

The roadmap to build and deploy an exascale computer has extended over the last few years–and more than once.
Initially, the timeline marked 2018 as the year an exaflop-capable system would be on the floor, just one year after the CORAL pre-exascale machines are installed at three national labs in the U.S.. That was later shifted to 2020, and now, according to a new report setting forth the initial hardware requirements for such a system, it is anywhere between 2023-2025. For those who follow high performance computing and the efforts toward exascale computing, this extended timeline might not come as a surprise given key challenges ahead. While the petaflop supercomputers that top the bi-annual list of the world’s fastest systems are yielding tremendous scientific successes now, there are a number of areas in both research and industry that can harness exascale-class computing resources, including cloud-resolving earth system models, multi-scale materials models, and beyond.
The problems with reaching the exascale target in a closer period are not limited to the big issues, including power consumption and programmability. Exascale requires a full-system effort, with improvements of every component, which culminates in power efficiency and programmability.
In an effort to reach exascale, the Department of Energy (DoE), National Nuclear Security Administration (NNSA) and the Office of Science (SC) have extended the efforts included in the FastForward and DesignForward efforts to support exascale computing (funding ends in 2019) into the Exascale Computing Project (ECP), which is the source of the new timeline. The goal of the initiative is to “target the R&D, product development, integration, and delivery of at least two exascale computing systems for delivery in 2023.”
For the purposes of PathForward a capable exascale system is defined as “a supercomputer that can solve science problems 50X faster (or more complex) than on the 20 petaflop systems (Titan and Sequoia) of today in a power envelope of 20-30 megawatts, and is sufficiently resilient that user intervention due to hardware or system faults is on the order of a week on average.” Since these requirements fall far off the Moore’s Law curve that has guided leaps in computational capability for supercomputers, this kind of improvement required is drastic—and comes with far more software-related hitches than before, even with the leap to petascale-class computing.
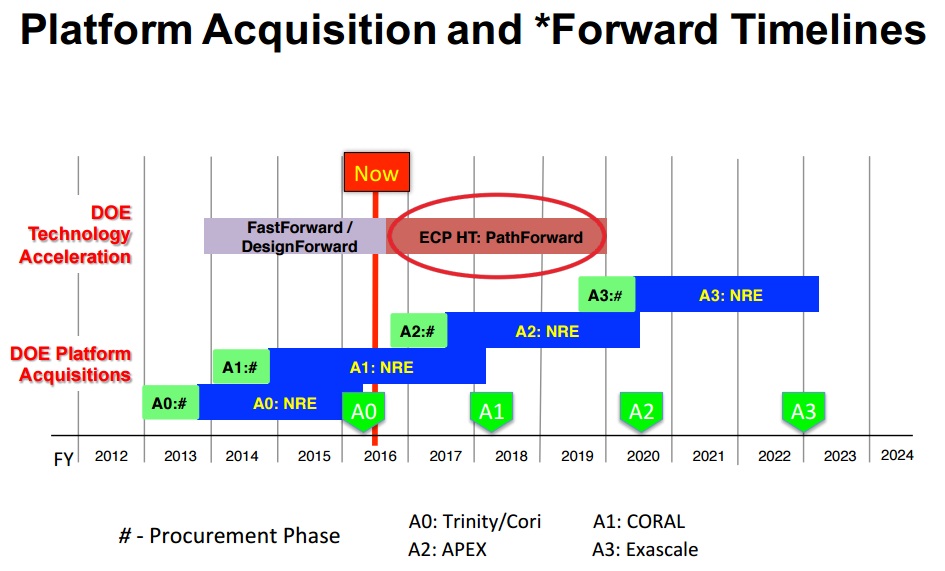
The hardware-focused report cites four major extreme-scale challenges on the hardware side, which we will be focused on in an in-depth series over the next couple of weeks. These include building massive levels parallelism into the code, as well as designing systems that can support this; resilience at scale; memory and storage issues (high capacity and low latency systems on both fronts), and of course, energy consumption.
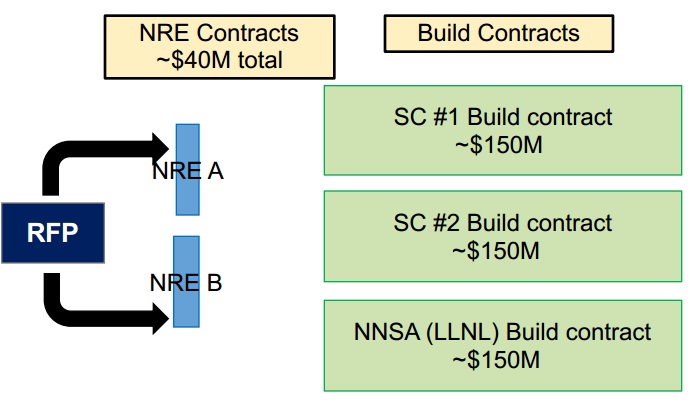
“at least two” separate architectures paths) for three systems. Recall that the total estimated spend for one exascale machine is around $3 billion.
Central to all of these efforts is a co-design approach, which means taking a system-level view against scientific applications and allowing that application focus to guide future architecture and design choices. The ECP will “establish several new co-design centers around common mathematical motifs, in contrast to the ASCR and ASC co-design centers, which were designed around specific applications.”
Leading up the first round of proposals for the system, a process that will begin formally in 2019, is a more important stage—the firming up of technologies across the HPC vendor ecosystem to support such machines. Reviewers will be taking solicitations from vendors focused on key elements of the stack as lead-up technologies in pre-exascale systems in the interim. “While the focus of the R&D should be on exascale systems, if there are interim benefits that could feed into DoE’s upcoming pre-exascale platform requirements, these should be described,” the report notes, pointing to several key conditions.
Reading the list below, it should jump out at you that what is missing in future supercomputers is far less about hardware capabilities and much more about the management of large systems. Ultimately, these are software-driven problems. While the developer challenges are not mentioned here to too much of a degree, that, like power consumption, is one of the “grand scale challenges” ahead as well.
- Designs that simplify changing or upgrading specific node capabilities (e.g., processors, memory, coprocessors) or that enable node substitution in the face of faults that may degrade or kill nodes.
- Mechanisms to increase flexibility in resource utilization such as ways to share memory capacity across nodes.
- Mechanisms to mitigate the tension between production system use, which primarily entails large jobs, and software development for the system, which involves non-computational tasks, such as compilation and short jobs for testing and debugging.
- Designs that facilitate compiling for a mix of heterogeneous nodes.
- Mechanisms to support efficient scheduling of diverse resource types.
- Scalable, adaptive and unobtrustive monitoring, with real-time analysis of platform state.
- Real-time autonomic platform management under production workloads, gracefully handling unplanned events without requiring immediate human intervention.
“Application performance figures of merit will be the most important criteria. The period of performance for any subcontract resulting from this RFP will be through 2019. Proposals shall include descriptions of independently priced work packages that focus on one or more specific component-level enabling technologies related to system or node design. Offerors must describe the path by which their system or node R&D could intersect an HPC exascale system delivered in the 2022-2023 timeframe.”
Although there is a great deal of work to be done to meet the application performance goals stated in the ECP documents, it is useful to see early roadmap planning that confirms there are at least two architectures and at least two machines being planned for the 2023 timeframe. There are already several pre-exascale systems we have covered in detail, including Summit, Sierra, and Aurora (as well as smaller pre-exascale systems in advance of those to prepare), and it is likely these will be setting the architectural stage for what is to come.
Look for our series covering the four challenges in technical deep dives with key stakeholders over the course of the coming two weeks.


Going Beyond Exascale Computing
One thing is certain: The explosion of data creation in our society will continue as far as pundits and anyone else can forecast. In response, there is an insatiable demand for more advanced high performance computing to make this data useful. The IT industry has been pushing to new levels …
A Status Check on Global Exascale Ambitions
As we head toward the annual Supercomputing Conference season we wanted to take a moment for a level-set on exascale. There has been much talk about reaching this pinnacle over the last several years and while plenty of centers say they have reached exascale, that is only for single-precision peak …

Intel Aims For Zettaflops By 2027, Pushes Aurora Above 2 Exaflops
Just because Intel is no longer interested in being a prime contractor on the largest supercomputing deals in the United States and Europe — China and Japan are drawing their own roadmaps and building their own architectures — does not mean that Intel does not have aspirations in HPC and …
Q: What’s Missing in Supercomputing?
A: Seymour Cray
Well played.
Even Seymour decided that FPGAs were the way to future performance. Want to get an exascale system by 2020? Now that Intel bought Altera I can tell you wafer scale FPGAs. Imagine being about to use 100% of every wafer! I published a FPGA wafer scale article over 20 years ago. It’s doable. Just put double floats in the fabric and off you go. I’d bet you can get an exascale system in 1000 square feet.
The soul of high performance computing.
The current program lacks intellect and balance, it is pure marketing and lacks substance. Oh year, Seymour Cray’s contributions while lacking are the tip of the proverbial iceberg of what is missing… applications, modeling, methods, algorithms, applied math, physics,…
What makes supercomputing valuable is modeling & simulation with a purpose. Without it we are wasting our money on expensive hardware. The current program is poorly thought through and intellectually vacuous.
What’s missing in the USA is the economic and societal climate to demand huge systems. Its kind of like the US space program. It became a disorganized joke for a long time. SLS may be the beginning of a renaissance for space after a dark age.
These things do tend to go in cycles, and between 2012 and 2016 there has been a massive slump in HPC. All the new huge systems coming out by 2018 will change the landscape dramatically.
The challenge of the race to exascale will make people focus more than they have been, like the race to the Moon or Space Shuttle program focused people and brought about rapid advancements in technology.
Tadashi Watanabe is still working on supercomputers, and there are still a few other old fashioned people in the field. Their capabilities are going to be appreciated again if people are serious about getting exascale computers working any time soon.