

As the shift in high performance computing has taken an efficient data-intensive supercomputing turn in recent years, fundamental rethinks in architecture are coming to the fore. IBM, Intel, and others are striving to create more balanced systems, but in the midst of larger efforts sits something quite unique—and possibly key to the future of processing data-intensive HPC workloads very quickly and efficiently.
The key to this doesn’t veer far from common sense on the surface, but of course, implementation is something of a challenge. This is a task Peter Kogge (whom we spoke with earlier in the week about the state of memory in high erperformance systems) and his team at Emu Technology have taken on. And this is certainly an approach worth watching.
Just as we have heard over the last few years in particular, conventional machines are designed to keep floating point units busy with a lot of bandwidth and a lot of cache to keep data flowing nicely. However, as Kogge tells The Next Platform, their design focuses on keeping the memory channels busy and generating far more memory references than a conventional core can take and keeping those balls in the air at the same time. As we have heard from numerous HPC centers in recent years, this hones in directly on the real bottlenecks for data-intensive high performance computing.
A first look at the Emu architecture might lead one to think that they have riffed on NUMA, and while that is fundamentally correct, how they have done it is the interesting part. The Emu design looks like a shared memory machine where the access is uniform, so it is not necessarily NUMA and is rather, more “UMA” in that whenever a memory reference is made, it is being executed on a core that is right next to the memory channel that holds the data.
The advantage to UMA is that there’s no sending messages around; memory is accessed and appears accessible at all times. The uniqueness of the Emu architecture is that on the inside, a program moves around the system and executes on whatever core is closest to the memory required, but the data itself never moves. Therefore all accesses stay local. “The non-uniform part is that if you start to make a reference that is not local, nothing happens until the thread state gets moved to where it becomes local,” Kogge explains.
The key to these capabilities is wrapped into a custom-developed “Gossamer” core that the Emu team has internally developed with a special property that, when there is a non-local memory reference made, it can pack up its context and ship it across the network. This effort has been coupled with various optimizations to the instruction set and overall architecture to minimize the bandwidth needed for shipping threads around. Some conventional cores in the system work as service processors (running the OS, system services, etc.) and while those could theoretically be any kind of core, Emu, due to some practical engineering issues, considered using ARM processors but decided on a PowerPC e5500—something that can change over generations.
“Gossamer” is a poetic name for the cores—and the entire machine, really. As Kogge explains, “What we have done is taken the idea of threading and said, what happens if you make ultra-lightweight threads where the state of the thread is so small you can move it around via hardware, versus use software to move the thread.”
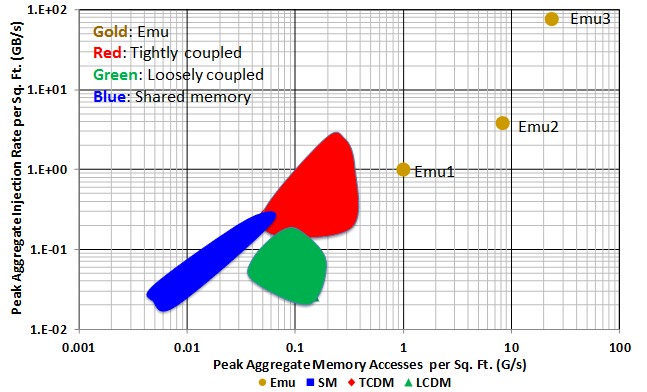
The scalability of the first generation is quite impressive and is rooted in the Rapid I/O interconnect, which itself can support up to 64,000 end points. On the first generation machine, that equates to 512,000 “nodelets” (each of which is a memory channel plus four cores). If you do the quick math on that, that’s a two million core system with each core capable of running 64 threads with simultaneous multithreading, bringing the system to the point of supporting 128 million parallel threads executing. Yeah. You read that correctly.
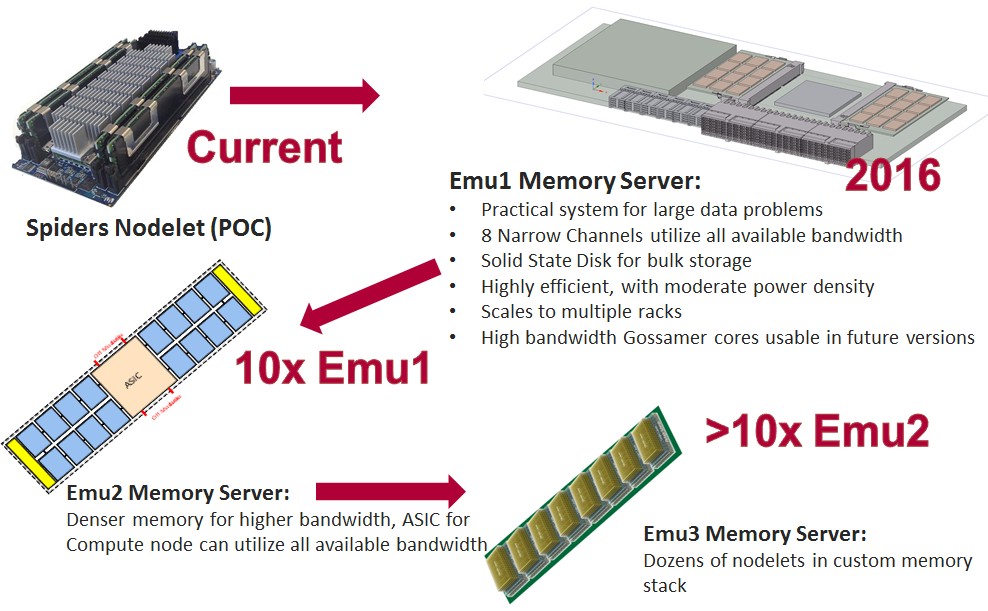
The machine is in the first round of simulation on FPGA and will be made available later this year. This will eventually be transformed into an ASIC phase (one can guess in about a year) with Emu looking into how stacked memory might fit in as well. What is truly interesting is that even on FPGAs, which clock in around 300 mZ, which is much slower and with far less logic than a standard X86 processor, Kogge says they are outperforming X86 by a massive margin. “Even with one hand tied behind our back in terms of the hardware technology, we’re seeing big things.”
Taming The Threadmonster
Of course, the next stage is how this beast might be tamed. The environment for doing this is more tied into the language (unlike something with the Cray XMT architecture that has a C, C++ compiler with a lot of primitives that allow threads to be started in a way more similar to OpenMP). In this case, Emu is using Cilk, which has a primitive that allows to make a function call a separate thread, which drops the level at which threading is done, which is the key to efficiency, according to Kogge.
As an interesting side note, Emu is doing this with a slightly different take on Cilk from what Intel has been building on over the years. When the Cilk project started at MIT, it had four primitives, Intel added several features to allow short vectors, but Emu is using a subset of that original variant as basic instructions can handle some complex tasks threading-wise.
“There are three key additions to C; there’s a functional call that says ‘spawn’ or just ‘go do this on a separate thread’ and then another that says to sync, or wait for all those spawns to come together, and there’s also a ‘for all’ that internally loops through a couple of spawns. Even though syntactically it’s the same, the underlying threading model is different. On a conventional blade, it’s a worker-based model where the hardware threads go around and look for queues that were built by the spawns for work to do. In our case, the spawn says, ‘go build the thread to go do this.’” It’s a lower-level but more efficient approach.
Cilk is the main language but we can run any C language and there’s nothing to stop users from implementing the same library calls. “We are formulating plans for which library calls will be most important to our users. We have the ability to implement OpenMP and other library calls and can even emulate MPI if we wanted to, even if that’s not a good choice. We want to mesh with many programming models that are out there.”
As yet another side note, as Emu was describing the technology and how it might work for data-intensive applications, the concept of Hadoop came to mind. While there are some similarities in theory, speed is the real issue since users are moving across the network but much slower (disk versus direct memory access). Also of interest is that with Hadoop in mind, when it first hit the stage, many wondered why moving compute to the data instead of data to the compute hadn’t been tried before. It was so simple, elegant, and common sense. One could argue the same about what Emu has done as well—it seems quite obvious on the surface, but no one has taken this route in the same route (although there are similarities with the Cray XMT and other architectures).
This is not an inexpensive undertaking, as one might imagine. Emu is privately funded, including by an unnamed three-letter agency in the United States. Take your pick there, but realize that the kind of very-large scale, ultra-scalable, efficient compute this thing promises does hold a certain appeal for agencies in the same “grand challenge” way Kogge worked with Lexis Nexis to present this type of architecture as the only solution balanced enough to tackle compute and data-intensive problems at scale.
Quite simply put, a change in the demands of data, data movement, memory, and compute—and how those need to be balanced—is driving the practical realization of things like this. And from what we can see from this view, Emu has something to watch carefully as 2016 unfolds.




Let me guess it is the DoD?
Could be the DoE. They have huge machines.
In most HPC workloads I’m familiar with, the data dwarfs the executables, and data locality is an ever present concern. Why not rethink amd move the code to the data? That’s what you spend half the time doing anyway – worrying about data locality. If you could hide this in OpenMP pragmas, you’d have a killer app IMO.