

The IT industry spends a lot of time obsessing about Moore’s Law and whether it is alive well or heading for the old folks home. This is just another way of asking if chip manufacturers can still offer better bang for the buck on processing as they wrestle with the limits of physics and software’s ability to spread work around increasingly ornate compute elements.
The answer to that question is a complex one, with shrinking transistors being used to add more compute elements to a processor, better ones, or a mix of the two. We took a stab at trying to calculate the improvements Intel has made in the past six generations of processors in the wake of its announcement last week of the “Broadwell” Xeon E5-2600 v4 processors, the new motors for the workhorse two-socket server that is the most common server platform in the datacenter these days. The Broadwell Xeons made their public debut at a big shindig that the chip maker hosted in San Francisco, which focused mostly on Intel’s aspirations in helping the world build tens of thousands of public and private clouds, and as it turns out, the hyperscalers have been using them for the past four months.
Might doesn’t make right, but it helps.
With each successive Xeon processor generation, the number of features that the chip supports goes up, sometimes in big jump and sometimes in little steps, but there is always this forward motion of progress where hardware is implemented to do something better or quicker than can be done in software. (Yes, it works that way, not the other way around.) As we pointed out in our analysis of the Broadwell Xeon cores, the amount of innovation that Intel has crammed into the chips to boost the number of instructions per clock (IPC) that it can process in recent generations is impressive, and if you use the “Dothan” Cores used in the Pentium M mobile processors and earlier generations of Xeons back in 2004 as a baseline, then the IPC across the past eight generations has gone up by nearly a factor of 1.8X in the past twelve years. (This is single thread performance normalized for clock speed, and reflective of the underlying architecture changes.) Broadwell cores had about a 5.5 percent IPC improvement over the prior “Haswell” Xeon cores, and if history is any guide, the “Skylake” Xeon cores coming maybe late next year should yield somewhere around a 10 percent improvement in IPC over the Broadwells. So that will represent just about a doubling in IPC performance compared to the Dothan cores way back when.
But Intel doesn’t just change the architecture of the cores. It also integrates other components onto the die, such as PCI-Express and Ethernet controllers and voltage regulators (which reduces bills of material for server makers and improves price/performance of the systems as well as reliability), and adds cores and caches with its ever-increasing transistor budget to try to boost the overall throughput of the Xeon processor with every generation.
The interplay of clocks, cores, cache, and IPC are what drive performance gains with each Xeon family, and dialing these different aspects up and down makes for a product line that can seemingly fit just about any workload Intel’s customers can imagine. But, which chips in each line offer the best bang for the buck? And how has the value proposition of the Xeon processors changed over time? That’s what we want to know. So we got out our trusty spreadsheet and did a little math.
The overall throughput of any processor is more or less gated by the aggregate number of cores and the clocks they can cycle. Aggregate clocks is a rough indicator of relative performance within a Xeon family, but is not necessarily good across families. Luckily for us, we know the IPC improvement factors with each core generation, and knowing this we can do a rough reckoning of the relative performance of processors dating back to the Dothan cores if we want to. It is not particularly useful to go back that far since there are very few of those machines in the field today, but there are still probably machines using the “Nehalem” Xeon 5500s out there in some datacenters. And besides, the Nehalem marked a big change in architecture that the entire server industry got behind just as the Great Recession was starting and AMD was having issues with its Opterons. Nehalem is the touchstone against which all Xeons should be measured because this is when Intel got rid of so much technical baggage that had been holding the Xeons back.
So, for fun and to enlighten ourselves about the relative performance and bang for the buck for the last six generations of Xeons, we came up with a relative performance metric – called Rel Perf in the following tables – that takes into account the aggregate clocks and improving IPC of each generation. The performance of each Xeon in those six generations is calculated relative to the performance of the Xeon E5540, the four-core Nehalem part introduced in March 2009 that was the top of the standard performance part of the Xeon line. And the cost per unit of performance, or $ / Rel Perf, is the price of the chip at list price divided by this calculated relative performance. With this simple metric, we can compare the oomph and bang for the buck across the Xeons – albeit in a very rough way. We are working to get the full integer, floating point, and database performance metrics for these Xeon families, which Intel collects. This is just a beginning, not an end. And, as usual, such data as we are presenting is meant to give you a starting point from which to make your own application benchmarking decisions, not purchasing decisions. You should always run your own tests.
To get going, take a look at the initial Nehalem Xeon 5500s:
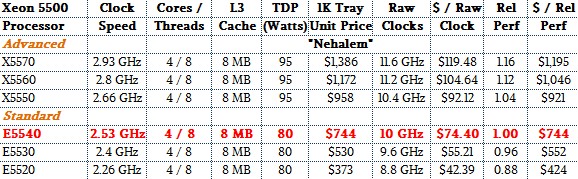
We do not have all of the Xeons in here, just the main ones that were used in hyperscale, HPC, cloud, and large enterprise datacenters. The Xeon E5540 is shown in red, and while that was a pretty impressive chip at the time – what Intel called “transformational” and indeed it was – it seems pretty simple by comparison.
The most obvious thing is that the performance delta between the low end of the standard range and the high end of the advanced range (we are using Intel’s modern sub-classes for Xeons to discuss chips that did not originally have those labels) was not huge. The reason is simple: ramping up clock speed didn’t get anyone much except hotter chips. But the price Intel charged (admitted these are list prices for single units when bought in 1,000-unit trays) for those performance bumps were quite large. The top-end Nehalem Xeon X5570 had about 16 percent more performance than the Xeon E5540, but it cost 60.5 percent more per unit of performance. Ouch. Conversely, the slower you let a Nehalem Xeon 5500 go, the better the bang for the buck because Intel dropped the price a lot faster than the clock speeds.
With the jump to the “Westmere” Xeon 5600s two years later in March 2010, Intel did not monkey around with the core design and simply moved from four to six cores and from the 45 nanometer processes used with the Nehalem Xeons to the then-current and mature 32 nanometer process.
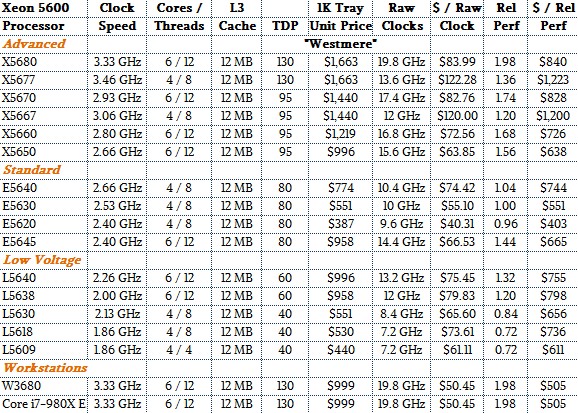
As part of the transistor shrink, Intel also bumped up the maximum L3 cache to 12 MB, which was a 50 percent jump that mirrored the 50 percent rise in core counts. The power budget was expanded in the server designs, too, and Intel ramped up the clock speeds as well as the core counts to give customers more raw throughput. If you compare the top-end Xeon X5680 that came out in March 2010 to our baseline Xeon E5540, that six-core Westmere top binner delivers just a tad under twice the performance. But customers paid for it, too. The bang for the buck of this chip was $840 per unit of performance, which was 12.8 percent higher (higher is worse, lower is better). We will get into generational comparisons across common SKUs in a bit. But generally speaking, as we came out of the Great Recession in 2010, server virtualization was on fire and companies were trying to cram as many virtual machines as they could onto machines, and Intel could – and did – charge for that incremental capacity because it saved customers so much in terms of server acquisitions and operational costs.
Two years later, in March 2012, the “Sandy Bridge” Xeon E5-2600 v1 processors came out, and this being a “tock” in Intel’s two-cycle chip rollout methodology, the company stayed with the 32 nanometer process that had been ramped with Westmere.
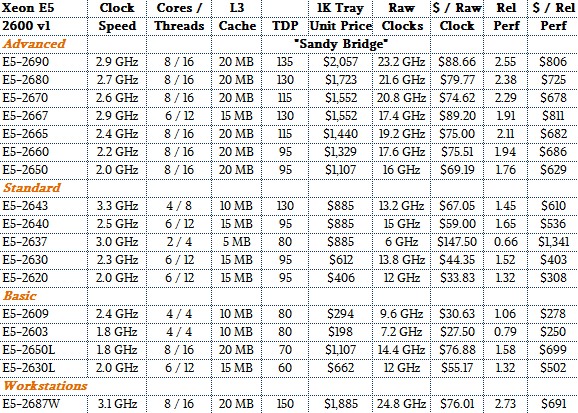
With the Sandy Bridge design, Intel implemented rings to interconnect the L3 cache segments and cores, positioning itself for a massive expansion in core counts in the coming years. The Sandy Bridge Xeons topped out at eight cores and 20 MB of L3 cache, and came in variants that pushed core counts, clock speed, low heat, and other factors to suit various customers. It was here that Intel started making custom variants for hyperscaler and HPC customers, by the way.
The “Ivy Bridge” Xeon E5-2600 v2 chips launched in September 2013, with a shrink to 22 nanometer “TriGate” FinFET processes and representing a “tick” in the Xeon cycle.
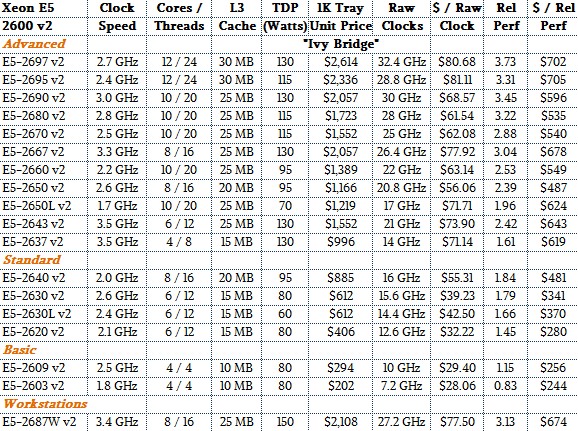
The top-bin Ivy Bridge Xeon E5-2697 v2 packed twelve cores running at 2.7 GHz and had 30 MB of L3 cache on a die; it offered about 3.7X the performance of that baseline Nehalem E5540 we used as a normalizer and it had a much lower cost per unit of relative performance, too. Generally speaking, the Ivy Bridge chips allowed Intel to give a lot more performance per dollar, and at the same time it charged more per chip, SKU for SKU, and both Intel and its customers benefited from splitting the difference.
With the Haswell Xeon E5-2600 v3 chips, which launched a year later in September 2014, Intel did major microarchitecture improvements and expanded the core count to a maximum of 18, and the relative performance of the top-end Xeon E5-2699 v3 part is about 5.2X that of the baseline Nehalem E5540. This monster chip cost $4,115 at list price, and the cost of a unit of performance was actually higher than for that baseline Nehalem. (Not adjusted for inflation, of course. But we could do that if we wanted to be really thorough.
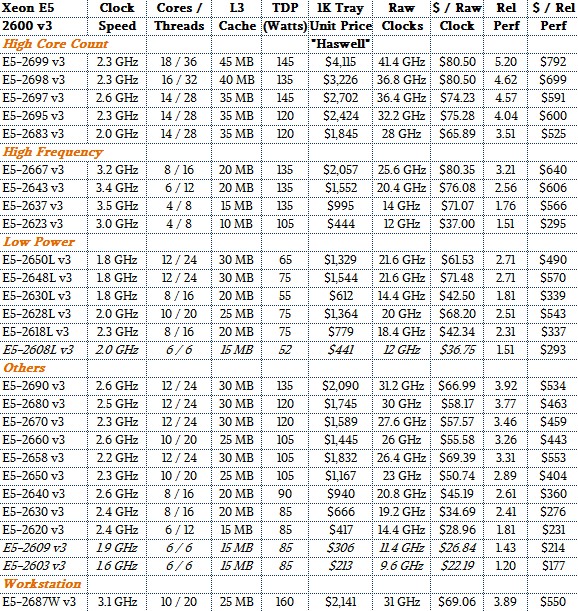
And that, of course, leads us to the current Broadwell Xeon E5-2600 v4 processors, which are outlined below with our Rel Perf metrics added:
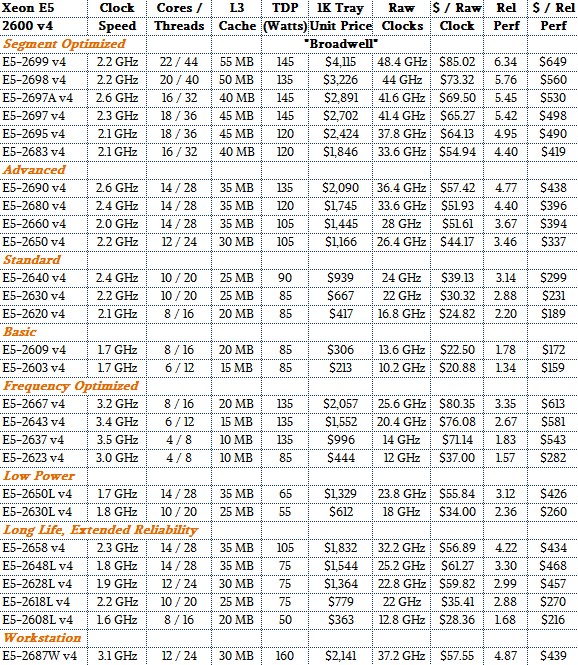
So there you have it. All of the Xeon E5 parts for the past six generations (excepting some Nehalems), with their relative performance and relative bang for the buck. You can play at will with these numbers.
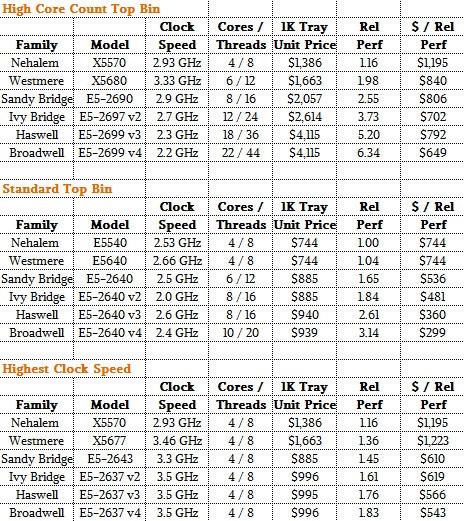
To make a few points, we aggregated some of the data by generations, looking at three different classes of processors across those families of Xeon chips. Specifically, we peeled out chips with high core counts for massively threaded jobs, standard parts that fit mainstream customers, and variants that stressed high clock frequency over core counts to boost single-threaded performance as much as feasible given the power and thermal budgets in systems.
Here is the summary table for these three workloads, with the relevant Xeon SKUs. We make no claim that this is a perfect representation, which is why we have given you all of the raw data that we have.
We think better in pictures sometimes, so here is what it looks like if you plot the relative performance gains for the high core count parts across the generations and the relative price/performance of those processors:
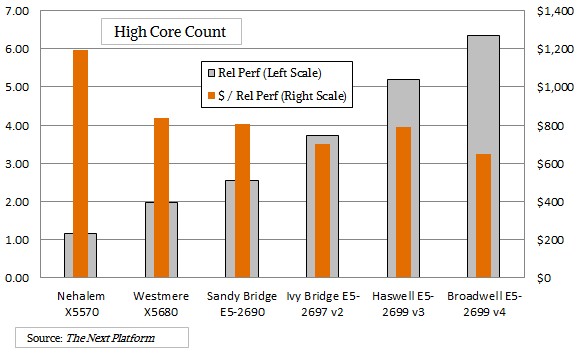
As you can see, the performance gains were a little less steep for these top-bin parts but have accelerated a bit in more recent generations. The price per unit of performance these high core count chips came down sharply with the Westmere designs, flattened with the Sandy Bridge Xeon, and actually went up a bit for the top-bin Haswell.
You can do that when your customer is more or less captive to the X86 architecture and AMD can’t put an Opteron in the field. If you want to know why Google helped start the OpenPower Foundation, just look at that bump. And look how the price per unit of performance has seemingly magically come down with the 22-core Broadwell Xeon, which did not get a price increase over the 18-core Haswell Xeon. If Power8+ and Power9 are reasonable chips, and the ARM collective puts some heat on Intel – possibly with Qualcomm taking the lead there for single-threaded performance – then that price per unit of performance could come down a bit further. But the thing to remember is that these high-core count parts really mean that companies like Google, Amazon Web Services, Cray, and others can put almost twice as much compute capacity into a single node as they could do with a mid-SKU, more standard part. That is a lot of savings on node count, management, and so forth. Moreover, workloads like HPC, data analytics, and the server virtualization that underpins public clouds work best when you have a very large compute element that you can dice and slice up work on or just push through in massive gulps.
The story with the standard Xeon parts over the generations is a bit different, as you can see here:
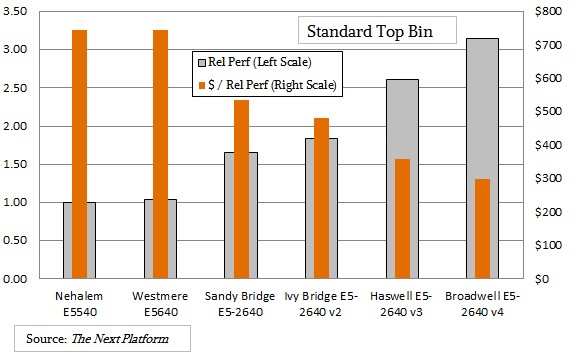
The move from Nehalem to Westmere for the standard four-core chips didn’t really get customers much in terms of a performance boost or better value. But the move to a six-core Sandy Bridge in this class of chips boosted performance by 65 percent and improved the value by 28 percent even as the price per chip went up by 19 percent. Intel held the price steady with the Ivy Bridge version in the same place in the SKU rankings, and relative performance rose by 10.3 percent, and with the Haswells versions of this SKU, clock speeds went up along with IPC as core counts stayed at eight and the performance went up by 25 percent and the relative value of a unit of compute improved by 6 percent. Intel is banking again and again that more compute per unit of floor space is more important than lower prices – and its 50 percent gross profits in the Data Center Group suggest that this interpretation is absolutely correct. With a standard-class Broadwell Xeon E5-2640 v4 chip, the price is the same, the performance is up 17 percent, and the price per unit of performance is below $300 – less than half of what it charges for a high core count part in the Broadwell line.
Not everybody wants a standard part or a high core count part that pushes the limits. Some customers, particularly in high frequency trading in the financial services sector, having high clock speeds is more important. And Intel has SKUs with fewer cores on the die and with fewer of those cores activated where it can ramp up the frequencies to try to meet the needs of these customers.
Here is what the high clock speed trend looks like over time between the Nehalem and Broadwell generations for the fastest parts available in the commercially available line:
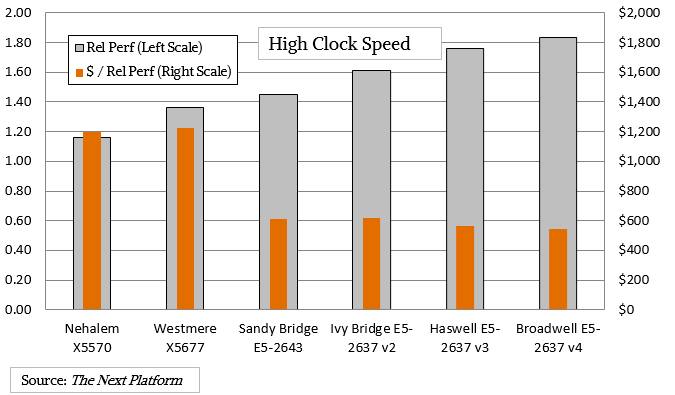
We know that Intel does custom chips where it lets companies run them faster and hotter, sometimes with a three-year warranty instead of a five year one, as it is doing with the custom Xeon-D processor employed by Facebook in its “Yosemite” microserver for its infrastructure workloads, just to name one example.
As you can see, and as you expect given the fact that servers can’t have chips with 2,000 watt thermal design points, squeezing out higher clock speeds and driving single-threaded performance with that and IPC together is a challenge. But Intel, to its credit has made some progress, with a four-core Broadwell E5-2637 v4 running at 3.5 GHz delivering about 58 percent more aggregate performance than a four-core Nehalem Xeon X5570 running at 2.93 GHz. Importantly, the cost per unit of performance has dropped here by more than half, so Intel is giving customers better value through lower prices more than through performance boosts. It doesn’t really have much choice in this regard, and customers know this, too. But the bang for the buck has not changed much over the past three generations. In a sense, Moore’s Law has stopped here.
We are hunting down the performance specs for integer, floating point, and database workloads and will share as soon as we catch them.


Intel To Set Its FPGA Unit Free To Pursue Its Own Path
Maybe Intel chief executive officer Pat Gelsinger has spent too much time at EMC and VMware. Because now Intel wants to spin out the FPGA business that is a small but bright spot in its datacenter and edge computing businesses. It never made a lot of sense that EMC, the …
The Era Of Big Memory Is Upon Us
If you reduce systems down to their bare essentials, everything exists in those systems to manipulate data in memory, and like human beings, all that really exists for any of us is what is in memory. We can augment that memory with external storage that preserves state over time, but …

The CXL Roadmap Opens Up The Memory Hierarchy
The system world would have been a simpler place if InfiniBand had fulfilled its original promise as a universal fabric interconnect for linking all manner of devices together within a system and across systems. But that didn’t happen, and we have been left with a bifurcated set of interconnects ever …
Excellent article! It would be wonderful if there will be a follow up with 1S cpus. 🙂 (and maybe add into the mix approximated prices for systems, in order to have system costs $/rel perf )
Thank you!
Basic E5 v4 CPUs (2603 and 2609) have 1 thread per core – not 2.
Total GHz is a not a very good proxy of performance for any real-life workload.
At the system level fixed cost of chassis + motherboard + OS license (typical in corporate environment – where most of those CPUs are used) change considerably price/performance ranking based on CPU price.
Nicely done! Thanks!
I believe these are the 2 socket SKUs. Can you do a similar comparison on the 4 socket SKUs?
Thanks.
It’d be interesting to see the performance increases across these generations normalizing for core count and MHz to get a gauge of how much more efficient each generation might be relative to its ancestors.