

There are few international supercomputing hubs sporting the systems and software prowess of the Swiss National Supercomputing Center (CSCS), which started with large-scale vector machines in 1992 and moved through a series of other architectures and vendors; from NEC at the beginning, to IBM, and most recently, Cray. In fact, the center has had an ongoing preference for Cray supercomputers, with an unbroken stretch of machines beginning in 2007.
In addition to choosing Cray as the system vendor, CSCS has been an early adopter and long-term user of GPU acceleration. According to the center’s director, Thomas Schulthess, teams there firmed the GPU foundation early, beginning with a proposal in 2008 that pushed for rapid code refactoring across the many application areas served by CSCS in weather, engineering, biosciences, and beyond. The performance of these retooled codes on the Piz Daint supercomputer, which was ranked at #7 on the most recent list of the Top 500 fastest systems, will get a notable boost when the Cray XC30 system becomes the first large-scale installation with the newest Nvidia “Pascal” generation GPUs—4,500 of them to be exact, which will replace the 5272 K20 GPUs.
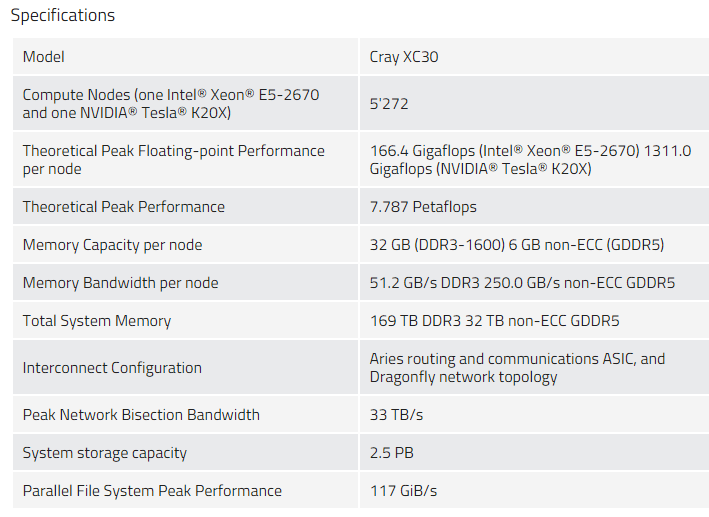
The center made the decision to go with the Cray, GPU-backed architecture when it evaluated what would be required for applications running on Piz Daint in 2012, and while if they had waited long enough, the OpenPower Foundation would have revealed a hybrid GPU supercomputer featuring the intranode NVLink interconnect to avoid the hops over PCIe required on other machines, Schulthess says they likely would have still gone with a Cray system, giving up on the intranode interconnect provided via NVLink.
Schulthess says the current OpenPower systems on the Department of Energy roadmap that feature NVLink and Power 9 are attractive, but for the network performance they are looking for, the Cray choice is still clear. “The OpenPower system at ORNL is very different architecturally than Cray. You have very fat nodes with a relatively weak interconnect between them in that design. Piz Daint has a strong interconnect relative to the power of the nodes and this is one feature we want to maintain—high bi-section bandwidth—especially when compared to the performance of what we see now with the OpenPower path.” Schulthess says, “it’s really about balance and what we see in the next year or two does not come close.”
Schulthess tells us that the center has test systems sporting NVLink on site already for development purposes, but that teams are most interested in getting the Pascal nodes on the floor for the boost in memory performance, something that is increasingly more important than the floating point advantages that also come with Pascal. “From a system balance perspective, the fact that with the original architecture [Sandy Bridge and Nvidia K20] teams were stuck in PCIe Gen 2, but after the upgrade, they will be able to switch to Gen 3. “The GPU can hide a lot of latency and since we invested early in programming models to support a machine like this, we are expecting a great deal more performance.”
Schulthess tells The Next Platform that the upgrade will bolster CSCS’s ability to crunch Large Hadron Collider data, push current research on the Human Brain Project’s High Performance Computing and Analytics platform, which is rooted to Piz Daint, as well as run a large cadre of other scientific codes for European institutions. The first iteration of Piz Daint in spring 2012 was CPU only. Following an upgrade in 2012 to include an Nvidia Tesla K20 GPU on almost all nodes, Schulthess says the performance jump was massive, particularly for weather codes used throughout Europe, including COSMO.


Tesla GPU Accelerator Bang For The Buck, Kepler To Volta
If you are running applications in the HPC or AI realms, you might be in for some sticker shock when you shop for GPU accelerators – thanks in part to the growing demand of Nvidia’s Tesla cards in those markets but also because cryptocurrency miners who can’t afford to etch …
Just How Large Can Nvidia’s Datacenter Business Grow?
The combination of the excitement for new video games, the machine learning software revolution, the buildout of very large supercomputers based on hybrid CPU-GPU architectures, and the mining of cryptocurrencies like Bitcoin and Ethereum have combined into a quadruple whammy that is driving Nvidia to new heights for revenues, profits, …

Nvidia Breaks $2 Billion Datacenter Run Rate
If GPU acceleration had not been conceived of by academics and researchers at companies like Nvidia more than a decade ago, how much richer would Intel be today? How many more datacenters would have had to be expanded or built? Would HPC have stretched to try to reach exascale, and …
Be the first to comment