

The strong interest in deep learning neural networks lies in the ability of neural networks to solve complex pattern recognition tasks – sometimes better than humans. Once trained, these machine learning solutions can run very quickly – even in real-time – and very efficiently on low-power mobile devices and in the datacenter.
However training a machine learning algorithm to accurately solve complex problems requires large amounts of data that greatly increases the computational workload. Scalable distributed parallel computing using a high-performance communications fabric is an essential part of what makes the training of deep learning on large complex datasets tractable in both the data center and within the cloud.
Very simply, the single node TF/s parallelism delivered by Intel Xeon processor and Intel Xeon Phi devices described in the previous article in this series is simply not enough for many complex machine learning training sets. High-performance, low latency communications fabrics like Intel Omni-Path Architecture (Intel OPA) are required to tightly couple many computational nodes into an MPI or cloud configuration that can deliver sufficient memory capacity and floating-point performance to find acceptably good machine learning solutions in a reasonable time.
Complex problems require big data
Lapedes and Farber showed in their paper, “How Neural Networks Work” [3], that neural networks essentially learn to solve a problem by fitting a multi-dimensional surface to the example data. During training, the neural network uses its nonlinear functions to build and place bumps and valleys at the high and low points in the surface. Prediction works by interpolating between, or extrapolating from points on this surface. Empirically, the more complex the problem, the more bumpy the surface that must be fit, which increases the amount of data that must be presented during training to define the location and height of each point of inflection (e.g. bump or valley). In short: the more complex the problem, the greater the amount of data that is required to accurately represent the bumpy surface for training.
 Happily, massively parallel distributed mappings that exhibit near-linear scalability such as the exascale-capable mapping by Farber (described in the previous article) give data scientists the ability to use high-performance interconnects such as the Intel OPA to use as many computational nodes as necessary to train on very large and complex datasets.
Happily, massively parallel distributed mappings that exhibit near-linear scalability such as the exascale-capable mapping by Farber (described in the previous article) give data scientists the ability to use high-performance interconnects such as the Intel OPA to use as many computational nodes as necessary to train on very large and complex datasets.
Joe Yaworski (Intel Director of Fabric Marketing for the HPC Group) notes that, “The Intel Omni-Path Architecture delivers a mixture of hardware and software enhancements that will optimize machine learning performance, as it’s specifically designed for low latency and high message rates that scales as the cluster size increases.” Benchmark results presented later in this article validate Yaworski’s statement.
The Intel Omni-Path Architecture delivers a mixture of hardware and software enhancements that will optimize machine learning performance, as it’s specifically designed for low latency and high message rates that scales as the cluster size increases – Joe Yaworski (Intel Director of Fabric Marketing for the HPC Group)
Tuning machine learning for the fastest time to solution in a distributed environment
A data scientist can tune a training run to be as fast as possible in a distributed environment simply by using more nodes thus reducing the number of examples per distributed computational node for a fixed training set.
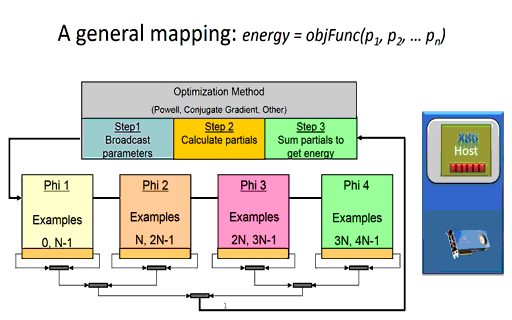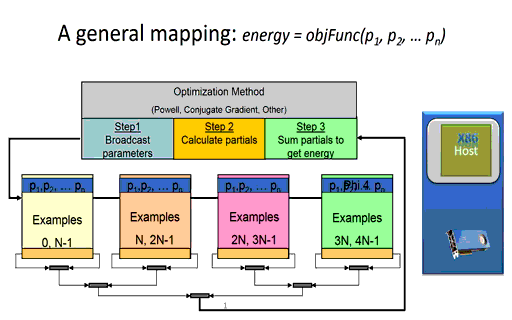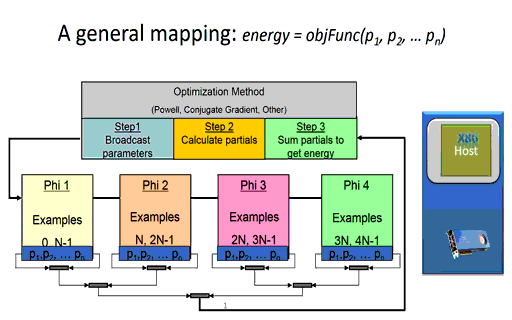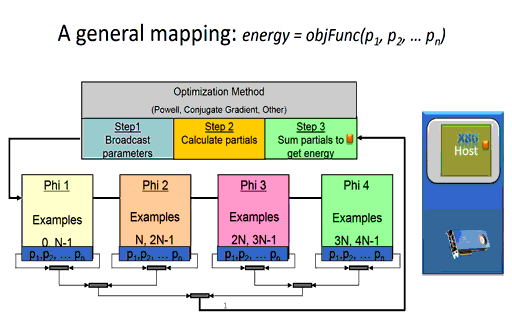
Briefly, the time it takes a node to calculate the partial error (shown in step 2 in Figure 3 below) during training effectively depends on the number of network parameters and the number of training examples to be evaluated on the node. The size and configuration of the neural network architecture is fixed at the start of the training session, which means the runtime of the per-node calculation of the partial errors can be minimized simply by reducing the number of training examples per node. (Of course, there is a limit as using too few examples will waste parallel computing resources). Since the partial error calculation on each node is independent, the runtime consumed when computing the partial errors in a distributed environment for a fixed training set size will be decrease linearly as the number of nodes increases. In other words, calculating the partial errors for a fixed dataset will happen 10x faster when using ten nodes in a compute cluster or cloud instance and 10,000 times faster when using ten thousand nodes.
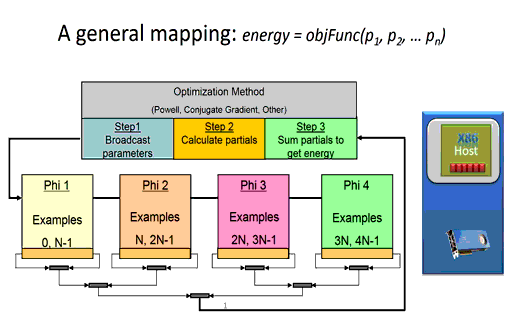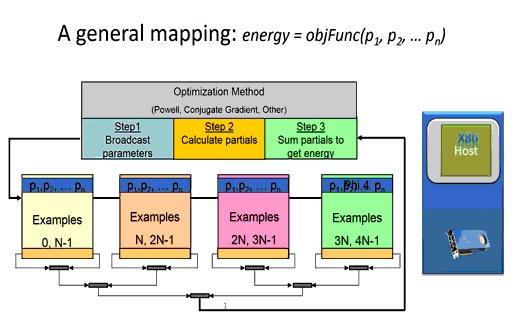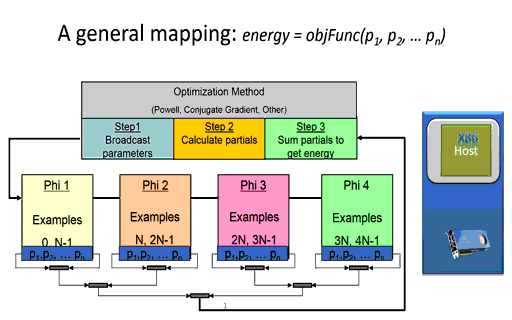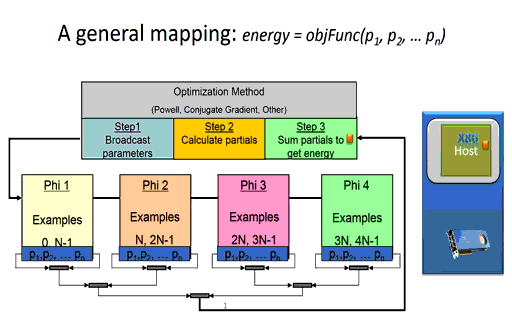
Figure 3: A massively parallel mapping (the animated version is available here.)
As the speed and number of the computational nodes increases, the training performance for a given training set will be dictated more and more by the performance characteristics of the communications network.
For example, the global broadcast of the model parameters (shown in step 1) will effectively take constant time regardless of the number of distributed nodes used during training [4]. The basic idea, much like that of radio or broadcast television, is that it takes the same amount of time to broadcast to one listener as it takes to broadcast to all the listeners.
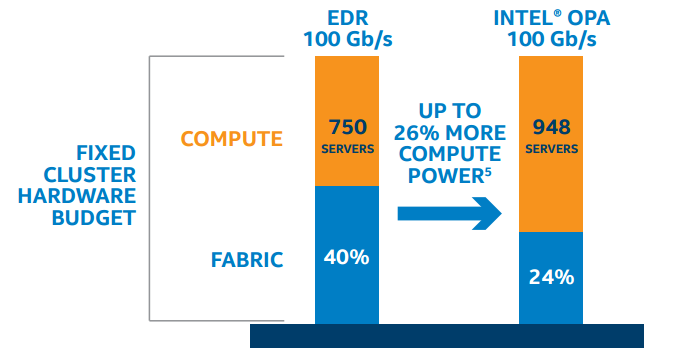
Inside the distributed computer (be it a local cluster, cloud instance, or leadership class supercomputer), it is the overall throughput of the communications fabric that dominates the broadcast time. The raw bits per second transported by the network links is important as a both 100 Gb/s InfiniBand EDR and Intel OPA communications fabrics will communicate data faster than older, 56 Gb/s FDR networks. As shown in the figure below, the raw (wire rate) 100 Gb/s number tells only part of the story as throughput also depends on how well the underlying protocol communicates data and performs error correction. What really matters for HPC application performance, be it global broadcast or point-to-point communication is the amount of data transported per unit time, which is the measured MPI bandwidth.
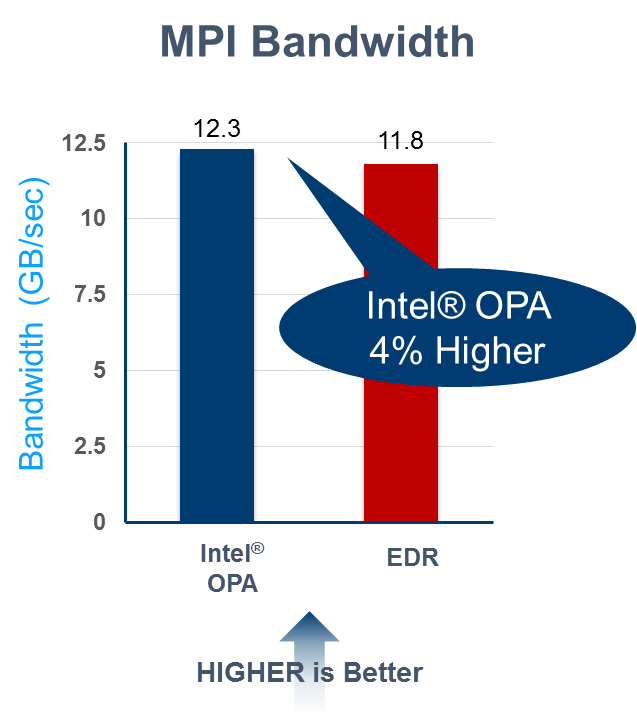
The higher MPI bandwidth compared to InfiniBand EDR can help to speed the training of deep learning neural networks that contain millions of network parameters, all of which need to be communicated quickly across the fabric to the distributed computational nodes.
Intel OPA has incorporated a number of features that preserve high-performance, robust distributed HPC computing at scale such as:
- Packet Integrity Protection (PIP): PIP allows corrupted packets to be detected without increasing latency. According to the Intel publication, Transforming the Economics of HPC Fabrics with Intel Omni-Path Architecture, the Intel OPA strategy eliminates the long delays associated with end-to-end error recovery techniques that require error notices and retries to traverse the full length of the fabric. In contrast, some recent InfiniBand implementations support link-level error correction through a Forward Error Correction (FEC). However, FEC introduces additional latency into the normal packet processing pipeline. Intel OPA provides similar levels of integrity assurance without the added latency.
- Dynamic Lane Scaling: Each 100 Gbp/s Intel OPA link is composed of four 25 Gbps lanes. In traditional InfiniBand implementations, if one lane fails, the entire link goes down which will likely cause the HPC application to fail. In contrast, if an Intel OPA lane fails, the rest of the link remains up and continues to provide 75 percent of the original bandwidth.
- Adaptive routing: Intel OPA supports a variety of routing methods, including defining alternate routes that disperse traffic flows for redundancy, performance, and load balancing.
- Traffic Flow Optimization: Traffic Flow Optimization reduces the variation in latency seen through the network by high priority traffic in the presence of lower priority traffic. It addresses a traditional weakness of both Ethernet and InfiniBand* in which a packet must be transmitted to completion once the link starts even if higher priority packets become available. This can be very useful when running machine learning jobs in the presence of other HPC jobs.
- Reduced CPU utilization: CPU utilization has been significantly reduced with PSM (Performance Scaled Messaging) software as will be seen in the benchmark results below.
Small message latency is the key to faster distributed machine learning
For network bound computations, the network reduction can be the rate limit step during training.
Reduction operations generally call highly optimized library methods such as MPI_Reduce() when running in an MPI environment. For machine learning, a reduction is used to combine the partial errors calculated on each distributed node into a single overall error used by the optimization method to determine a newer, more accurate set of neural network parameters. As can be seen in the Figure 3 animation, the new parameters cannot be calculated until the sum of the partial errors computed by each computational node are reduced to a single floating-point value.
As part of the reduction operation, each computational node must communicate its single floating-point partial error value across the communications fabric, which means that latency and small message throughput must scale with the number of computational nodes.
Intel OPA was designed to provide extremely high message rates, especially with small message sizes. It also delivers low fabric latency that remains low at scale. Yaworski notes, “Intel OPA’s low latency, high message rate and high bandwidth architecture are key for machine learning performance”.
Intel OPA’s low latency, high message rate and high bandwidth architecture are key for machine learning performance – Joe Yaworski (Intel Director of Fabric Marketing for the HPC Group)
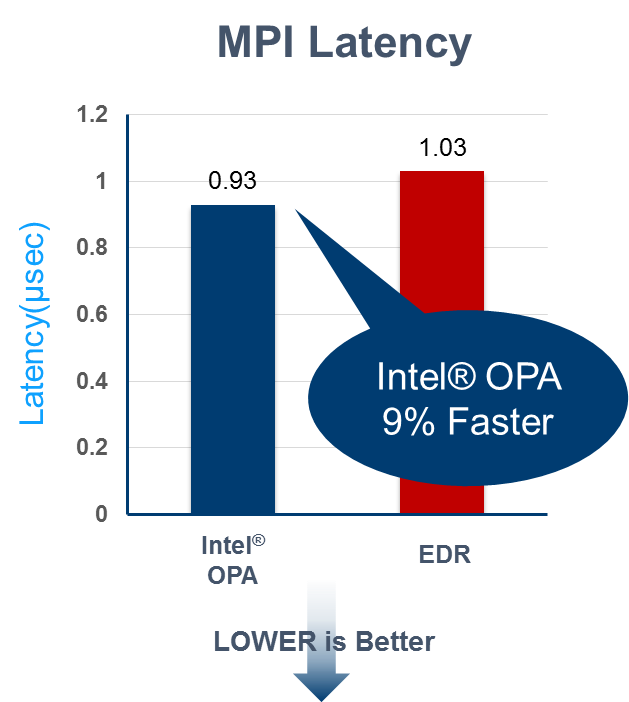 The Intel OPA performance goals have been proven in practice according to recent benchmark results.
The Intel OPA performance goals have been proven in practice according to recent benchmark results.
- Lower MPI Latency: Compared to EDR InfiniBand, Intel OPA demonstrates lower MPI latency* as measured with the Ohio State Micro-Benchmarks osu_latency test.
- Higher MPI message rate: Intel OPA also demonstrates a better (e.g. higher) MPI message rate on the Ohio State Micro-Benchmarks osu_mbw_mr test. The test measurements included one switch hop.

Latency as a function of number of nodes** (Image courtesy Intel)
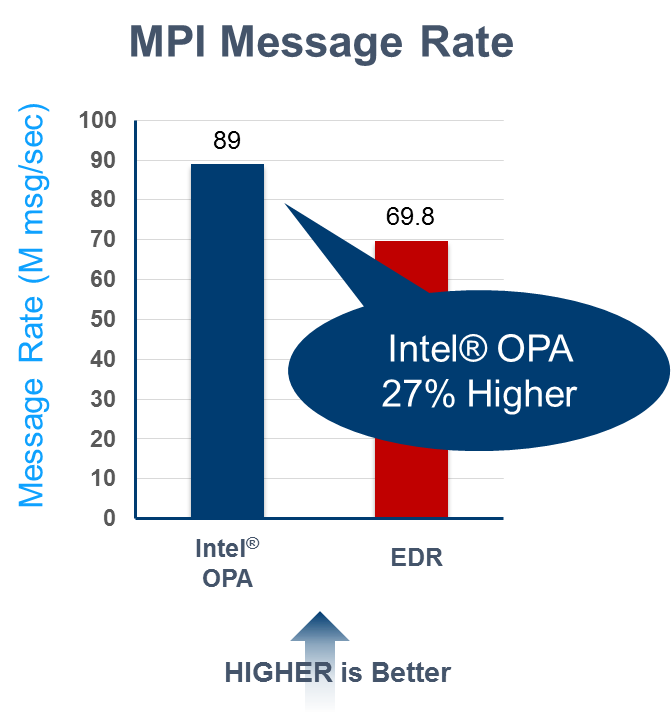
- Lower latency at scale: Tests results show that Intel OPA demonstrates better latency than EDR at scale.
Lower CPU utilization: It’s also important that communication not consume CPU resources that can be used for training and other HPC applications. As shown in the Intel measurements, Intel OPA is far less CPU intensive.
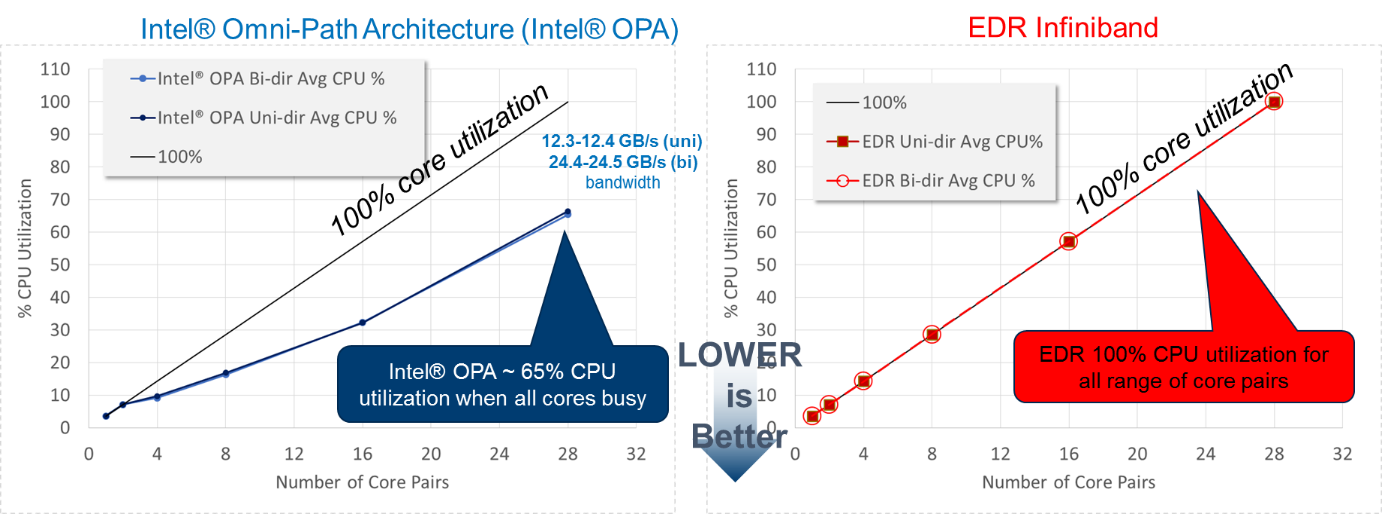
In combination, these Intel OPA performance characteristics help to speed machine learning in a distributed cloud or HPC cluster environment. The scalability and increased performance when handling small messages gives Intel OPA an advantage over EDR InfiniBand when calculating reductions.
Summary
This is the second in a multi-part series on machine learning that examines the impact of Intel SSF technology on this valuable HPC field. Intel SSF is designed to help the HPC community utilize the right combinations of technology for machine learning and other HPC applications.
For data transport, the Intel OPA specifications hold exciting implications for machine learning applications as it promises to speed the training of distributed machine learning algorithms through: (a) a 4.6x improvement in small message throughput over the previous generation fabric technology, (b) a 65ns decrease in switch latency (think how all those latencies add up across all the switches in a big network) [5], and (c) by providing a 100 Gb/s network to speed the broadcast of millions of deep learning network parameters to all the nodes in the computational cluster (or cloud) plus minimize startup time when loading large training data sets.
[1] Kirkley, “A New Direction in HPC System Fabric: Intel’s Omni-Path Architecture”, InsideHPC, July 12, 2015.
[2] See Figure 1 in Transforming the Economics of HPC Fabrics with Intel Omni-Path Architecture.
[3] “How Neural Nets Work,” Neural Information Processing Systems, Proceedings of IEEE 1987 Denver Conference on Neural Networks, A.S. Lapedes, R.M. Farber. (D.Z. Anderson, editor), (1988).
[4] One example in the literature is, “A practically constant-time MPI Broadcast Algorithm for large-scale InfiniBand Clusters with Multicast”.
[5] https://ramcloud.atlassian.net/wiki/download/attachments/22478857/20150902-IntelOmniPath-WhitePaper_2015-08-26-Intel-OPA-FINAL.pdf
* Tests performed on Intel Xeon Processor E5-2697v3 dual-socket servers with 2133 MHz DDR4 memory. Intel Turbo Boost Technology enabled and Intel Hyper-Thread Technology disabled. Ohio State Micro Benchmarks v. 4.4.1. Intel OPA: Intel MPI 5.1.2, shm:tmi fabric, RHEL7.0. Intel Corporation Device 24f0 – Series 100 HFI ASIC (B0 silicon). OPA Switch: Series 100 Edge Switch – 48 port (B0 silicon). IOU Non-posted Prefetch disabled in BIOS. Snoop hold-off timer = 9. EDR based on internal testing: Intel MPI 5.1.3, shm:dapl fabric, RHEL 7.2 -genv I_MPI_DAPL_EAGER_MESSAGE_AGGREGATION off. Mellanox EDR ConnectX-4 Single Port Rev 3 MCX455A HCA. Mellanox SB7700 – 36 Port EDR InfiniBand switch. MLNX_OFED_LINUX-3.2-2.0.0.0 (OFED-3.2-2.0.0). IOU Non-posted Prefetch enabled in BIOS. 1. osu_latency 8 B message. 2. osu_bw 1 MB message. 3. osu_mbw_mr, 8 B message (uni-directional), 28 MPI rank pairs. Maximum rank pair communication time used to compute bandwidth and message rate instead of the average time which was introduced into Ohio State Micro Benchmarks as of v3.9 (2/28/13). Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary.
**Tests performed on Intel Xeon Processor E5-2697 v3 dual-socket servers with 2133 MHz 64 GB DDR4 RAM per node. Intel Turbo Boost technology enabled. 28 MPI ranks per node. HPCC 1.4.3. Intel OPA: Open MPI 1.10 as packaged with IFS 10.0.0.0.697. Intel Corporation Device 24f0 – Series 100 HFI ASIC (B0 silicon). OPA Switch: Series 100 Edge Switch – 48 port (B0 silicon). Mellanox EDR based on internal measurements. Mellanox EDR ConnectX-4 Single Port Rev 3 MCX455A HCA. Mellanox SB7700 – 36 Port EDR Infiniband switch. Open MPI 1.8-mellanox released with hpcx-v1.3.336-icc-MLNX_OFED_LINUX-3.0-1.0.1-redhat6.6-x86_64.tbz. Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary.
*** Tests performed on Intel Xeon Processor E5-2690v4 dual-socket servers with 2400 MHz DDR4 RAM per node. OSU OMB 4.1.1 osu_mbw_mr with 1-28 ranks per node. Number of iterations at 1MB message size increased to allow quasi-steady CPU utilization to be captured using Linux top. CPU utilization is shown as the average on both the send and receive nodes across all participating cores. Example: 1 core 100% busy on a 10 core CPU would be “10% CPU utilization”. Benchmark processes pinned to the cores on the socket that is local to the adapter before using the remote socket. Intel MPI 5.1.2. RHEL 7.1. Intel OPA: shm:tmi fabric, Intel Corporation Device 24f0 – Series 100 HFI ASIC (B0 silicon). OPA Switch: Series 100 Edge Switch – 48 port (B0 silicon). Mellanox EDR: shm:dapl fabric. Mellanox ConnectX-4 MT27700 HCA and MSB7700-ES2F switch. Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary.




{kind=link}
Be the first to comment