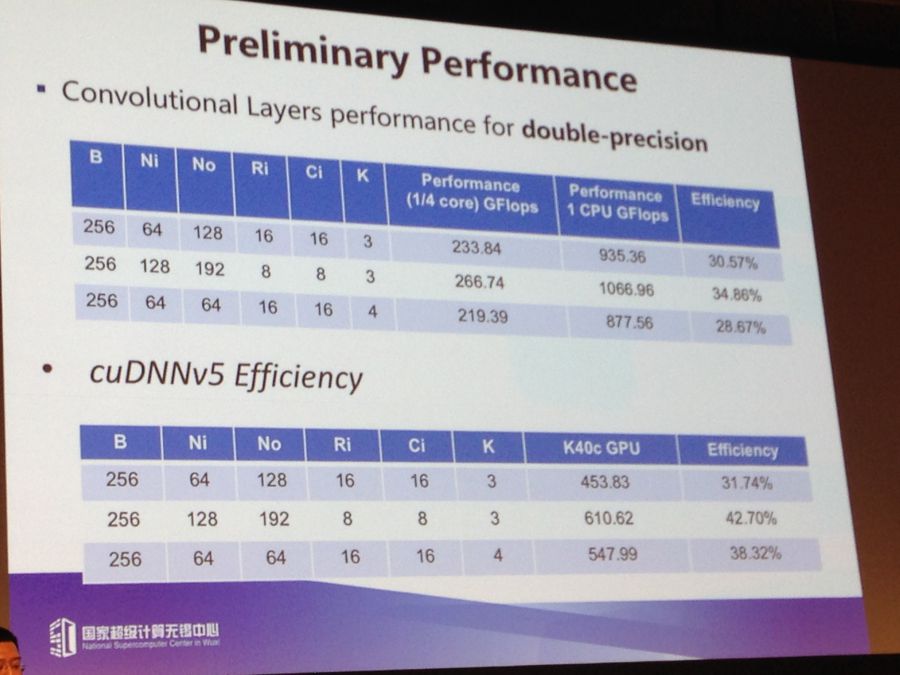
Above are some noteworthy preliminary performance results for convolutional layers for double-precision. The efficiency isn’t outstanding (around 30%A) but Fu says they’re working on the library to bolster it and get equal or better performance than the GPU—the standard thus far for training.
Weather and Atmospheric Codes
Earth systems modeling, weather forecasting, and atmospheric simulations are a few key application areas where scientists using TaihuLight are scaling to an incredible number of cores. The Chinese-developed CAM weather model has been focal point for teams to scale and represents some of the challenges inherent to exploiting a new architecture.
According to Fu, “there is a lot of complexity in the legacy codebase with over a half million lines of code. We can’t do all of this manually, so we’re working on the tools to port them since the legacy codes were not designed for multicore and not for a manycore architecture like the Sunway processor.” The tools they are working on are targeting the right level of parallelism, code sizes, and memory footprint, but ultimately, he says, this leads to one of the greatest challenges—finding the right talent that can understand the underlying physics and the computational and software problems. “Even the climate scientists don’t understand the code well, it’s been added to over the course of three decades.”

Scalability and performance results for the CAM model can be seen above comparing both use with the management core and sub-cores and with just the management core. For some kernels that are compute intensive, the team saw a speedup of between 10-22X, but for others that were memory-bound, the speedup wasn’t high, just 2-3X. The results here show speedup for the entire model and if there is any takeaway here, this is scaling to quite impressive heights for code that’s still in process on a new architecture—1.5 million cores.
Fu says to get to this point, they had to divide CAM into two parts; the dynamic part, which was rewritten in the last decade (they ported and optimized manually), and the CAM physics component, which was the difficult part. “We’re relying on transformation tools here to expose the right level of parallelism and code sizes for the 260 cores on this architecture. We also developed our own memory footprint analysis tool for this part.”
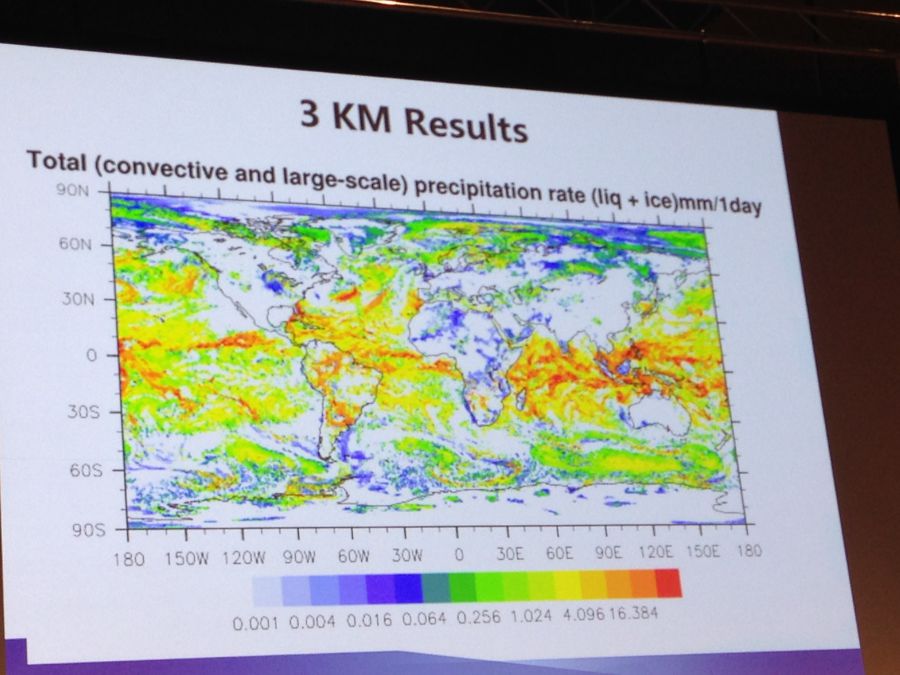
Another earth systems application, a high-res atmospheric model is showing good results as well. This is an experimental project that differs from the porting and optimization requirements of the legacy code above. Here the team is taking a hardware and software co-design approach and applying a loosely coupled scheme to the scalable model. They have run experiments for 10 to 3 kilometer resolution—an impressive feat when one considers the current scalability and resolution capabilities for leading centers like ECMWF, among others.
In the example above, the team was able to use the entire system as was during this run—38 cabinets, which is still well over 8 million cores. Fu says he expects that when they continue research with this code they will be able to use the full machine—over 10 million cores.
Gordon Bell Submissions
The following slide highlights the five applications that were submitted with the three accepted submissions highlighted. The winners of this award will be announced in November, but given the breadth of systems on the Top 500 now and their core counts, it is unlikely any will scale beyond 8 million cores since, well, none of them have even close to that many to begin with (the #2 machine, Tianhe-2, “only” has a tick over 3 million).

In terms of the code work for the Sunway TaihuLight machine, the unique architecture obviously creates some barriers. Fu says they have a parallel OS environment and are using their own homegrown file system (Sunway GFS) which many guess is based on Lustre. The machine will support C, C++ and Fortran compilers and support for all basic software libraries. Fu says they are using a combination of OpenMP, OpenACC and MPI, but for many of the early stage applications demonstrated here, they are using a hybrid mode that balances OpenACC and MPI (for the different compute groups, one MPI process is allocated and OpenACC is used to execute parallel threads).
As an interesting final side note, this government-funded supercomputer is set to support the needs of manufacturing operations in the region, which includes large cities nearby, including Shanghai. One can expect that many of the solvers and other simulation workflows will go to support the regions automotive and other industries, which explains why the $270 million funding for the supercomputer came from a collection of sources, including the province and cities near the center.


Why Did China Keep Its Exascale Supercomputers Quiet?
There are no greater bragging rights in supercomputing than those that come with top ten listing on the bi-annual list of the world’s most powerful systems – the Top500. And there are no countries more inclined to throw themselves (and billions) into that competition this decade than the U.S. and …

Real-World HPC Gets the Benchmark It Deserves
While nothing can beat the notoriety of the long-standing LINPACK benchmark, the metric by which supercomputer performance is gauged, there is ample room for a more practical measure. It might not garner the same mainstream headlines as the Top 500 list of the world’s largest systems, but a new benchmark …

A First Peek At China’s Sunway Exascale Supercomputer
The trade war between the United States and China is not just a top-down political and economic one, but also a technical one. And one could argue that the Sunway TaihuLight supercomputer that was unveiled in June 2016 with mostly indigenous technology rather than chippery that was Made in America …
Look like China use the supercomputer for the benefit of mankind whereas US supercomputer is used to create killing machines that are more destructive and efficient in killing human. Look at the killer drones created by US. They can kill Chinese from US soil but China killer drones could not do the same thing. Yet US accused China the other way around in the creation of super efficient killing machines by banning the sales of chips to the Chinese.