
As readers of The Next Platform are well aware, Hewlett Packard Enterprise is staking a lot of the future of its systems business on The Machine, which embodies the evolving concepts for disaggregated and composable systems that are heavy on persistent storage that sometimes functions like shared memory, on various kinds of compute, and on the interconnects between the two.
To get a sense of how The Machine might do on in-memory workloads that normally run on clusters that have their memory distributed, researchers at HPE Labs have fired up the Spark in-memory framework on a Superdome X shared memory system, and as you might expect, Spark can bet tweaked and tuned to run a lot faster on a big bad NUMA box.
The thing to remember about Spark is that even though it is an in-memory computing framework that runs across multiple nodes in a cluster, it is still back-ended by disk storage on the server nodes, April Slayden Mitchell, director of programmability and analytics workloads at HPE Labs, explains to The Next Platform. The team that Slayden Mitchell runs is keen on exploring the programmability and performance issues relating to memory-driven computing and universal memory, as HPE is calling the storage inside of The Machine.
“We chose Spark as a test case because it is in-memory analytics on distributed systems, but when we are aiming at The Machine, which will have a shared memory pool, we want to know if it can run better when the memory capacity is much larger than what is possible on a typical distributed cluster,” says Slayden Mitchell.
It doesn’t hurt that Spark is also one of the fastest-growing open source projects in history, in terms of the number of contributors, and is a core framework for handling streaming, machine learning, SQL query, and graph processing workloads on unstructured data in-memory to boost performance. While the processing is done in memory, several parts of the architecture are nonetheless dependent on disk drives in the servers and latency between the I/O subsystems and the network interfaces between nodes in the clusters. Some of those latencies can be mitigated by running a framework like Spark on a shared memory box like Superdome X, which has a chipset that comes off of the Xeon E7 QuickPath Interconnect that is used to link CPU sockets together that has much higher bandwidth and much lower latency than the typical Ethernet or InfiniBand network. HPE specifically targeted Spark jobs that were reliant on memory bandwidth and that would not run well over standard networks that link nodes on clusters.
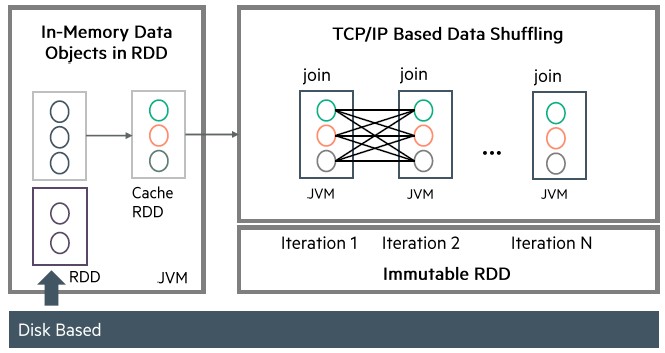
Jun Li, principle research scientist at HPE Labs who worked on the modifications to the Spark framework to leverage the shared memory pool, and also tweaked Spark so data objects were loaded directly from the shared memory pool instead of from a disk-based file system like the Hadoop Distributed File System. HPE software engineers added an in-memory shuffle engine that does sorting and merging in memory and optimizes for CPU access to caches on the Xeon E7 processors in the Superdome X machine. These, and other tweaks, are being added upstream to the Spark code base in conjunction with commercial Hadoop distributor Hortonworks.
HPE did not compare the performance of Spark running on a distributed cluster using Xeon E5 processors to running on the machine, but rather running raw Spark on a Superdome X server to one that had been tuned to not using disk or TCP/IP to communicate. Here is how the performance improved on the in-memory shuffle:
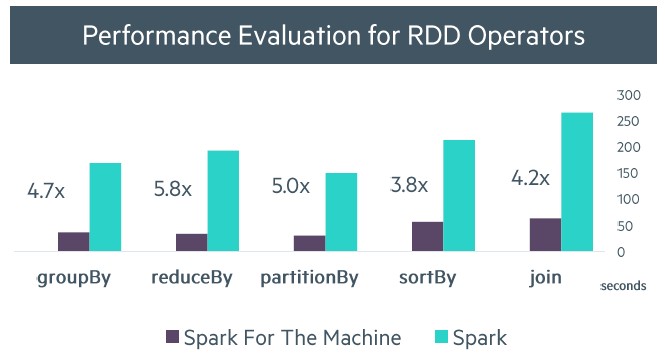
In the chart above, the data labeled “Spark For The Machine” is really the Superdome X system, since HPE is not actually shipping The Machine. The Superdome X is a proxy, and this is really not accurate labelling at all. But the speedup on various sorting and merging routines ranges from 3.8X to 5X, which is a pretty good boost. (We expect that on a real cluster, the increase in performance would be much more dramatic.)
HPE also add on off-heap memory store, which allows for Spark objects to be cached in DRAM in the Superdome X test machine (and in theory on NVM storage of some kind on The Machine in the future) and not inside of the Java Virtual Machine heap, which has its own bottlenecks. By doing this, the Superdome X setup could have one set of Resilient Distributed Datasets (RDDs) instead of a bunch of them spread across a network of the nodes in the system, which reduced garbage collection overhead in the Java environment. And in the test with the GraphX graph processing overlay for Spark, the Superdome X running the tweaked code doing a web graph of 101 million nodes with 1.7 billion edges had a 15X speedup, dropping from 201 seconds down to 13 seconds, with 5X of that performance boost coming from the off-heap memory store.
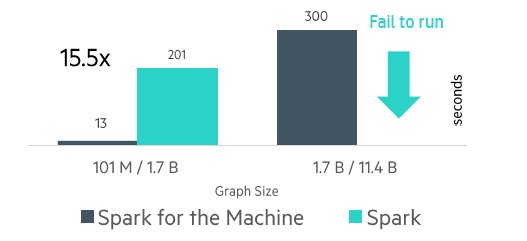
As you can see from the chart above, on a larger run with the predictive analytics workload running, which had 1.7 billion nodes and 11.4 billion edges in the graph, the unmodified Spark setup analytics failed and the tuned Spark on Superdome X setup ran in 300 seconds.
Li says that the modified version of the Spark that has been optimized for shared memory systems, particularly on workloads that had a lot of shuffling of data across nodes, should not curtail performance when running on actual Xeon clusters with multiple nodes and distributed memory. By the way, this particular system had a sixteen “Ivy Bridge” Xeon E7 processors, each with fifteen cores for a total of 240 cores, and 12 TB of memory; the machine ran Red Hat Enterprise Linux. If HPE had doubled up the main memory to 24 TB, the maximum size of the graph would be doubled and you could cache more data to memory; it might not necessarily speed up the graph analysis, which could take more cores.
HPE did not test an actual Spark cluster with a six nodes and the same number of Xeon E5 cores in it as were in the Superdome X machine. This would have been interesting indeed, and perhaps more illustrative of the benefits of a shared memory machine over clusters for certain analytics workloads. HPE was not in a position to provide such comparisons, but these will need to be made, obviously, if HPE wants to convince customers to run Spark on big iron, as both IBM and SGI are doing these days with their respective Power Systems E870/E880 and UV 300 machines.
“If you have a ten node cluster running the benchmark with a 10 Gb/sec Ethernet network and it is working, as you grow the problem size the memory requests will saturate the network very quickly,” says Li, but again, HPE has not tested this scenario. “But with the Superdome X, we have QPI links that run at 32 GB/sec, and it is not easy to saturate these links.”
We suggested that customers wanting to boost Spark performance might be to move to a relatively small number of fat nodes, with lots of compute and memory, and also shift to 100 Gb/sec Ethernet or InfiniBand, but the whole idea of frameworks like Spark is to avoid paying the NUMA and memory capacity premium that come from such systems. Well, it was at least until a system like The Machine comes along and brings to bear some of the properties of shared memory systems and clusters.
HPE will be releasing prototypes of The Machine based on DRAM memory instead of persistent NVM of one flavor or another before the end of the year, and it will be very intriguing to see how these prototypes stack up against Superdome X servers running the modified Spark stack that HPE has cooked up. Further down the road, expect a fully tuned implementation of Spark running on the production-grade version of The Machine and its non-volatile storage. In the meantime, if you have a complex graph analytics workload with a large dataset, Slayden Mitchell says that as far as buying an actual Superdome X goes, “people should absolutely be considering this” and that shared memory machines “are creating a new class of opportunities” for specific Spark use cases.
This situation is analogous to what happens in some HPC centers, where there are lots of skinny nodes that do the bulk of the compute but a few fat nodes get memory-intensive workloads dispatched to them. And HPE’s engineers are willing to architect a Spark or any other kind of analytics stack that might benefit from NUMA on top of Superdome X. You don’t have to wait for The Machine to do better than a Xeon cluster.

Cray-Now-HPE Issues Network Performance Challenge – And Cooperation – With GPCNeT Benchmark
It happens all the time. There is a performance problem, and everyone blames the network. Supercomputing is no different, and given that massively parallel machines are largely defined by their interconnects even though compute represents the largest portion of a system’s budget and is what people talk about most, when …
Now Storage Jumps Into HPE’s GreenLake
There has been a land rush of sorts by storage OEMs over the past few weeks to roll out systems and services designed to help enterprises manage and process the huge amounts of data that is being created and stored throughout their widely distributed IT environments. Organizations not only are …

HPC In 2020: Acquisitions And Mergers As The New Normal
After a decade of vendor consolidation that saw some of the world’s biggest IT firms acquire first-class HPC providers such as SGI, Cray, and Sun Microsystems, as well as smaller players like Penguin Computing, WhamCloud, Appro, and Isilon, it is natural to wonder who is next. Or maybe, more to …
Be the first to comment