

Networking chip maker Cavium is one of the ARM server chip upstarts that is taking on Intel’s hegemony in the datacenter, and is probably getting the most traction among its ARM peers in the past year with its ThunderX multicore processors.
The first-generation ThunderX chips are seeing the most interest from hyperscalers and HPC centers, plus a few cloud builders, telcos, and large enterprises, that want to explore the possibilities of a different server architecture, and they will be even more intrigued by the second-generation ThunderX2 processors, which Cavium unveiled earlier this week at the Computex trade show in Taipei, Taiwan.
Cavium has been fairly tight lipped about its second generation of ARM server chips publicly, but has no doubt showed its processor roadmap to prospective customers who might be hesitant to adopt a new chip architecture from a new vendor and an entirely different supply chain of components and systems than they are used to dealing with. There is always some risk in adopting a new technology, and the key, as Cavium and Applied Micro have both demonstrated, is to make an ARM system that looks as much like an X86 server as is possible and thereby reduce the resistance to adopting the technology.

The current ThunderX processor, which we detailed last winter when it first started shipping to customers, is etched using 28 nanometer processes that are at this point very mature but are at the same time no longer on the cutting edge as far as processors and GPUs are concerned. Cavium uses both GlobalFoundries and Samsung as its fabrication partners for its chips, and is rarely specific about which one it is using for any given product, but Gopal Hegde, vice president and general manager of the Data Center Processor Group at Cavium, tells The Next Platform that with the original ThunderX processor, was made by GlobalFoundries. With the ThunderX2 chip, Cavium will shift to a 14 nanometer FinFET process that is analogous to the 14 nanometer process that Intel is using for its “Broadwell” family of Xeon D, Xeon E5, and Xeon E7 chips for servers and that will also be used for next year’s “Skylake” Xeons. Cavium is not revealing who will be making the ThunderX2 chips, but given the process and the timing, it is either GlobalFoundries or Samsung.
The die shrink from 28 nanometers to 14 nanometers is a big one, and it allows for Cavium to do a number of things to enhance the performance of the ThunderX processors, including adding more cores and cache memory and cranking up the clocks a bit. With the ThunderX2, as it turns out, Cavium is using a mix of architectural improvements to its custom ARMv8 cores, including the addition of out-of-order execution for instruction pipelines (a common practice for decades with RISC, Itanium, and Xeon chips but new to ARM processors) as well pulling all of these other levers to goose the performance by a factor of 2X to 3X, depending on the workloads. By doing so, says Cavium, it will be able to keep the performance of its ARM server chips on par with the low-end of the Skylake Xeon product line, including single-socket Xeon D and Xeon E3 chips as well as two-socket Xeon E5 variants with a modest number of cores.

Even though Cavium has lots of cores on its die – 48 with ThunderX and 54 with ThunderX2 – those custom ARM motors have less oomph individually compared to a Haswell, Broadwell or Skylake Xeon core. Cavium is making it up in volume and for the kinds of multithreaded applications it is seeking to run in the datacenter, it can make a credible argument that 48 or 54 threads can be as effective as running 10 or 12 cores with 20 or 24 threads in a Xeon processor with HyperThreading enabled. It really depends on the workloads tested and the nature of the code itself, which is why prospective ARM server chip makers have to do lots and lots of testing before they commit to the architecture and the relatively young software stacks available for ARM server chips. (The ecosystems for ARM and Power have certainly come a long way in two years, and this is a matter we will discuss in a future piece.)
With such a large shrink in transistor sizes, Cavium could have just plunked down a lot more cores than it did and position the ThunderX2 as a throughput engine. But one of the concerns that many people have with the original ThunderX chips (and that Intel also faces with its 76-core “Knights Landing” Xeon Phi parallel processor, which only makes 72 of them available for use) is that single-threaded performance is not as good as on a stock Xeon processor core. So Cavium is tweaking its homegrown core to boost its performance, Rishi Chugh, director of marketing in the Data Center Processor Group, tells us. The specifics on these architectural changes are a bit light, this being but a preview for a product that will start sampling to early customers in the first quarter of 2017. (We had been told last year to expect a ThunderX2 to sample sometime in 2016, but everyone is having trouble ramping to 14 nanometers, including Intel.)
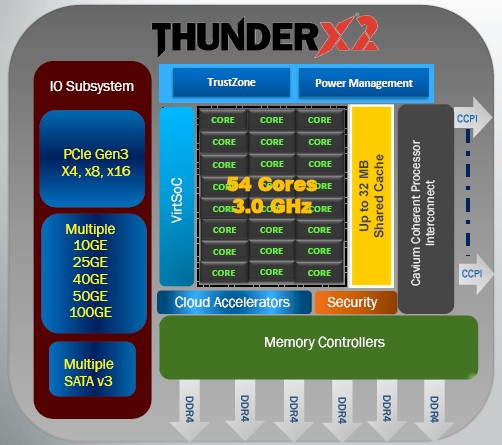
Like the ThunderX cores, those in the ThunderX2 feature out-of-order execution that is common among RISC processors as a way of boosting performance. The ThunderX ARM core had a nine-stage pipeline to stack up instructions and featured a 78 KB L1 instruction cache and a 32 KB L1 data cache. We don’t know if Cavium has made the pipelines on the ThunderX2 cores deeper, but we suspect so as this would enable it to boost the clock speed a bit and keep the cores humming. The ThunderX cores were designed to run at a peak of 2.5 GHz, but the commonly available parts run at only 2 GHz and, as we explained in recent benchmark results pitting the ThunderX against the Xeons, these 2 GHz chips run at 135 watts, much higher than the 95 watts expected with a 2.5 GHz top bin part when Project Thunder was unveiled in late 2014. We suspect that the 3 GHz upper limit targeted for the ThunderX2 cores means a slightly deeper pipeline.
What Chugh did say is that the ThunderX2 cores would have less L1 instruction cache per core, dropping 18 percent to 64 KB, while the L1 data cache would be boosted by 25 percent to 40 KB per core. Unlike Xeon processors, which have L3 cache, the ThunderX and ThunderX2 chips have a shared L2 cache as their last level of on-die memory, and in this case it is being doubled to 32 MB with the ThunderX2.
To help compensate for cache misses in the L2 cache and the lack of an L3 cache, Cavium has relied upon lots of main memory controllers and faster memory chips. Or, to say it even more precisely, for certain kinds of workloads that Cavium is not targeting with the Thunder family of chips, L3 caches (and even L4 caches) help a great deal, but for the scale-out analytics, storage, and frameworks jobs that Cavium has designed the Thunder chips for, a mix of fat L2 cache plus fast and fat main memory should compensate. By dropping L3 cache, Cavium can put more cores on the die and boost the throughput. With the ThunderX chip, Cavium had four memory controllers and memory could run as fast as 2.4 GHz, a speed that Intel is only just now supporting with its Broadwell Xeon E5 chips. With the ThunderX2, the chip will now have six memory controllers supporting DDR4 memory that can run as fast as 3.2 GHz. Next year’s Skylake Xeon processors will top out at 2.67 GHz DDR4 memory with one DIMM per channel and 2.4 GHz with two DIMMs per channel. The memory capacity of the ThunderX2 is 50 percent higher, and the memory bandwidth is twice as high as with the ThunderX.
“We have a fairly sophisticated caching scheme, which we are not disclosing right now,” says Hegde. “There are changes that improve performance, particularly for networking types of workloads, that we are not talking about yet.”
Also on the rise is the bandwidth on the Cavium Coherent Processor Interconnect (CCPI), which has been doubled and which should therefore mean it runs at 480 Gb/sec compared to 240 Gb/sec for the ThunderX and to 384 Gb/sec for the pair of QuickPath Interconnect links on Intel Xeon E5 chips that are used to link multiple processors together. Hegde says that with the four-socket and eight-socket parts of the server market being so small, Cavium is not interested in moving on up to four-socket or eight-socket configurations, although its CCPI interconnect can scale up that way if need be. The idea is to focus on scale-out workloads that by their nature do not mind being broken up and spread across many nodes in a cluster. The increased bandwidth on the CCPI will presumably make NUMA scaling across two-sockets much more efficient and therefore allow more of the CPU work to be done and not eaten up by latency across the interconnect.
Cavium is sticking with PCI-Express 3.0 controllers with the ThunderX2, but the interesting thing – and important for the attachment of accelerators – is that ThunderX2 will support x16 slots, while ThunderX topped out at x8. It will probably take until ThunderX3 to see PCI-Express 4.0 controllers. IBM is moving to PCI-Express 4.0 peripherals with next year’s Power9 chip, and it looks like it will be first for that. Unless Intel changes its plans, the Skylake Xeon E5 processors will sport PCI-Express 3.0 peripheral controllers on the die, not PCI-Express 4.0.
The integrated Ethernet on the ThunderX2 chips is based on 25 Gb/sec SERDES circuits, which allows multiple ports to come off the die running at 10 Gb/sec, 25 Gb/sec, 40 Gb/sec, 50 Gb/sec, and 100 Gb/sec speeds. The number of each kind of port depends on the bandwidth you pick, and while Cavium is not disclosing the overall bandwidth for Ethernet, it can support multiple 100 Gb/sec ports on the ThunderX2; the ThunderX had 80 Gb/sec that could be configured as eight 10 Gb/sec or two 40 Gb/sec ports. The ThunderX chip had 16 SATA v3 ports as well, and this number will go up with ThunderX2, but Cavium is not saying by how much.
The ThunderX2 will have various virtualization, storage, and network accelerators boosted, and on the security front, it will include the Nitrox 5 security accelerators rather than the Nitrox 3 circuits used with the current ThunderX chips. And, it will also have more sophisticated active power management features, which were not in the ThunderX, and an idle power that is lower than for the ThunderX as well. These are very important, since Intel has done a very good job with power management on the Xeon line. Support for dynamic voltage and frequency scaling is being added for the first time, and so is fine grained power controls for elements of the chip.
“Obviously this expands the target workloads for the second generation,” says Larry Wikelius, vice president of the Software Ecosystem and Solutions Group at Cavium. “With the first generation, we focused on scale-out object and block storage with Ceph to Hadoop batch analytics to network function virtualization combined with OpenStack. All of these have been a good sweet spot for us with generation one. With generation two, we are coming out with higher single-threaded performance and additional capabilities in the SoC as a whole, we can start thinking about massively parallel data warehouses and Lucene or Solr search or in the HPC space things like computational fluid dynamics or other codes that are a natural fit. The application set will continue to expand.”
Both generations of Thunder chips come in four flavors. The CP variants are aimed specifically at compute workloads as opposed to other versions of the ThunderX chips aimed at storage (ST), networking (NT), and secure compute (SC). Across these four SKUs, Cavium will deliver different mixes of core counts and clock speeds to meet various requirements, and activate different elements of the SoC in terms of controllers and accelerators.
Lining Up Performance Against Xeons
Add up all of the changes from the ThunderX to the ThunderX2 and the performance per socket of the forthcoming ARM processor is increased by a factor of 2X to 3X, says Chugh. Shifting from 28 nanometers to 14 nanometers drops the power consumption by 30 percent for the same design, and that extra 30 percent is what allows ThunderX2 to have a lot more components and still stay in the same 135 watt thermal envelope as the 2 GHz ThunderX part.
Here is how different workloads stack up running on a 54-core ThunderX2 part running at 3 GHz compared to a 48-core ThunderX running at 2 GHz:
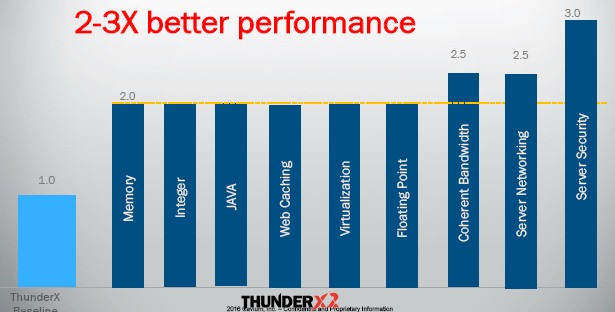
In general, it looks like the core ThunderX2 will deliver about 2X the performance as the ThunderX, with the Nitrox 5 security accelerators used in the SC variant pushing it up into the 3X range.
The most important comparison for ThunderX2 is against the current Broadwell and anticipated Skylake Xeons, and Cavium ginned up this little chart to show how its chips might stack up against the Intel chips using a Broadwell Xeon as a baseline.
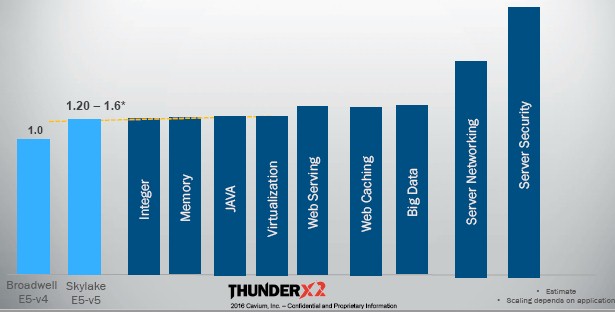
In the above table, Chugh says that Intel will be able to increase the performance of Skylake Xeons by about 20 percent per socket on regular workloads and by about 50 percent to 60 percent on memory intensive applications. This comparison is for top-bin parts all around, which means a Broadwell Xeon E5-2699 v4 with 22 cores and a Skylake Xeon E5 with 28 cores.
With the comparisons that Cavium has been making with ThunderX recently, it is comparing its top bin parts to 12-core Broadwell Xeons, thus:

As you can see, Cavium is showing itself to be at parity or better on selected workloads, and two of them – Java transaction processing and web caching – are ones that Intel said in recent tests it could not get meaningful results out of when it tried to run its own benchmarks on ThunderX chips.
We are following up with Cavium to get more details on its own benchmark tests.
Pricing has not been set yet for the ThunderX2 chips, obviously, since they won’t even be sampling until early next year. “You can expect it to heavily overlap with ThunderX pricing,” says Hegde. “Whether we will have higher priced SKUs and what those prices might be, we don’t know yet. The one thing that Intel has done is consistently open up a higher-end bin, which delivers the 20 percent to 25 percent performance boost, but the price is high. We are not Intel, so we want to make sure that there is a huge incentive for people to switch to a ThunderX or ThunderX2 platform. Pricing will depend a lot on competition and the price that the market is willing to pay.”

Intel Chip Research Pushes Power Efficiency And Performance
Since Pat Gelsinger’s return to Intel as chief executive officer in early 2021, the company has bet big on bolstering its manufacturing processes and foundry business, expanded its fab footprint in the United States, and advocated for expanding the country’s chip making capabilities. Intel’s success – or failure – in …

For CPU Makers and OEMs Alike, It’s A Platform View
Dell took a look at the two weeks between the rollouts by AMD and Intel of their latest server processors and, after some debate, decided to unveil its entire portfolio of new and enhanced systems – featuring the new chips from both vendors – at the launch of AMD’s latest …

Covering All The Compute Bases In A Heterogeneous Datacenter
Intel has spent more than three decades evolving from the dominant provider of CPUs for personal computers to the dominant supplier of processors for servers in the datacenter. While Intel has argued that Moore’s Law is not dead – that the pace of innovation with transistors and therefore semiconductors has …
It’s hard not to be cynical when ARM server vendors come knocking at this point. We did POCs with more than one and were continuously disappointed. Have come to recognize the party lines that get spouted.
“Our chip will compete with Intel Y”: for a few generations now this comparison has been made. And it’s technically true. When the ARM chip ships it’s in the market at the same time as some Intel chip, and has repeatedly fallen short of such comparisons. I take this with the appropriate pinch of salt now, and applaud their efforts, but the reality is that no ARM server has delivered yet.
My estimate is that they’re pushing from roughly A53 equivalent perf on this generation to A57 on the next. I wish them well but even then I doubt it’s sufficient.
Wikelius’ comments re ecosystem are another anti-pattern from the vendors (and I was a rare customer of the previous place I heard these claims from). Historically, Calxeda for example, pitched wildly inappropriate workloads such as hadoop. The numbers made no sense. Storage was somewhat a bright spot and Cavium seem to have double-downed on the Calxeda MO. Lots of conference trips, lots of meetings, lots of credit for sponsoring random bits of software to be ported, but completely inappropriate to the workloads for which these things are suited. Always a case of “never mind the appropriateness, look at this slide full of logos”.