

It is hard to find a more hyperbolic keynote title than, “A New Computing Model” but given the recent explosion in capabilities in both hardware and algorithms that have pushed deep learning to the fore, Nvidia’s CEO keynote at this morning’s GPU Technology Conference kickoff appears to be right on target.
If the title could be tweaked an even more pressing reality, it might read that this is the “convergence” of a new computing model, versus one that is being born from the dust. After all, without advances across the board; from energy-efficient multi-core processing and acceleration, algorithmic developments from hyperscale companies and universities, and companion developments in analytics and data within enterprises and their expanding need for intelligence, we would not be at the base of this steep incline to the peak of deep learning possibilities. While this area might be dominated by rather consumer-oriented products and services now (instant classification of user photos or rapid mobile translation), there are enormous possibilities for “superhuman” analytics in enterprise and beyond.
As we have covered in depth here in several articles in The Next Platform, there have been critical convergences taking place within the hardware and software stacks, as well as outside of the datacenter, including the addition of new data sources, algorithmic approaches, and frameworks that have created entirely new platforms for development of the future of deep learning in broader arenas than “mere” image or speech recognition. Formerly disparate spheres of computing are now meshing, creating opportunities to blend high performance computing, hyperscale, and general enterprise platforms into a new, tailored systems. And accelerators, which were once the sole domain of either tiny embedded systems or massive-scale supercomputers, are becoming far more common—a change that will be enhanced with the addition of FPGAs into the competitive landscape in an entirely new, far more prescient way.

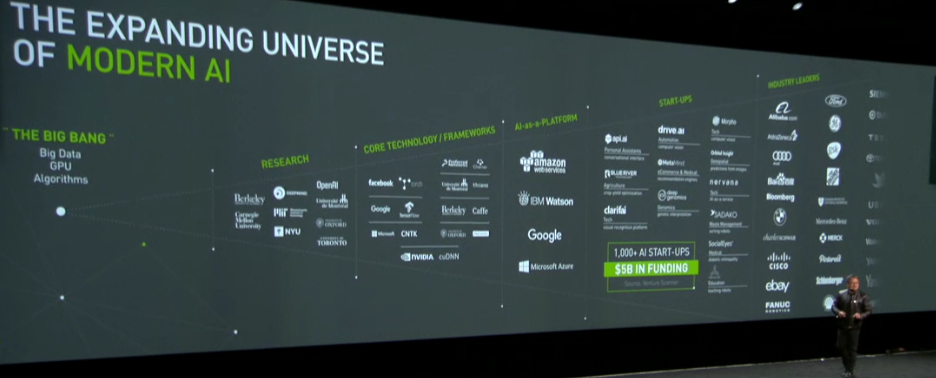
Today even more firmly establishes Nvidia as a hardware key in a market that CEO, Jen-Hsun Huang cited in his keynote will represent a $500 billion opportunity over the next decade—complementing the $5 billion that has already been invested in the last five years, resulting in the propulsion of over one thousand startups focused on artificial intelligence and deep learning.
“2015 is going to be the year we look back on as one of the most important in deep learning,” Huang says, noting that the coming year will be one that “will be a defining year for AI, computer science, the computer industry, and likely humanity as a whole.” He spent time highlighting some of the key deep learning advances that have splashed across the pages of every major tech publication over the last year, including successes with ImageNet, the AlphaGo competition, and developments in building smart machines and robots that can learn to execute tasks, but the best is ahead—a whole new generation of applications powered by ever-more specialized acceleration hardware and increasing algorithmic development to enable new use cases and markets for deep learning.
In short, on the systems side, the times they are changing—and Nvidia has done a rather remarkable job of encapsulating those shifts in their introduction of Pascal and the deep learning-focused P100, as well as with inference-driven devices like the Jetson TX1, which we will describe in far more depth in a bit. Before all of that, and perhaps more broadly important, is the fact that the company is placing a stake in the ground—an even bolder one than it did late in 2015 with the addition of the Tesla M40 and M4 processors for acceleration of deep learning workloads.
“Deep learning is no longer just a field. It’s no longer just an app. And it’s no longer just an algorithm. It’s way bigger than any of that, and this is one reason we have been going all in with deep learning. Every year we do more. We think this is going to utterly change computing—it’s a brand new computing model.”
Although Nvidia released two chips last year, the M40 and M4 for training and inference of deep neural networks, the company is boosting the appeal on the inference side with the addition of a new library called the GPU Inference Engine (GIE), which does for inference what cuDNN does for training neural nets on a GPU. Using the company’s low-power Jetson TX1, they were able to benchmark the inference side of the image recognition pipeline in what used to be four images per second per watt to 24 images per second per watt.

The performance jump is one noteworthy aspect, but one of the biggest complaints we have heard from the few companies who would speak with us about using GPUs for the inference part of deep learning workloads (Baidu in particular and as noted in our discussion with deep learning pioneer, Yann LeCun) was that they consumed far too much energy to be used beyond training.
In Huang’s words, “there is no reason to use an FPGA” which raised some eyebrows—but it was a comment targeted at the fact that this is where FPGAs have been expected to shine given their low power consumption and programmability (even if the word “programmability” should be in quotes).
The real star of the GTC show for deep learning, but also hyperscale datacenters and high performance computing shops, is the Pascal architecture which, as anticipated, debuted today. The P100 chip, as we will provide great deal about in the next hour or two (stay tuned), is set to be quite a workhorse for both training and inference—it will remain to be seen how centers integrate this into deep learning workflows and what happens to the M40 and M4 over time if a more general purpose, non-bifurcated product is set in front of them.
For now, the cloud builders are the first ones to get an initial wave of P100 GPU accelerators, with the rest of the world shortly behind. Check back in the next hour for far more about this architecture and how Nvidia expects to wrap this across multiple market segments—segments that continue to merge and converge with each passing year, which is very fortunate for a company like Nvidia.




More consumers are using GPS Tracking Devices each and every day.
Four years later, the Black – Berry smartphone was launched in Germany.
Alexander pointed out that this product is very revolutionary and
is an achievement that will help in curbing energy consumption to a great extent.