

Nallatech doesn’t make FPGAs, but it does have several decades of experience turning FPGAs into devices and systems that companies can deploy to solve real-world computing problems without having to do the systems integration work themselves.
With the formerly independent Altera, now part of Intel, shipping its Arria 10 FPGAs, Nallatech has engineered a new coprocessor card that will allow FPGAs to keep pace with current and future Tesla GPU accelerators from Nvidia and “Knights Landing” Xeon Phi processors and coprocessors from Intel. The architectures of the devices share some similarities, and that is no accident because all HPC applications are looking to increase memory bandwidth and find the right mix of compute, memory capacity, and memory bandwidth to provide efficient performance on parallel applications.
Like the Knights Landing Xeon Phi, the new 510T uses a mix of standard DDR4 and Hybrid Memory Cube (HMC) memory to provide a mix of high bandwidth, low capacity memory with high capacity, relatively low bandwidth memory to give an overall performance profile that is better than a mix of FPGAs and plain DDR4 together on the same card. (We detailed the Knights Landing architecture a year ago and updated the specs on the chip last fall. The specs on the future “Pascal” Tesla GPU accelerators, such as we know them, are here.)
In the case of the 510T card from Nallatech, the compute element is a pair of Altera Arria 10 GX 1150 FPGAs, which are etched in 20 nanometer processes from foundry partner Taiwan Semiconductor Manufacturing Corp. The higher-end Stratix 10 FPGAs are made using Intel’s 14 nanometer processes and pack a lot more punch with up to 10 teraflops per device, but they are not available yet. Nallatech is creating coprocessors that will use these future FPGAs. But for a lot of workloads, as Nallatech president and founder Allan Cantle explains to The Next Platform, the compute is not as much of an issue as memory bandwidth to feed that compute. Every workload is different, so that is no disrespect to the Stratix 10 devices, but rather a reflection of the key oil and gas customers that Nallatech engaged with to create the 510T card.
“In reality, these seismic migration algorithms need huge amounts of compute, but fundamentally, they are streaming algorithms and they are memory bound,” says Cantle. “When we looked at this for one of our customers, who was using Tesla K80 GPU accelerators, somewhere between 5 percent and 10 percent of the available floating point performance was actually being used and 100 percent of the memory bandwidth was consumed. That Tesla K80 with dual GPUs has 24 GB of memory and 480 GB/sec of aggregate memory bandwidth across those GPUs, and it has around 8.7 teraflops of peak single precision floating point capability. We have two Arria 10s, which are rated at 1.5 teraflops each, which is just around 3 teraflops total but I think the practical upper limit is 2 teraflops., but that is just my personal take. But when you look at it, you only need 400 gigaflops to 800 gigaflops, making very efficient use of the FPGA’s available flops, which you cannot do on a GPU.”
The issue, says Cantle, is that the way the GPU implements the streaming algorithm at the heart of the seismic migration application that is used to find oil buried underground, it makes many accesses to the GDDR5 memory in the GPU card, which is what is burning up all of the memory bandwidth. “The GPU consumes its memory bandwidth quite quickly because you have to come off chip the way the math is done,” Cantle continues. “The opportunity with the FPGA is to make this into a very deep pipeline and to minimize the amount of time you go into global memory.”

The trick that Nallatech is using is putting a block of HMC memory between the two FPGAs on the board, which is a fast, shared memory space that the two FPGAs can actually share and address at the same time. The 510T is one of the first compute devices (rather than networking or storage devices) that is implementing HMC memory, which has been co-developed by Micron Technology and Intel, and it is using the second generation of HMC to be precise. (Nallatech did explore first generation HMC memory on FPGA accelerators for unspecified government customers, but this was not commercially available as the 510T card is.)
In addition to memory bandwidth bottlenecks, seismic applications used in the oil and gas industry also have memory capacity issues. The larger the memory that the compute has access to, the larger the volume (higher number of frequencies) that the seismic simulation can run. With the memory limit on a single GPU, says Cantle, this particular customer was limited to approximately 800 volumes (it is actually a cube). Oil and gas customers would love to be able to do 4K volumes (again cubed), but that would require about 2 TB of memory to do.
So the 510T card has four ports of DDR4 main memory to supply capacity to store more data to do the larger and more complex seismic analysis, and by ganging up 16 cards together across hybrid CPU-FPGA nodes, Nallatech can break through that 4K volumes barrier and reach the level of performance that oil and gas companies are looking for.
Here is the block diagram of the 510T card:
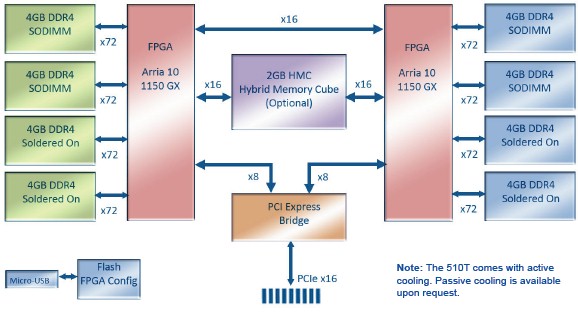
The HMC memory comes in 2 GB capacity, with 4 GB being optional, and has separate read and write ports, each of which deliver 30 GB/sec of peak bandwidth per FPGA on the card. The four ports of DDR4 memory that link to the other side of the FPGAs deliver 32 GB of capacity per FPGA (with an option of 64 GB per FPGA) and 85 GB/sec of peak bandwidth. So each card has 290 GB/sec of aggregate bandwidth and 132 GB of memory for the applications to play in.
These FPGA cards slide into a PCI-Express x16 slot, and in fact, Nallatech has worked with server maker Dell to put these into a custom, high-end server that can put four of these cards and two Xeon E5 processors into a single 1U rack-mounted server. The Nallatech 510T cards cost $13,000 each at list price, and the cost of a server with four of these plus an OpenCL software development kit and the Altera Quartus Prime Pro FPGA design software added to is $60,000.
Speaking very generally, the two-FPGA card can deliver about 1.3X the performance of the Tesla K80 running the seismic codes at this oil and gas customer in about half the power envelope, says Cantle and there is a potential upside of 10X performance for customers that have larger volume datasets or who are prepared to optimize their algorithms to leverage the strengths of the FPGA. But Nallatech also knows that FPGAs are more difficult to program than GPUs at this point, and is being practical about the competitive positioning.
“At the end of the day, everyone needs to be a bit realistic here,” says Cantle. “In terms of price/performance, FPGA cards do not sell in the volumes of GPU cards, so we hit a price/performance limit for these types of algorithms. The idea here is to prove that today’s FPGAs are competent at what GPUs are great at. For oil and gas customers, it makes sense for companies to weigh this up. Is it a slam dunk? I can’t say that. But if you are doing bit manipulation problems – compression, encryption, bioinformatics – it is a no brainer that the FPGA is far better – tens of times faster – than the GPU. There will be places where the FPGA will be a slam dunk, and with Intel’s purchase of Altera, their future is certainly bright.”
The thing we observe is that companies will have to not look just at raw compute but how their models can scale across the various memory in a compute element and across multiple elements lashed together inside of a node and across nodes.

Intel Reacts To The Competitive Heat On Its Xeons
Whatever is going on with its competitive positioning against revitalized X86 server chip rival AMD, Intel clearly felt that it could not wait for the launch of its 14 nanometer “Cooper Lake” and 10 nanometer “Ice Lake” Xeon SP processors to address it. And so today the chip maker is …

The Killer Apps For FPGAs Could Be SmartNICs And Storage
If FPGAs are going to take off in the datacenter in their own right, they are going to need their own killer apps. Plural. At The Next FPGA Platform event that we hosted recently in San Jose, there was plenty of talk about how FPGAs have been embedded in all …

The Datacenter GPU Gravy Train That No One Will Derail
We have five decades of very fine-grained analysis of CPU compute engines in the datacenter, and changes come at a steady but glacial pace when it comes to CPU serving. The rise of datacenter GPU compute engines has happened in a very short decade and a half, and yet there …
Hmm so basically they trade aggregate memory peak performance with larger total memory? Where the HMC is basically cache? Or am I missing something. I think these cards could easily excel on NeuralNet learning compared to GPUs especially with their higher flexibility, integer and precision room and therefore the change of doing some weight matrix and spare matrix compression. They could give nVidia a serious kick in the nut if they are serious.
They could go to other lucrative markets like banking, financial services, insurance, climate modelling, with a smart trick. Develop a software library binding R statistical language with their custom designed boards.
With the flexibility of the Stratix 10s EMIB SiP and ARM integration, you could imagine consolidating that rather large card into a board that has a lot more HMC and a lot more functionality in a smaller space, easily water cooled for an ultra dense FPGA hybrid supercomputer.
That would make it look something like the Exanest system. Add a fast optical interconnect and get rid of the PCI-E bottleneck and it would probably scale to a few hundred PFLOPS with Stratix 10s.
Isn’t Tesla K80 dual kepler which is 5 year old tech? Why are they comparing to that for single precision?
so they’re comparing 5 year old GPU architecture to a brand new FPGA on a brand new processing node.
This comparison will be more relevant to do against Pascal based GP100 which also features new hybrid memory.
Awesome article. I am a beginner to all of these, but was able to to follow most of it. (y)