

Nvidia wants for its latest “Pascal” GP100 generation of GPUs to be broadly adopted in the market, not just used in capability-class supercomputers that push the limits of performance for traditional HPC workloads as well as for emerging machine learning systems. And to accomplish this, Nvidia needs to put Pascal GPUs into a number of distinct devices that fit into different system form factors and offer various capabilities at multiple price points.
At the International Supercomputing Conference in Frankfurt, Germany, Nvidia is therefore taking the wraps off two new Tesla accelerators based on the Pascal GPUs that plug into systems using standard PCI-Express peripheral slots and that do not support the NVLink interconnect that Nvidia has created to be able to tightly couple the earlier Tesla P100 family of cards together and to link them as tightly with IBM’s updated Power8 processor, which also supports the NVLink protocol natively. The goal is to allow HPC clusters to use these for deep learning workloads, among others. The PCI-Express versions of the P100 cards (which do not have separate names to show they are distinct from the variant of Tesla that does support NVLink, which makes it tough to talk about them) also run at a slightly lower clock speed and therefore have a bit lower performance but also burn less juice and emit less heat.
The PCI versions of the Pascal Tesla cards also come with lower prices and will therefore be appealing to customers who do not need NVLink but who do want to increase the amount of floating point work they can get done per dollar and per watt. The prices are, as best we can tell, dropping faster than the performance, which means that the PCI-Express variants of the P100 cards are perhaps going to give the best bang for the buck in the current Tesla lineup – at least at list prices.
While Nvidia has told us that it is going to be selling “Kepler” and “Maxwell” family Tesla accelerators for the foreseeable future, this is as much due to the fact that supplies for the Pascal products are going to be fairly limited until early next year. Because the Pascal products are understandably ramping slowly – these are complex products that employ a number of new chip manufacturing and packaging techniques – that means the Pascals are not putting as much price pressure on the earlier Tesla cards as they might otherwise. At the same time, however, Intel is starting to ramp up production of its “Knights Landing” Xeon Phi processors and will eventually put a PCI-based accelerator into the field, too, and that competition does put some pressure on Nvidia’s Tesla lineup, so the company cannot let its products get out of line with the alternatives for massively parallel workloads, whether they are traditional HPC simulation and modeling jobs or emerging deep learning ones. The Tesla business is still growing fast and is the most profitable part of Nvidia’s business, so as far as we can tell it is striking the right balance between supply of three generations of products, demand from customers, and competitive pressures. The pressure is mounting as the Knights Landing chips come to market in volume, and will rise further when Intel brings out its hybrid Xeon chip that mixes Broadwell Xeon cores and FPGA accelerators in a single package. The great thing for customers is that they have options, and ones that are offering increasingly better bang for the buck.
The Feeds And Speeds
The variant of the Pascal GP100 that is being used in the two new PCI-Express accelerator cards in the Tesla family have the same number of cores as the one used in the version of the P100 card that supports NVLink that was announced back in April at the GPU Technology Conference. The Pascal GP100 GPU has 60 streaming multiprocessors, or SMs in the Nvidia lingo, but for chip yield reasons, only 56 of them are fired up to do work. The GP100 has 3,584 CUDA cores for supporting half precision and single precision floating point math, and 1,792 FP64 64-bit floating point units next to them to support double-precision math. The GP100 used in the NVLink-enabled card runs at 1.33 GHz with a GPU Boost speed of 1.48 GHz, and that yields a peak performance of 5.3 teraflops at double precision, 10.6 teraflops at single precision, and 21.2 teraflops at half precision. (The half is useful for deep learning, signal processing, and certain other workloads where having more data to chew on is more important than having data with higher resolution.)
The PCI-Express variants of the Pascal P100 Tesla cards plug into a x16 slot, like any other graphics card or accelerator does, and Ian Buck, vice president of accelerated computing at Nvidia, tells The Next Platform that the PCI version of the Pascal accelerator is explicitly designed to go into any system that currently supports the top-end Kepler K80 accelerator, which has two Kepler GK210B GPUs on a single card, or the Maxwell M40, which has a single GM200 GPU on a card. The K80 card is rated at 300 watts, while the M40 is rated at 250 watts. Interestingly, the K80 has decent double precision performance but does not support FP16 16-bit half precision math, which is something that those running deep learning sometimes want; the M40 has a smidgen of double precision – not enough to make a difference – and does not support FP16, either.

The Pascal GPU also has the page migration engine that is new with Pascal, which is a page faulting mechanism that automatically keeps the unified memory coherent across the CPUs and GPUs in the system node without programmers having to do any synchronization of data across those elements manually; this page migration engine works over PCI-Express and NVLink connections, and Nvidia could have restricted it to NVLink if it wanted to drive more high-end sales.
In many ways, provided the price is right, the PCI-Express version of the P100 will be the best fit for many customers, we think, particularly who have to support a diversity of workloads and whose applications do not require such strong scaling inside of a node. Organizations that are only running one kind of job – traditional HPC or deep learning – have an easier time choosing accelerators, and they can use a more general purpose GPU accelerator like the P100 instead of a K80 or an M40, which have their limitations as we point out above.
Nvidia could have probably cut back on the number of SMs and therefore CUDA cores and FP64 cores supported in the PCI-Express versions of the Pascal Tesla cards to provide a differentiated product, but it looks like yields are good enough that it doesn’t have to do this. In fact, we expect that over time, Nvidia will do a kicker to the Pascal where all 60 of the SMs are fired up and be able to boost performance by 7 percent or so, provided that the heat increase can be tolerated, of course. This may not be the case with the 300 watt NVLink-capable Pascal Tesla part, but the two Pascal Tesla cards that plug into PCI-Express slots are rated at a maximum of 250 watts thanks to having their base clock speeds slowed down to 1.13 GHz and their GPUBoost speed dropped down to 1.3 GHz. This cuts back the floating point performance on the PCI-Express variants a little bit – 4.7 teraflops DP, 9.3 teraflops SP, and 18.7 teraflops HP – but the price drops quite a bit.
We conjectured back in April that Nvidia could put out a dual-CPU Pascal Tesla card, call it a theoretical P80, that might have GDDR5 memory instead of the High Bandwidth Memory 2 on-package, stacked memory used in the original Pascal Tesla P100 card. This did not happen, and it probably will never happen now that Nvidia has announced a version of the Pascal PCI-Express card that has 12 GB of HBM2 memory and supports 540 GB/sec of memory bandwidth. (Why this part runs at 250 watts like the card with 16 GB is not clear, but 12 GB should run cooler than 16 GB we would think.) This bandwidth on the skinnier card is not as high as in the top-end Pascal cards that have 16 GB of HBM2 memory and that deliver 720 GB/sec of bandwidth, but it is a lot higher than the 288 GB/sec of memory bandwidth delivered on the Tesla M40 card, which has 24 GB of GDDR5 frame buffer memory for storing algorithm data, and also better than the 240 GB/sec per GPU on the dual-GPU K80 card, which has 12 GB of GDDR5 memory per GPU on the card.
Here is how the feeds and speeds of the past three generations of Tesla cards stack up:
Picking out the right Tesla accelerator for one – or more – workloads is a tricky business indeed, and with Nvidia not supplying list prices, it gets tricky. Buck says that the 12 GB version of the PCI-Express variant of the Pascal P100 card will cost about the same as the Tesla K80 card. If you look at pricing from Colfax International, it is charging around $3,420 for a K40 card, $4,630 for a K80 card, and $4,660 for an M40 card. (We think Facebook, which is a big adopter of the M40 in its “Big Sur” machine learning cluster, which measures over 40 petaflops presumably at half precision, gets a much lower price on the M40 than Colfax is showing because of the volumes it buys. Interestingly, because the M40 does not have DP math, it cannot run the Linpack Fortran benchmark test, and it therefore cannot be ranked on the Top 500 list of supercomputers.)
For the sake of argument, let’s say that the P100 card in the PCI-Express form factor with 12 GB costs $5,000 and burns 235 watts and the one with 16 GB of memory costs $5,500 and burns 250 watts. As we tore apart the pricing on the DGX-1 server made by Nvidia, which it announced in April, we reckoned that the P100 with NVLink and made to snap directly onto the motherboards of systems cost $10,500. If you do the math, and compare it to the K40, K80, and M40, then the P100s are the better deal. If you look at it on a performance per watt basis, the P100 PCI-Express cards are an even better deal.
Perhaps more importantly, with the Pascal GPUs, the cost of a SP and DP operation are back in alignment, with SP costing half as much as DP, as it should be. If our estimated numbers are in the right ballpark, then a teraflops of SP performance on the smaller P100 part with 12 GB of memory is about the same as on the K80 but a teraflops of DP costs about 30 percent less. And, you can do half precision on the P100 PCI-Express card if you want, which you cannot do on the K80 or the M40. The premium that Nvidia is charging for the NVLink and the on-board packaging is steep, but for deep learning and HPC workloads where strong scaling in the node is important, this premium is justified. Look at what it costs for a system employing CPUs and SMP or NUMA clustering.
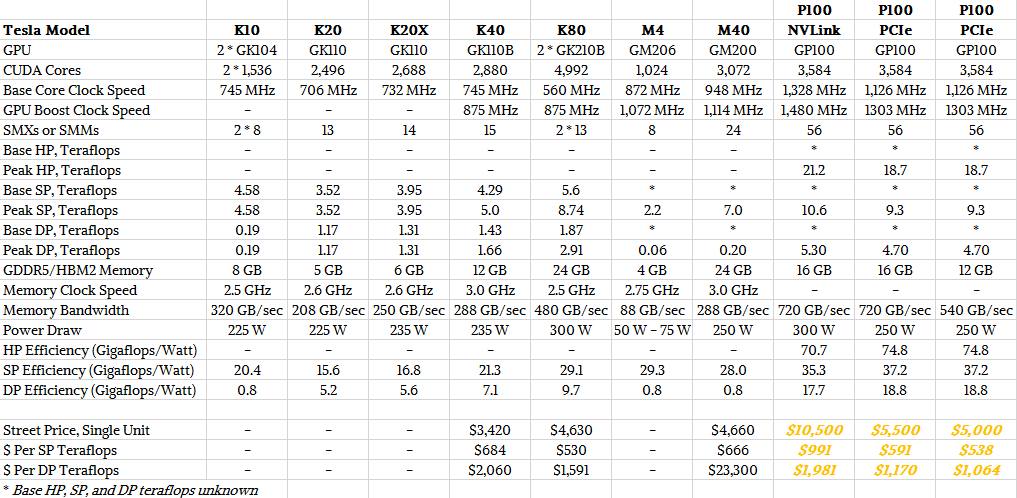
You can do scaling within a node without resorting to NVLink, by the way. And Nvidia has done the tests to show how the PCI-Express P100s stack up against a pair of Intel Xeon CPUs and K80 accelerators. As you can see from the chart below, the scaling factors depend in part on the applications:
In this chart, NAMD and VASP are molecular dynamics simulation applications, and AMBER is another tuned for life sciences in particular. MILC is a quantum chromodynamics application for simulating subatomic particles. HOOMD Blue is a particle simulator that kind of sits between them on the cosmological scale, and Caffe/AlexNet is a neural network for image recognition.
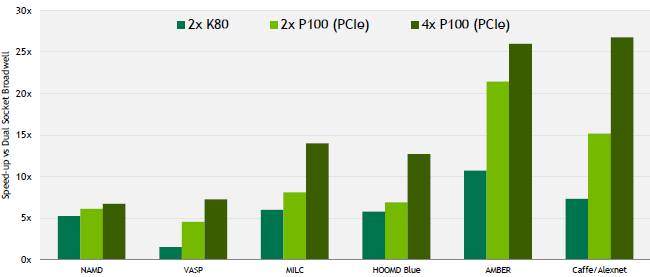
Buck pulled out another chart that showed how CPUs and P100 GPUs in the PCI-Express form factor scaled as the CPU count was increased in the cluster and GPU count was increased within a node. Take a look:

The chart above counts two-socket nodes using 12-core “Haswell” Xeon E5-2680 v3 processors. If you wanted to be absolutely fair, these tests should be moved to current “Broadwell” Xeon E5s and perhaps to top-bin parts with 22 cores in a socket. But you can see Nvidia’s point that one node with eight GPUs does a lot more work than 32 nodes with just CPUs, and even moving to the top-bin parts might only make 32 sockets do the work of one fat GPU node on the AlexNet workload. The scaling on CPU clusters with VASP is considerably better on the CPUs than is AlexNet, but it still only takes about six GPUs to meet the performance of 32 two-socket servers on VASP. You have to do the math on system configurations and running costs, as well as any application tuning, to decide which platform to pick, of course.
Buck’s argument is not just that you get more performance out of GPU accelerated systems, but that the GPU systems take up a lot less space to run workloads like VASP and AlexNet, that more of the budget goes towards compute, and that the absolute budget for a given level of performance is lower, too.
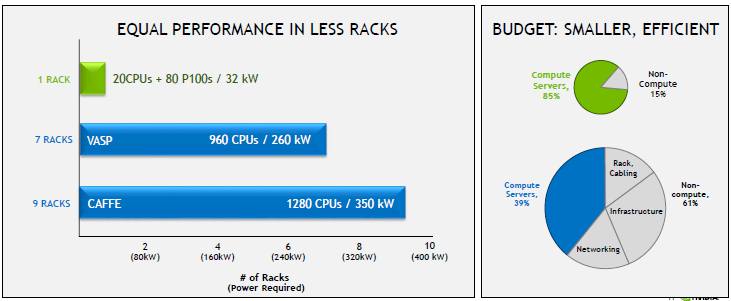
“One rack of systems accelerated with Pascal P100s has the equivalent performance of seven racks of CPU systems running VASP and nine racks of CPU systems running AlexNet,” says Buck. “You are actually spending less money, and up to 85 percent of your budget is spent for compute, with only 15 percent spent on racks and cabling and networking, simply because you have fewer nodes. We have a lot of use cases with specific numbers, but we can typically reduce the budget by half for the same performance. And it is really because we have all of the applications now. We have nine of the top ten HPC applications, and 70 percent of the top 50 HPC applications. So there is really no HPC center out there that can’t be running an application that is not GPU accelerated and that would not be more economical. People don’t often like to talk about the budgets and the math, but the reality is everybody is operating on some constrained budget at some point.”
The PCI-Express variants of the Tesla P100 cards are beginning production now and are expected to ship in volume in the fourth quarter of this year, with Cray, Dell, Hewlett-Packard Enterprise, and IBM being at the point of the spear for pushing them into the market.

Nvidia’s “Lovelace” GPU Enters The Datacenter Through The Metaverse
Like everyone else on planet Earth, we were expecting for the next generation of graphics cards based on the “Ada Lovelace” architecture to be announced at the GTC fall 2022 conference this week, but we did not expect for the company to deliver a passively cooled, datacenter server friendly variant …

The Eternal Battle Between InfiniBand And Ethernet In HPC
It is always good to have options when it comes to optimizing systems because not all software behaves the same way and not all institutions have the same budgets to try to run their simulations and models on HPC clusters. For this reason, we have seen a variety of interconnects …

Amazon Gives Anthropic $2.75 Billion So It Can Spend It On AWS XPUs
If Microsoft has the half of OpenAI that didn’t leave, then Amazon and its Amazon Web Services cloud division needs the half of OpenAI that did leave – meaning Anthropic. And that means Amazon needs to pony up a lot more money than Google, which has also invested in Anthropic …
Be the first to comment