

The datacenter is going through tremendous change, and many long-held assumptions are now being called into question. Even the basic process of separating data onto a separate storage area network, growing it, and pulling it across the network and processing it, is no longer necessarily the best way to handle data. The separation between production and analytics, which has evolved into an art form, is also breaking down because it takes a day or longer to get operational data into analytic systems.
As a backdrop to all of these technology changes, organizations say they need more agility. The ability to quickly take advantage of idle resources and put workloads on it, whether you call it a cloud architecture or not, is what is needed inside on-premise datacenters. In many cases, companies also want to extend their data out to public clouds. This need for agility requires companies to have analytics available when they are “in the moment” and can impact the business. This means that analytics is not merely a reporting function; for instance, instead of using analytics to understand what the exposure to fraud is at a bank, banks could use real-time analytics to decline a transaction because it is potentially fraudulent and could be detected before the transaction. Or it might mean using analytics to understand with greater context why a customer is on a web site and what the customer is doing, so the right products can be recommended to boost sales and improve customer experience. There are a wide variety of use cases that showcase the value of turning analytics into actions.
Underneath that, you have the agility of containers and the flexibility they offer to individual developers and analysts who can quickly develop or change applications and not be locked into very brittle structures; by looking at the end-to-end cycle of data-driven applications, you can see that they are all part of that objective.
Most companies that are using Apache Hadoop are deploying multiple clusters. The key factor driving that practice is that the majority of Hadoop vendors do not have multi-tenancy. They do not features such as logical volumes and disparate workload management. They also can’t easily mix real-time database operations with other constructs, which results in setting up separate clusters such as one for NoSQL and a separate one for Kafka.
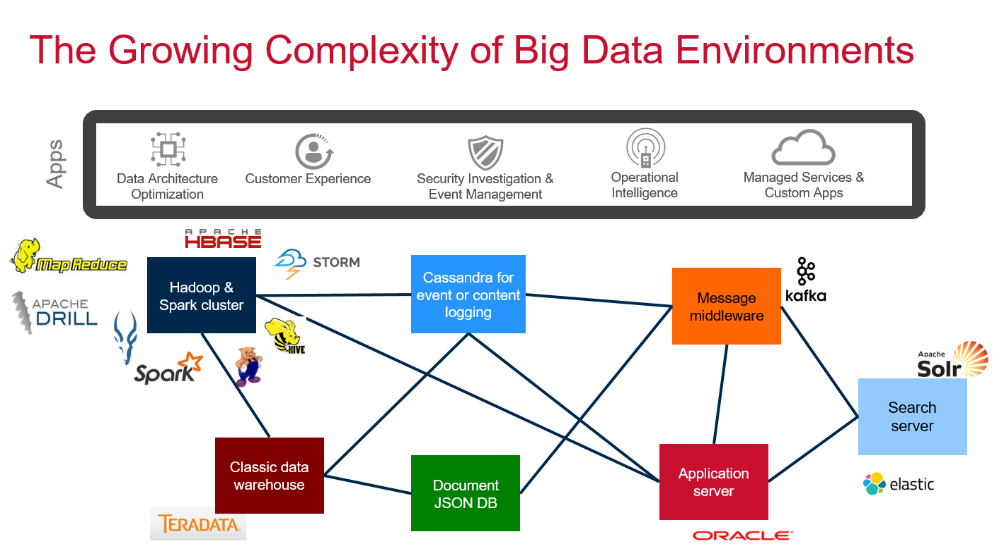
All of the convergence that is happening in the datacenter is really interesting in that it is redefining what is possible. However, we think that there are a lot of companies gaining experience with their Hadoop cluster and with big data, but they’re locking themselves in to a certain worldview that is limiting what is possible.
One of the ways that people lock themselves into a flawed way of thinking is that they start with the application first—we are trained to think this way. What is the application? What questions does it ask? What business functions does it address? Once you answer those questions, you would typically figure out how the data has to be properly massaged and set up to service those applications. So that data ends up being this specialized cube or schema that works on an application basis, but when you start to look across every application and business function, you end up with all of these different silos of data, and you have a massive ETL processing and dependency flowing back and forth. If you take a step further back, it takes days before data can arrive at a particular spot.
The simplification that is going on with convergence can be game changing due to the collapse of all of these different silos into one, and the elimination of those separate steps that require time and introduce delays. This simplification is transformational.
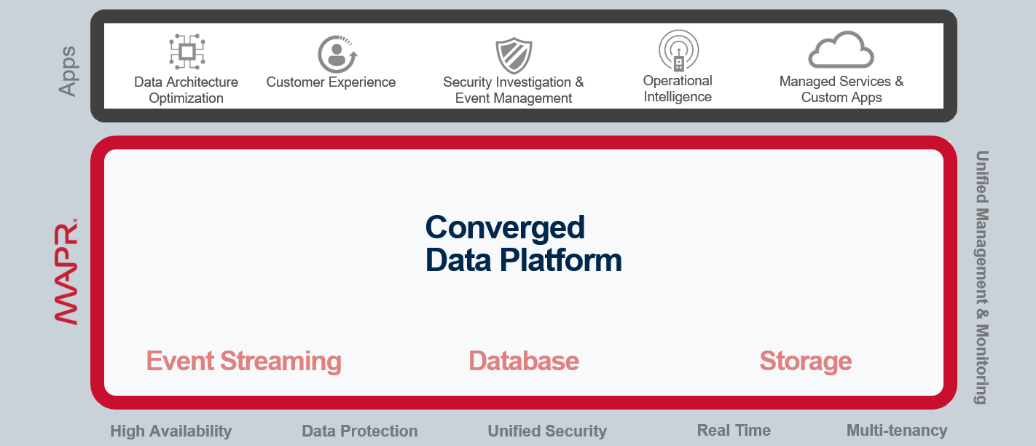
So how does this pay off? You end up with a lot of applications that are making small, machine-generated adjustments. Machine learning can be relatively simple or very complex, and making these small adjustments can yield better results, such as increased revenue, lower costs, less risk, and so forth. It is not about asking bigger questions with a query, where an analyst is tasked with figuring out how to change the business; rather, it is built into the operations to make changes. The big trend is that this requires architectural changes that result in a simpler datacenter footprint. It is not a “rip and replace” procedure to get there, either. Many of our customers do it in very incremental ways, including offloading from more expensive systems to take advantage of cost savings and performing a series of application rollouts. We have actually done quite a few mainframe offloads, and the data is not limited to a star-schema format and SQL queries. You can perform machine learning on the data as well as use graph databases and other constructs; you can have a whole host of applications running on that data.
We have customers with large clusters running dozens of applications as well as those with more than a hundred. When we talk about convergence, we see all of these things running on the data. And when we say run on the data, we mean we have converged Hadoop and enterprise storage, so you can put mission-critical data on it and treat it as a system of record. We have a database that is part of this converged platform, which enables you to perform real-time analysis on your data.
Liaison Technologies, which has created a cloud service for healthcare providers, is a good example of a customer who has built a converged data platform. Their “customers” include hospitals, clinics, insurance companies, and physicians who need to view and process electronic patient records and test procedure information; understandably, there was a long processing delay, and everyone consumed the data slightly differently.
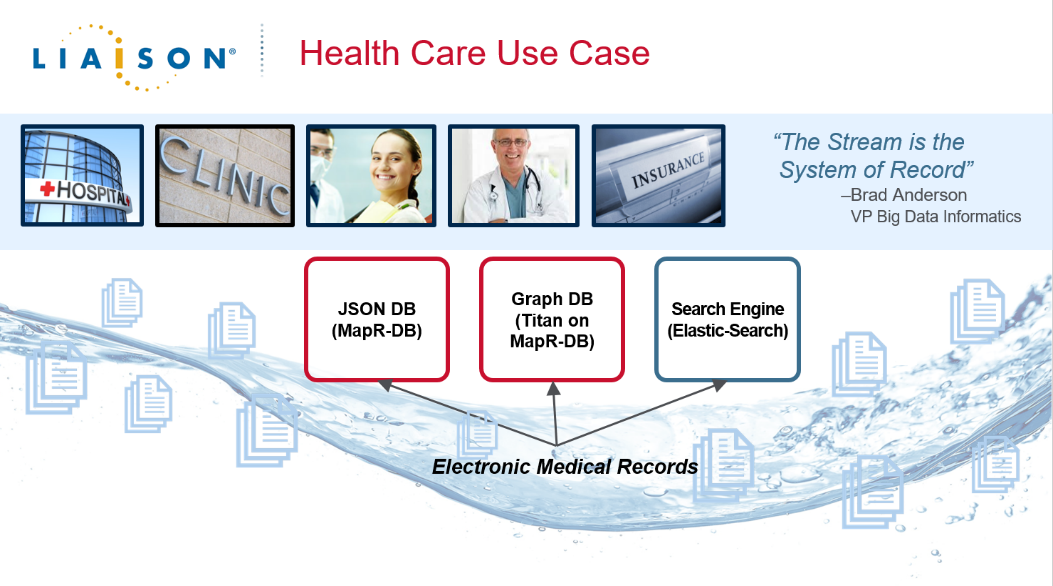
Liaison is moving to a stream-based solution, and the stream itself is the system of record because it does not have an arbitrary time to live—the stream can be persisted as long as they need. It is a publish-subscribe paradigm, so any update to an electronic medical record that is subscribed to by a hospital or insurer is available and consumed in the format that they need—a search index, a NoSQL database, or a graph database; they are able to collapse all of that processing. In addition, their solution supports JSON formats, so the data itself can change frequently; they don’t have to stop to change the data model or downstream applications because someone needed to add an additional field or data relationship. They have changed the entire data flow, which enables the data pipelines in this ecosystem to be coordinated in real-time, and done in such a way that has eliminated a lot of the internal processing steps that delayed the business actions that Liaison customers could take.
We call this a “converged” solution, but does that mean it’s converged because it’s in a single location? No. All of those are distributed across different datacenters, and in some cases, customers are using public clouds. The convergence is a logical convergence, so the data is available for different types of manipulation. It is not like you have to do an ETL process to do a table scan or process things as files. You can do it all on a single platform and still have the privacy and security for HIPAA compliance.
In the Liaison case, this is not small IoT data—it is a medical record that is in the stream, and that kind of data represents the future that enterprises are moving towards.
The point is not to gather the most data possible, but rather to have the most data agility. Remember that the key to agility is having both converged data and converged processing, which includes event-based data flows. This is just the beginning, and customers understand it is a journey.
The Docker container environment is an important aspect of this, which makes it easier to move workloads and take advantage of idle cycles on web server farms and so on. But many organizations are limiting their containers to just ephemeral applications; if it is a stateful application, it adds another layer of complexity. Customers recognize that with a converged data platform as a complementary layer to containers, they can have what we might call data virtualization—and we use that term somewhat hesitatingly—and they can have all of these physical devices mount that data directly and whatever container happens to be running on top of those devices can pull that data. This opens up the stateful applications as candidates for this containerization. Add in the Apache Myriad project, and you not only have the ability to have a container environment governed by Mesos, but within the containers you can have Hadoop operating YARN and a variety of workloads. This gives you the best of both worlds.
The datacenter is going through tremendous change, and many long-held assumptions are now being called into question. With the right answer, these questions will invariably lead to greater agility.
Jack Norris is senior vice president of data and applications at MapR Technologies. In addition to being a senior consultant at Bain & Company, Norris has been a senior executive at Brio Technology, Rainfinity, EMC, Aster Data Systems, Wanova, ParaScale, and Power Assure in his two decades in the IT industry.




Be the first to comment