

When the founding committer of the Spark in-memory computing framework becomes the CEO of a company that has dropped out of stealth mode and will very likely soon be offering support for a new storage caching layer for the modern, distributed computing era that will span beyond Spark, you have to stop and take notice.
While the Hadoop stack has received a huge amount of attention in the past several years, there are many that argue that Spark and its Spark Streaming stream processing extensions, which were also created by Haoyuan Li, a researcher at the University of California at Berkeley’s AMPLab, will come to dominate the data processing in distributed clusters. The Hadoop Distributed File System could end up being relegated to the role of being a massive and relatively inexpensive data store that can allow batch processing through MapReduce and SQL querying through various overlays such as Impala, HAWQ, or Drill. This is akin to the distinction between OLTP and batch systems in days gone by, perhaps, and some people are thinking this way.
But Li has a slightly different view of the world and it is a much broader and deeper one that he will be taking to market with Alluxio, which uncloaked this week as the commercial entity behind the Tachyon in-memory caching layer. The moment was crystallized by the announcement that Tachyon had reached its 1.0 release level after nearly three years of development, and Li sat down with The Next Platform to talk about how the storage layer will fit into modern distributed systems.
Products that come out of the AMPLab tend to get retooled for larger purposes, so it is no surprise that this is happening to Tachyon, which is now called Alluxio but which people will probably still call Tachyon. Spark itself is a standalone in-memory processing framework that could, in the long run, end up unifying hyperscale data analytics and HPC simulation and modeling frameworks, but it has been grafted onto Hadoop, too. The Mesos workload management tool was designed explicitly to configure and orchestrate Spark on distributed clusters, and has been made a more general tool and is finding its own place as an open source alternative to the controllers in use at Google, Microsoft, Facebook, and other hyperscalers. (That would be Borg, Autopilot, and Kobold, if you are keeping track of names to play hyperscale bingo.)
“Alluxio is a wide system and there are many computational frameworks and applications – more than with Spark – that can run on top of it, and many different kinds of storage systems can run underneath it as well,” Li explains.

There has been a common misconception, says Li, that Tachyon was just a storage caching layer for Spark, and he wants to put that to rest with the Alluxio launch. And indeed, one of the reasons why Tachyon is one of the fastest growing open source projects in history is because it is not only riding on Spark’s coattails but allows tiered storage management that goes far beyond Spark.
Here’s how it works. The Tachyon software runs on the computational nodes in the cluster, and allows for the fast writing of Spark data once it has been processed in memory or the fast reading of HDFS data as it is being pulled into memory to do batch-style MapReduce jobs. (Other frameworks can be plugged into either side of this example.) The read caching is simple enough to boost performance, but the write caching is tricky and is often what slows down performance as application frameworks and their analytic workloads chew through data in stages to get to a final result. This is where Tachyon differentiates itself, says Li. Also, once the data is in memory, it can be shared by multiple frameworks, including but not limited to Spark and MapReduce, while being persisted out to HDFS, Amazon Web Services S3, GlusterFS, or other persistent storage when it grows cold and is no longer needed by the computational framework.
In a sense, Tachyon acts as a kind of in-memory burst buffer between applications and whatever final persistent storage is used in the datacenter, and it is also a hierarchical storage manager of a sort, akin to that stodgy stuff that has been on mainframes since most of us were babies. But Tachyon has a much wider memory hierarchy to play with, spanning main memory, flash and disk internally on cluster nodes and reaching out through plug ins to all kinds of disparate data sources where information can be extracted and where finished results can be pushed. There is another big difference, too.
“We expose a single storage API and a unified namespace to the application layer, and this is really powerful,” Li explains. “So developers can write a program against Alluxio and that program can access any data – and I mean any data – in any storage in the organization.”
The other neat bit is that if you change where that data is stored, you don’t have to change the application, but just point Tachyon, now called Alluxio, at it.
This is, in essence, a universal virtual distributed storage layer in the platform stack, and the trick, says Li, is creating a universal metadata namespace that can span all of these disparate data sources and, at least as far as the computing frameworks are concerned, look like one giant storage pool. The management of the movement of data from disk or flash into main memory and back out again is managed by polices set by the applications and their administrators, and Li says that most workflows in the enterprise are predictable enough that data can be staged well ahead of time for in-memory processing using Spark or batch processing using MapReduce.
Baidu Bets Big On Tachyon
Chinese search engine giant Baidu has been using the Tachyon storage caching layer for more than a year in production, and has it running more than 100 server nodes with an aggregate of more than 2 PB of data that streams in from its vast cloudy infrastructure. This software is at the heart of a new ad-hoc query system that is radically faster – try by a factor of 30X – than the Hadoop system it replaced.
Queries run by managers at Baidu were taking tens of minutes to hours to run, and this was unacceptable for running the business in something akin to real time. The goal of this new system pretty high, with a desire to finish 95 percent of the queries submitted by managers in under 30 seconds. The nodes in the ad hoc query cluster are currently configured with memory and disks only – no flash – and use the Spark SQL framework running atop Baidu’s own homegrown file system, so that speed up is not due to a move to flash. The move to Spark SQL alone dropped the average query time from about 1,000 seconds to 100 to 150 seconds, which was a big boost, but as Shaoshan Liu, the senior architect at Baidu in charge of the project, explained to The Next Platform by email, that did not meet the criteria set out from the beginning.
The problem was not that the machines in the Spark SQL cluster needed more CPU or memory, but rather that data was spread out across clusters that were in disparate datacenters and the latency of moving data across the network was too high. Slipping in the Tachyon layer and running it across the memory in the cluster and having it cache the disk data from local and remote nodes as the workloads changed dropped the average query time to around 15 to 20 seconds, and Baidu met its 95th percentile goals, too. The machines, by the way, have an aggregate of more than 50 TB of main memory running the Tachyon layer, which Alluxio says is probably the largest such setup in the world at the moment.
At first, Baidu ran this Spark SQL cluster with only disks and main memory, but recently it has added flash-based SSDs to the cluster as a secondary cache and local disks as a final local level cache connecting to the remote HDFS storage in its distributed Hadoop cluster. Add it all up, and the ad hoc query system now has more than 2 PB of local storage across its nodes.
This kind of speed up is precisely why there are over 100 companies that have deployed Tachyon already even though it is just hitting its 1.0 release. (In the hyperscale world and among the enterprises that are trying to emulate them by staying on the leading edge, those release numbers don’t mean as much as solving a problem.)
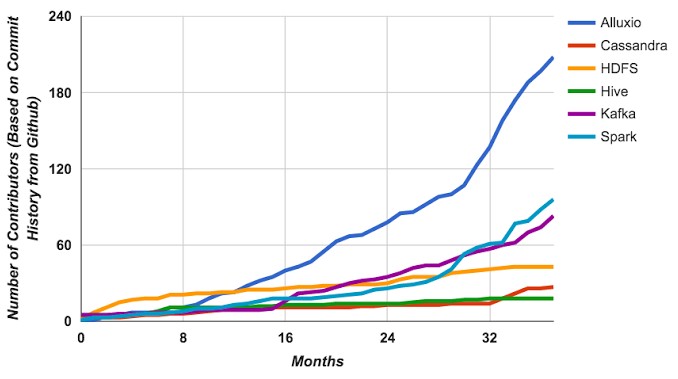
The Tachyon project now has over 200 contributors from more than 50 companies working on the project, and as the chart above shows, its ramp makes it among the most popular open source projects ever and rivaling Spark itself, which is no slouch.
While Li cannot name names, he can talk about scenarios when it comes to Tachyon users. Among the companies using Tachyon in production is a large oil company that has Spark running on a cluster that has memory only on its nodes; this setup sucks in data from an external storage cluster that is based on the GlusterFS file system from Red Hat. There was no talk about what kind of improvements this oil company saw. A software as a service company is running the Impala SQL query engine on nodes with memory and SSD storage and accessing data access stored in Amazon Web Services’ S3 object storage, and it saw a 15X performance improvement in SQL queries by sliding in Tachyon between the Impala layer and the S3 storage and staging that data to local nodes.
The question now is how Li will be commercializing Tachyon through Alluxio, which raised $7.5 million in its first round of funding from Andreessen Horowitz last year. Li tells The Next Platform that he will reveal those plans later this year, so stay tuned.




Be the first to comment