
It has been roughly a year and a half since Hewlett Packard Enterprise first announced its intent to create a completely different kind of a system. The company may have announced it then, but you can bet that its researchers and engineers had long been playing with integrating many of the very concepts that you have been reading about recently in The Next Platform. High on this list would include the now simple realization that technology was soon to be developed that would allow the basic organization of computer systems that we have had forever to change.
It wasn’t really all that long ago that solid-state storage started to range its use as a partial to a complete substitute for spinning disk drives. This non-volatile and fast flash storage (also known as NAND and NOR memory) was then used as a simply faster form of I/O-based persistent storage; we even called them flash drives. Realizing that there were other non-volatile storage technologies not all that far into our future that are or will be still faster, still more dense, and considerably more reliable, it now seems like a no brainer to be asking why it is that such memory needs to be relegated on the far side of any I/O infrastructure. Why can’t this persistent memory be a computing system’s main memory?
And not just main memory, but all memory. If it’s persistent, and if there is enough of it somewhere in the system, why would there be a need for rapidly accessible I/O-based storage at all?
For those of you following The Machine, as we have been doing here at The Next Platform, you know that HPE has been pushing a type of persistent storage based on memristor technology. HPE has struggled to bring that form of persistent storage to market, and although it will certainly be a feather in its cap if it does get commercialized, memristor-based storage is only a small part of the broader vision for The Machine. Any number of other potential technologies, some already very near to the marketplace, could serve the same purpose. What HPE seems to be envisioning for The Machine is a complete solution: fast multi-processors, both rapid dynamic and persistent memory, many optically-linked nodes, with all persistent memory being byte addressable from all processors in the system. In addition, this total solution includes operating systems, file systems, database managers, and tools that are well aware of this difference in system topology. Picture your changing database records as being assured of the protection of persistent storage merely by having a processor copy data into it, or even just flushing processor cache.
What does this system called The Machine really look like? Answering that question is the purpose of this series of articles.
Since it is a series, we will start with something normally relegated to the end of any paper, a bibliography of sorts. Most of these are videos of presentations by HPE personnel. The last is a nice paper on a possible programming model relating to the use of non-volatile memory.
- Developers, start your engines; open source software for The Machine, HPE Discover 2015 London
- Programming with non-volatile memory; Hewlett Packard Labs makes it easy, HPE Discover 2015 London
- HP Labs Peeks Under the Hood of The Machine, HPE Discover 2015 Las Vegas
- NV-Heaps: Making Persistent Objects Fast and Safe with Next-Generation, Non-Volatile Memories
Before proceeding, I would like to thank Paolo Faraboschi and the Hewlett Packard Labs team for answering a number of my questions.
The (Not-So) Basic Node Of The Machine
Let us start with a picture of an exemplary node from The Machine from a Hewlett Packard Enterprise presentation at HP Discover 2015. I have identified portions within this node per this presentation.

Interesting in itself, but I have taken the liberty of abstracting the mock up as in the following figure to include the interconnects as I understand them to be. This represents only a single node, part of a much larger single system built using many of these. So let’s next take a pass at understanding what the topology of a single node implies. We will be looking at the system made from many of these shortly.
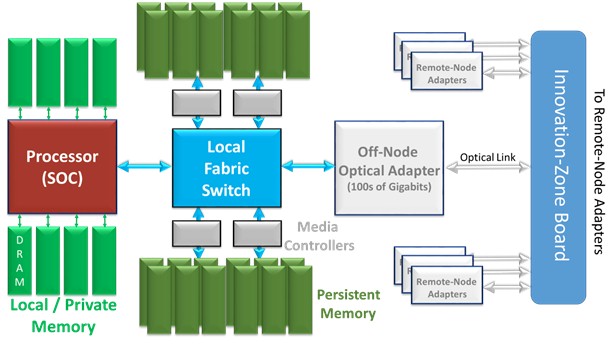
The entity called the processor SOC (short for system-on-chip) could be most anything. HPE has spoken of this potentially being a 64-bit ARM or X86 processors. As interesting as a processor’s instruction set is, this series of articles will spend no real time there; the storage and programming model is more our focus. So let’s for now assume that this SOC is a single-chip, but multi-core package, each core and chip with a sufficient amount of cache, each chip with direct connections to up to (based on the mock up) eight DRAM DIMM slots. For the time that this is likely to come out, let’s call this at least 1 TB (per node) of rapidly accessed volatile memory.
The same processor chip additionally supports a high bandwidth interconnect to a module called the local fabric switch. For only this local node, the purpose of this unit is to enable the processors here to access the contents of local persistent memory units by way of modules called media controllers. Think of these media controllers as serving the same function as the on-chip memory controllers on the SOC complex, and more, but here relative to the local persistent memory. That local fabric switch goes on and supports a connection to an off-node optical adapter. (More on that later.)
Along with this memory-based connection to other nodes, the nodes in The Machine also support more traditional means of doing inter-node communications and, of course, communications into the broader world. Think Ethernet.
So that is our starting point. It represents just one node, one node interconnected to many more via this optical adapter by way of what I’ll call for now a switch (for now picture it as a top-of-rack unit), all together comprising what is ultimately just the hardware of The Machine.
Of Volatile Cache, Volatile DRAM, And Non-Volatile Persistent Memory
This might seem an odd place to start in characterizing The Machine, but you will find that knowing the following will make The Machine, and all of its cool differences, seem obvious to you.
Even though all DRAM memory in almost any computer system can be considered to be byte addressable, and so processors can access individual bytes of DRAM, in reality far and away most accesses of DRAM are done as block reads and writes. A “block” here is the size of a processor’s cache line, one of many in the cache of the processor cores. Said differently, assuming that a cache line is 128 bytes in size, DRAM is not accessed as individual bytes or words, the DRAM data block being accessed is 128 bytes in size and aligned on a 128-byte boundary. DRAM memory is being accessed to do cache fills – and therefore block reads – or cache line flushes – and therefore block writes. Such blocks are the unit of storage that are typically passing between the processor chip and the DRAM; it is a rare event that individual byte accesses to/from DRAM ever occur. Accesses of your data as the typical integer value are done from the cache.
Stepping up a level, even though no programming language gives you visibility to it, for most program execution time, a program accessing what it thinks of as “memory” is instead typically accessing the data and instruction stream residing in a processor’s cache. The programming model is such that a program’s instructions act as though they are accessing the memory’s real address space, but in reality the processor cache – a much faster memory – steps into the middle of the access and transparently serves up the needed data.
When the cache does not have what is needed, the processor’s core is effectively unaware and is simply told to wait a while, allowing the cache controller to find the requested data block, no matter where it is in the entire system. When the cache needs more space for the next cache fill from the DRAM, it may flush the contents of some cache lines as data block writes back to memory. The location of the write in the DRAM is dictated by a block’s real address held along with the cache line. Again, it does not matter where in the entire system the target real address happens to be pointing, the flushed data block will make its way back to that location. That’s basic cache theory as it relates to what every system has dealt with up to now, the accessing of the DRAM.
Let’s switch gears and, still limiting ourselves to one node, consider The Machine’s node-local persistent memory. Just like DRAM, its content is capable of being byte addressable and byte accessible. That’s relatively new for persistent storage. The processor could read byte-by-byte from persistent memory, but, as you will see in a bit, the processor – and the performance of a program – does not want to wait for individual byte reads from persistent memory any more than it does for reads from DRAM. So here too, with persistent memory, it is completely logical that reads and writes to it are done as block-sized cache line fills and flushes. It is also completely reasonable to observe that most of the accesses a program thinks it is doing from persistent memory’s data are actually being done as accesses to and from the cache; once a data block is in the cache, subsequent accesses of that same block are done from there. A program may act as though it is storing to an integer variable at a location in persistent memory, but such stores are – at least temporarily – being done first in the cache, into cache lines tagged with the real address of persistent memory.
Given that The Machine’s processor caches are intended to hold such byte addressable data from both the volatile DRAM and the non-volatile persistent memory, it follows that the unit of storage being requested from and returned to the persistent memory – via the fabric switch and the media controllers – is that of a data block, just like with the DRAM.
Sure, it’s all done via the cache, but there is ultimately a big difference between cache-with-DRAM and cache-with-persistent memory. Either way, for the data remaining in the processor’s cache, if power is lost to its processors, you can say good bye to the contents of the cache. It does not matter whether those cache lines were tagged with the real addresses of DRAM or real addresses of persistent memory; if the power is off, the data is gone. Further, if persistence is required, the cached data needs to be flushed out to the persistent memory and to have actually made it there.
When the power is lost, the data in persistent memory remains; it persists. And the beauty is that it took not much more than flushing such cache lines out to Persistent Memory to make these blocks persistent. (Before going on, pause for a moment and consider: What does it really take to ensure data’s persistence in today’s typical system? Functionally, there is a big difference to make data persistent. From a performance point of view, well, there is no comparison. It should go without saying that we are talking about multiple orders of magnitude difference.)
This approach to memory is fast, but as you will see, enabling this takes a different attitude. From the point of view of a program and DRAM, cache is generally transparent. For the programmers out there, when was the last time that you thought about cache? That’s just as the processor designers intend. On the other hand, from the point of view of persistent memory, making the contents of the cache ultimately persistent is something that seems to need our awareness. But that’s no big deal, right? Making data persistent today requires our full awareness as well.
Still, consider, from the high level point of view, the process of a program saving a file. Aside from the definite speed difference between saving to persistent memory and saving onto I/O-based persistent storage devices, saving the file rather looks the same. At such a high level, do we really care whether my file system resides on one versus the other? We just say save or commit a change to a file, and the file system manages the writes no matter the location of the persistent storage. But at the lower level of actually making it happen, it rather does matter. At that low level, there is a huge difference between what it takes to drive a file to disk versus driving that same data to the right location in persistent memory.
For persistent memory, if you are programming at a low level, the trick is first knowing:
- That the cache lines are tagged with a real address of said file in persistent memory (i.e., when a cache line is flushed, it writes its contents into its particular block location in persistent memory) and
- That the data flushed from the cache really had become successfully and completely stored into the persistent memory. It’s not persistent until your program (or later recovery) knows it’s persistent. That fact that you know that the data is on its way toward the persistent memory buys you no guarantees. (Recall that your program did not need to know when data was on its way into the DRAM; a power failure affects both the cache and the DRAM the same way.)
If you are familiar with the basic workings of cache, you know that – with enough time and disuse – changed data residing in the cache does, sooner or later, make its way out to memory. Hardly any program bothers to think in those terms; it does not really matter to a program whether data is in some cache or in DRAM. Indeed, the processor designers work hard and long to ensure that the cache is effectively transparent to any program; this remains true even in a multi-threaded, multi-core, shared memory system. Hardly any code takes the existence of the processor cache into account; it just works. Again, in the fullness of time, changed cached data sooner or later shows up again in memory.
But, historically, everyone understood that to make data persistent, we also needed to programmatically force the changes out into I/O space and then on its way onto the likes of disk drives, often with your program waiting for it to complete. Your program, or some entity working on your behalf, spent the very considerable time, complexity, and processing to ensure that your data made its way out there. Your program made the simple request to make the data persistent, and then something else took over to make it so. And, often, you waited.
Taking all of this into account, let’s consider a program on The Machine having its changed data still residing in a processor’s cache. Let’s also say that the changed data is in cache lines tagged with real addresses associated with persistent memory. Being tagged in this way, in some future time these changed data blocks may well make their way out into persistent memory on their own. Its future may be persistent, but it certainly is not now. These data blocks can also stay in the cache – or even in the cache of another processor – indefinitely. But if your program requires explicit knowledge that these same changed blocks really have become persistent, an explicit request – a forced write, a cache line flush – is needed to begin the process of returning the cached data to persistent memory. It will not take long, and it is not particularly complex to initiate such cache flushes (HPE will be providing a number of APIs that make this so), but if your program should not continue until such data is known to be persistent, your program needs an explicit means of knowing that the cache flushes really are complete.
Why tell you all this? It is to start to make it clear that creating The Machine is a lot more than just hanging persistent memory off of a processor. Creating The Machine also means creating the operating system, compilers, APIs, and overall software infrastructure to make this all happen, to make it implicitly obvious to use, and to make this thing really fast. It also means, as you will see shortly, that if you have performance needs that require your own programs to work at this low level – and now with The Machine, it can – it will take a different mental model to support it well and correctly. It is all just memory, after all, but it is also conceptually different.
We will take a closer look at a number of other aspects of The Machine in subsequent articles.
Related Items
Drilling Down Into The Machine From HPE
The Intertwining Of Memory And Performance Of HPE’s Machine
Weaving Together The Machine’s Fabric Memory
The Bits And Bytes Of The Machine’s Storage
Operating Systems, Virtualization, And The Machine
Future Systems: How HP Will Adapt The Machine To HPC

HPE Adapts Boosted Alletra Storage For GreenLake Utility Consumption
Nearly two years ago, Hewlett Packard Enterprise rolled out a new battle plan for storage and a new kind of storage array to implement it. This week, that new storage array – the Alletra line, one of the fast-growing part of the HPE business – is getting a “Sapphire Rapids” …
Putting More Flex Into Flash Storage Arrays
In a cloud-based, highly distributed, and data-centric world, flexibility in what a piece of hardware and its systems software can do, where it can run, and how it can be configured is a critical differentiator for picky enterprises. For several years, Pure Storage has been talking about flexibility and choice …

Sneak Peek At “Sapphire Rapids” Xeons In “Crossroads” Supercomputer
Managing an aging nuclear weapons stockpile requires a tremendous – and ever-increasing – amount of supercomputing performance, and the HPC system business the world over is focused on this as much as trying to crack the most difficult scientific, medical, and engineering problems. Los Alamos National Laboratory has had its …
There are some microkernel based research OSes (eros and coyotos come to mind) that treat all available memory & disks as a single pool of storage. Maybe HPE can find some shortcuts from their design and findings.
Kim Keeton from HPE Labs talks about some of the challenges of programming for The Machine in the talk “Reimagining systems and application software for The Machine – A sneak peek from HP Labs” – see https://www.youtube.com/watch?v=WZbPyV5AnKM. The talk covers the Atlas Programming Model for developing apps – an approach which keeps data consistent in a non-volatile memory model even with system failures that lose cache contents.
What ever happened to The Machine?