

It is almost without question that search engine giant Google has the most sophisticated and scalable data analytics platform on the planet. The company has been on the leading edge of analytics and the infrastructure that supports it for a decade and a half and through its various services it has an enormous amount of data on which to chew and draw inferences to drive its businesses.
In the wake of the launch of Amazon Web Services a decade ago, Google came to the conclusion that what end users really needed was services to store and process data, not access to raw infrastructure that they could use to move applications running in their datacenters over to ones run by Google. Microsoft believed the same thing as it built its Azure cloud. And as it turns out, both Google and Microsoft were wrong, not in a technical sense, but in a cultural one. Just like Google software engineers had to learn to let go of infrastructure, so too does the entire IT industry, which needs to retool hundreds of thousands to millions of applications to run on virtual machines in clouds and which will then spend heaven only knows how long refactoring them to run in containers in a fashion that has been old hat at Google for more than a decade.
As we have pointed out before, the idea of giving customers a platform to run applications on, or a service that comprises the application and into which customers just pour data and hit the chew button, is still something that Google believes very strongly in. Google previewed its Cloud Dataflow service, which is used for real-time batch and stream processing and competes with homegrown clusters running the Apache Spark in-memory system, back in June 2014, put it into beta in April 2015, and made it generally available in August 2015. Spark comes out of the same AMPLab at the University of California at Berkeley that gave us the Mesos container and cluster management system that is up against the Google-created Kubernetes container management system, so if you are sensing some rivalry here, you are not wrong. (Google has yet to open source the Dataflow framework, but that could yet happen. The SDK for Dataflow is written in Java and it is open source under the Apache Beam project.)
Spark is the hot new framework out there in data processing, of course, thanks to the speed bump that it gives over the MapReduce technique that was created by Google and then mimicked by Yahoo to create the Hadoop distributed computational framework and related Hadoop Distributed File System. Google has a vested interest in showing how well its external service implementation, called Cloud Dataflow, performs compared to Spark, and to that end the company commissioned Mammoth Data, a consultancy based on Durham, North Carolina, to put Cloud Dataflow and Spark running on Google’s Compute Engine infrastructure cloud through the paces to see how the two stacked up in terms of scalability.
This is not a thorough analysis that includes other alternatives or price/performance metrics, which is a shame. Google, not wanting to miss out on any popular platform, also offers Cloud Dataproc, a managed Hadoop and Spark service that was announced last September and that is akin to Elastic MapReduce from Amazon Web Services. (EMR can be used to fire up automanaged Hadoop clusters, and has been out since April 2009. Spark support was added to it last June. And Microsoft’s HDInsight service, based on the Hortonworks Data Platform distribution of Hadoop, can run Hadoop or Spark as well.) A fuller comparison would have included a comparison of Dataflow with Dataproc running the same workloads as well as other Spark services on the AWS and Azure clouds, complete with pricing. We can only go with the tests we can get our hands on.
The benchmark tests that Mammoth Data was commissioned to do, which you can see here, were for a hypothetical batch processing job on a dataset derived from video playing services akin to Netflix where set-top box data from users was sorted to look for things such as how many times subscribers logged in during a specific time window. This is not a particularly large workload in terms of the dataset size, Ian Pointer, the lead consultant at Mammoth Data, explains to The Next Platform, who points out that even with a cap of 1,000 Compute Engine instances to support workloads, Cloud Dataflow can easily scale to processing on petabytes of data stored on Google infrastructure.
When setting up the Spark clusters on Compute Engine, Pointer chose the n1-highmem-16 instance types, which is a fairly hefty virtual machine with 16 virtual CPUs and 104 GB of virtual memory. These instances are implemented on “Sandy Bridge” Xeon E5 v1 processors running at 2.6 GHz, “Ivy Bridge” Xeon E5 v2 processors running at 2.5 GHz, and “Haswell” Xeon E5 v3 processors running at 2.3 GHz. Pointer says that this instance size was based on experience from setting up real-world Spark workloads; there is a beefier n1-highmem instance type with 32 vCPUs and 208 GB of virtual memory, but that was not selected. Rather than go with the default machine type setting on the Dataflow service, Pointer forced them to be the same as was used to run the Spark 1.3.1 stack, which he set up himself on the instances rather than use the Dataproc service. To test the workload, Pointer scaled up the number of cores and measured the wall clock time to do the processing, and here is how the two stacked up:
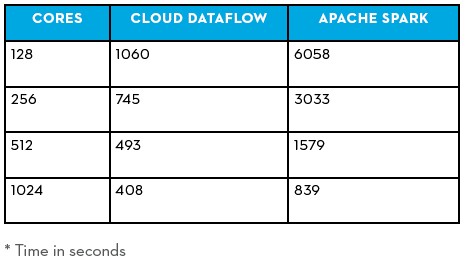
As you can see, the relative performance of Dataflow and Spark are different depending on how many cores are fired up to support the workloads, and Pointer stopped his test at 1,024 cores because this was the kind of resources that he says typical customers throw at a mid-sized batch job like the one emulated. The largest Spark cluster that Pointer knows about has 8,000 nodes (a number Spark developer DataBricks also cited to us last year), and Dataflow itself has a cap set by Google at 1,000 Compute Engine instances, which would be 32,000 cores and slightly over 200 TB of memory maximum using the n1-highmem-32 instances. As the benchmark workload scaled up on Dataflow, the performance increases diminished, and Apache Spark continued to see performance increases. It is hard to say where they might cross paths, but it looks like somewhere around 4,000 cores for this particular workload if the scaling continued on trends in the data.
The point this really makes is that each computing framework has its own performance profile, and for each kind of job that runs. What you always really need is a suite of tests that are indicative of your own workloads and to test those jobs over a wide range of scale. Cloud computing capacity is a great way to do the benchmarks, even if you do end up installing your own clusters internally to do the work.
As for the differences in the performance profiles of Dataflow and Spark, Google offered some suggestions. The dynamic workload balancing in Dataflow tries to keep the cores as busy as possible, which can create an I/O bound situation and therefore adding more cores does not necessarily boost performance as is expected. Google says that the Dataflow shuffle is optimized for 10,000 cores or fewer, and bin packing as Dataflow is doing to drive up utilization could curtail performance. (It sounds to us like Google should make these settings a little more variable.) Google also says that Dataflow was optimized to run on n1-standard-1 instances and to scale across more instances, and moreover, suggested that Dataflow batch mode has an auto-scaling mechanism that finds the optimal number of cores.
So, perhaps the real test was to pit Dataflow against Dataproc running Spark?
Some price/performance analysis is in order, but Mammoth Data did not go that extra step and do this. But we will.
Assuming that the performance was the same on the n1-standard-1 instances (which is not a good assumption necessarily), they cost 5 cents per hour with a price of 3.5 cents per hour with sustained usage with one virtual CPU and 3.75 GB of virtual memory. For the 1,024 cores, that would run $51.20 per hour at list price to run the Dataflow and Spark instances. To get the same 1,024 cores using the n1-highmem-16 instances would take 64 instances, which cost 60.8 cents per hour at list price and 42.4 cents per hour with sustained usage. At list price, that would be $38.91 at list price, which is 17 percent cheaper than the same cores using the skinny instances. So there might be an economic reason to not use those skinny instances.
The analytics jobs that Mammoth Data tested were not big enough to take many hours, except on the low core count setups where it took 1.7 hours for Spark and a little under 18 minutes for Dataflow. On the larger 1,024-core setups, Dataflow took just under 7 minutes to complete the job and Spark took just under 14 minutes. The cost of either is negligible. The question we have is what happens when you have a very big job with lots of complex processing and data that you want to run against the Dataflow and Spark frameworks? Something heavier and more time consuming might be a better way to test price/performance of the relative approaches.
What Pointer did say that self-supporting Spark on a private cluster or one running on a virtualized cluster in a public cloud is going to cost money. He estimates that the salary for a software engineer experienced with Spark could run anywhere from $85,000 to $150,000, depending on how close they are to the east or west coast of the United States, and that it will take time to set up Spark and keep it up to date to run. On real-world Spark clusters out there, Pointer says that it takes two or three people to maintain the Spark systems even on a cloud, which is less costly than running it in house, but this is still the expensive way to go. He adds that, in general, Amazon Web Services tends to be more expensive than other cloud providers for the raw capacity needed to run frameworks like Spark.
For the Dataflow option, you can’t just fire up Compute Engine instances and go. Dataflow usage incurs a 1 cent per Google Compute Engine Unit (GCEU) per hour fee on top of the capacity for batch work and 1.5 cents per GCEU per hour for streaming workloads. The n1-highmem-16 instance that Mammoth Data chose to run its tests has 44 GCEUs of capacity, so it basically costs 44 cents per hour to run Google’s software stack instead of using the open source Spark stack and self-supporting on those instances. That nearly doubles the cost of the setup, but the benchmark jobs run so fast that even on a 1,024-core setup the Dataflow run would cost $28.16 per hour for the Dataflow software and $38.91 per hour for the underlying Compute Engine instances, or $67.07 per hour for both together. (This assumes no data movement charges from the BigQuery service.) At a total of 408 seconds, the Dataflow work would cost about $7.60 to run the test query, compared to $9.07 for the Spark cluster with the same 1,024 cores over 839 seconds. You have to set up and manage the Spark cluster, however, and that is not free.
The issue becomes: What does it cost to run hundreds of concurrent jobs on many thousands of cores, and we think, how will Dataproc running Spark compare to Dataflow with fully burdened Spark licenses added in. Google is charging 1 cent per virtual CPU per hour, which is cheaper than the Dataflow service, which scales with the performance of the instance in GCEUs. We also wonder how this would stack up to the AWS and Azure services running the same benchmark.
Answers always lead to more – and better – questions.
But perhaps the big idea is that the interplay between Dataflow and Spark is healthy, much as the competition between Kubernetes and Mesos has been.
“At their core, Dataflow and Spark are based on the same idea,” says Pointer. “Dataflow also takes in everything that Google has learned in the past few decades with processing big data at scale and exposing it to us as users for the first time. The Spark project doesn’t have those two decades, and it has been doing impressively well considering, but you can’t deny that Google’s experience in this area is unparalleled, and you can see some of that in some of the features that are in the base Dataflow API that allow it to handle data that comes in with its time out of order, which is something that is coming in the next version of Spark. This is something of a cold war between the two, and that is good for the industry.”


ConocoPhillips Sparks Tooling For Seismic HPC, Cloud, AI/ML
Seismic processing and analysis at scale take scalable HPC resources but also need an analytics backend that can scale with massive datasets. And as if that’s not enough, the requirement to provide support, libraries, and formats for emerging AI/ML is an increasingly important need. It is no surprise that Apache …
Google Follows Suit With Microsoft On Ampere Arm Instances
A long time ago, when we first started The Next Platform, Urs Hölzle, then senior vice president of the Technical Infrastructure team at Google, told us that to gain a 20 percent improvement in price/performance it would absolutely change from the X86 architecture to Power architecture – or indeed any …
Google Needs Another Database To Attack Oracle, DB2, And SQL Server Directly
Why does Google need another database, and why in particular does it need to introduce a version of PostgreSQL highly tuned for Google’s datacenter-scale disaggregated compute and storage? It is a good question in the wake of the launch of the AlloyDB relational database last week at the Google I/O …
And why this performance testing was done with Spark 1.3.1 rather than 1.5 or 1.6?
Is it because it’s slower or there are some better reasons?