
Time and again, commercial Hadoop distributor MapR Technologies has demonstrated the value of the MapR-FS file system that underpins its Hadoop stack and differentiates it, more than any other feature, from the other Hadoop platforms with which it competes.
It is the underlying MapR-FS that provided NFS access, with random reads and writes, as well as storing data in a mode that is compatible with the Hadoop Distributed File System, and this file system is what has allowed MapR to accelerate the HBase distributed database overlay for HDFS, and is also the key technology that the company exploited to create its own NoSQL database, MapR-DB, which got support for native JSON documents in the fall and which now can take on Mongo-DB. Now, MapR is pulling another workload that formerly ran on separate clusters – Kafka data streaming – into the core MapR file system.
“This has been under development for quite some time,” Jack Norris, chief marketing officer at MapR, explains to The Next Platform. “The way we have done that is not as a separate component, or a separate cluster, unlike every other message queue or event streaming product out there. This is integrated, and we are moving from these different silos to a new converged platform, which you are kind of front and center and in the middle of.”
Broadly speaking, there are two kinds of analytics processing that is going on out there today, but that does not necessarily mean companies need two kinds of systems to perform them, at least according to MapR. Data in motion needs to be queried and analyzed for a lot of workloads, often in a continuous way, to derive what the industry has started calling “perishable insights” that lose their value once a period of time has passed. This has meant that companies need to have a fast event processing system like Spark or Storm and a much slower analytics system based on Hadoop for broader and deeper data sets and more complex queries to derive value from the data. Kafka sits on the front end, splitting the streams of incoming data and passing off the bits that the fast furious and slow and deep parts of the analytics stack need.
What MapR customers want, according to Norris, is a single system that will do both, and they want to get away from infrastructure that looks like this:
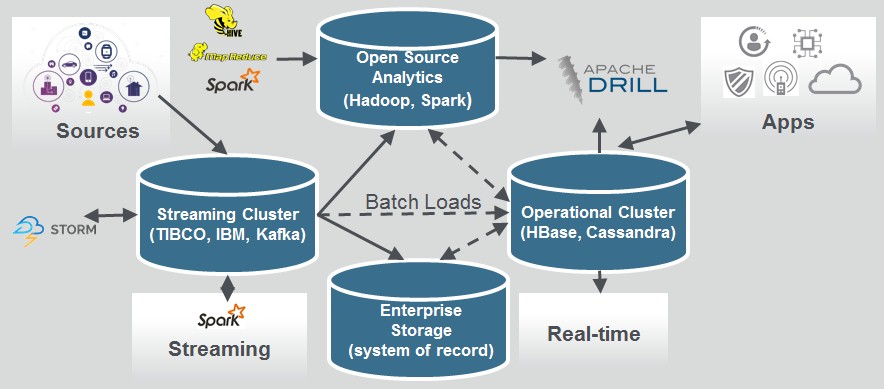
The convergence of Kafka stream processing into the MapR file system means that data in motion and data at rest can be handled by the same physical cluster, which will simplify analytics clusters and their operations and will also allow for the querying of data streaming into the cluster by traditional tools such as MapReduce and Hive. This will also eliminate data duplication and a lot of the extract-transform-load (ETL) tasks to stage data, and reduces latency in operations. Converging event streams, database, and a file system of record underneath it all with unified security and management simplifies the Hadoop stack – that term being used in the broadest of senses.
“Ultimately, what companies are trying to do is impact business as it happens, which means moving analytics from a reporting function to describe what happened to incorporate it into the flow so they can adjust to business as it is happening,” explains Norris. While this platform includes support for running Spark and Storm streaming applications on “streams of record,” meaning data that is streaming in before it lands in the file system, because the streaming functions are integrated with the MapR file system, companies can do deep analytics using Hive or even MapReduce routines on those streams as the data is coming on. And because this message queuing function rides on top of the MapR-FS file system, it can handle billions of messages per second and be replicated across multiple Hadoop instances that are dispersed geographically.

Just like MapR’s file system is not based on NFS or HDFS but supports those protocols, the MapR Streams functionality is not based on the open source Kafka tool that is commonly used to route streaming data to Spark, Storm, and Hadoop systems. The Streams layer uses a publish and subscribe transport, so applications can be continuously or intermittently connected to various streams of data. Given this, now the MapR stack can be used as a back-end for real-time billing applications, to drive operational alerting systems and dashboards, or provide feedback loops into production applications for real-time optimization.
The Streams add-on to MapR’s Hadoop stack is based on a general purpose event streaming framework that sits on top of the MapR-FS file system and that runs on all of the nodes in the cluster, sitting underneath the streams processing engines such as Spark Streaming, Storm, Apex, and Flink. While it is not based on the open source Kafka tool commonly used to parcel streams of data out to Hadoop or Spark, it does supports the Kafka APIs. (It is also an alternative method to legacy message queuing products from TIBCO and IBM.)
“We think that Kafka model is right, in terms of the scale, but unlike a special purpose system where you need different silos and you are duplicating data, we extend it as a general purpose engine,” explains Steve Wooledge, vice president of product marketing at MapR. “Kafka is now part of a single cluster, and within that cluster you might have Spark and Hadoop MapReduce and the NoSQL database all running.”
Those legacy messaging systems, says MapR, can handle data at the rate of thousands of messages per second with a few data sources and a few destinations, and if you want to do historical analysis, you have to do it on a separate platform once the data lands and comes to rest.
By integrating Kafka-style functionality into the Hadoop stack itself, MapR says it can handle billions of streams with over 100,000 topics per stream and pull in data from millions of sources; it can push billions of messages per second with streams that are can hit hundreds of destinations – and do analytics on the streams and on data at rest at the same time. The higher throughput is enabled through parallelization of the Kafka functionality across the node as well as a shift from transactional architectures with legacy message queuing systems like TIBCO and MQSeries to the publish/subscribe method used with MapR’s Streams and the actual Kafka, which was developed by LinkedIn and is being commercialized now by Confluent. The magic happens because it is all running inside the file system, and basically, there is enough throughput in the cluster and the underlying file system that you don’t have to run the streaming on a separate system.
“This has been under development for quite some time. The way we have done that is not as a separate component, or a separate cluster, unlike every other message queue or event streaming product out there. This is integrated, and we are moving from these different silos to a new converged platform, which you are kind of front and center and in the middle of.”
There is no word what impact running Streams will have on other kinds of processing inside a MapR cluster, but nothing is free in the datacenter, so there has to be some performance overhead. Hadoop is not generally compute bound, but I/O bound, so that will be the issue. Moreover, it is not clear what the ratio of Kafka compute is to Hadoop and Spark at enterprises today, which would be interesting to see, but clearly the cluster will be expanded as Kafka is being brought into the MapR fold even as it puts overhead on all of the nodes in a cluster. It may be a net gain in compute and a net decrease in capacity, which would be good things.
MapR Streams is in early release now, and will be available for the MapR 5.1 distribution, which will be coming out in January of next year and follows the MapR 5.0 release that came out in June of this year.
The freebie Community Edition of the MapR stack, which is also open source, will include the Streams functionality, just like it does for the file, tables, and documents add-ons that came before the Kafka-like functionality. The MapR Enterprise Edition adds high availability, security, global synchronization, and other features that are necessary for large-scale production workloads and that comes with per-node annual support contracts. The Streams function will carry a supplemental licensing cost above and beyond the basic Enterprise Edition license, as is the case with the NoSQL database. The Enterprise Edition costs $4,000 per node in a base setup with single-cluster functionality of MapR-FS and costs $10,000 per node with the MapR-DB data store and Streams added in plus all of the replication and high availability features to allow it to span multiple clusters.
If customers want to run Streams by itself, they can do so without the database or Hadoop MapReduce functionality. The pricing for Streams itself was not divulged. Spark has not yet been unbundled from the Enterprise Edition’s Hadoop capability, but Wooledge says that the company is looking at how it might offer this as a separate unit as well.
“The starting point for customers might be different from what it has been in the past,” says Norris. “We think that people will end up with converged processing on a single platform, that is just where we are going, but they could start from a variety of places. They could start with Streams, or Spark, or Hadoop and eventually get there.”

Cloudera Pivots To Data Management As Hadoop Fades
It was only two years ago that Cloudera, once one of the top vendors in what had been a white-hot Hadoop market, found itself fighting for survival. Hadoop, the open-source data analytics technology that a decade ago was seen as the answer to enterprises’ large-scale data analytics and management woes, …
Everybody Has Big Data – How To Cope With It
Enterprises are awash in data, and though many are tempted to save it all for later analysis – after all it worked for Google for many years – the store then analyze approach is poorly suited to environments with data sources that never stop. Storing all data is costly if …

Why the Fortune 500 is (Just) Finally Dumping Hadoop
Remember how, just a decade ago, Hadoop was the cure to all the world’s large-scale enterprise IT problems? And how companies like Cloudera dominated the scene, swallowing competitors including Hortonworks? Oh, and the endless use cases about incredible performance and cost savings and the whole ecosystem of spin-off Apache tools …
Be the first to comment