

The choice of programming tools and programming models is a deeply personal thing to a lot of the techies in the high performance computing space, much as it can be in other areas of the IT sector. And there are few things that will get HPC programmers more riled up than a discussion of OpenACC and OpenMP, which have different approaches to solving the parallel programming problem.
There is always talk of how these two sometimes competing, sometimes complementary technologies can and should be used, and The Next Platform had just such a chat with Michael Wolfe, technical chair for OpenACC and the technology lead at compiler maker The Portland Group, which graphics chip maker Nvidia acquired in July 2013, and Duncan Poole, president of OpenACC and partner alliances lead at Nvidia.
OpenACC is short for Open Accelerators, and the effort was launched by Cray, PGI, Nvidia, and CAPS back in November 2011. All of the founders had their own compilers and wanted to work together to create a standard for putting directives into Fortran, C, and C++ applications to help compilers figure out where parallel sections of code could be offloaded to accelerators such as GPU coprocessors and thereby speed up those applications. The idea of OpenACC is that these compiler hints are portable across multi-core CPUs as well as accelerators of various kinds, not just Nvidia GPUs, including many-core processors that have been used as accelerators like the Xeon Phi chips from Intel. With the OpenACC directives, the compilers parallelize the code and manage the data movement between the CPU and the GPU as the code is executed, and importantly, directives that are added to the code span those many architectures so that if the underlying hardware changes, the code can be recompiled for that new hardware with modest tweaking.
Another tenet with OpenACC, Poole explains to The Next Platform, is to get away from the code bloat that can happen when hand coding parallel calculations and data movement routines using the CUDA programming environment for Nvidia’s Tesla GPU accelerators or the OpenCL framework that is commonly used with AMD GPU accelerators as well as with DSP and FPGA accelerators. In one coding example that Poole showed, the stream of code needed to parallelize for CUDA C was about 50 higher than for OpenACC and OpenCL was about three times, but he conceded that in other cases, the amount of code needed to parallelize the code and handle data movement was as large as that for OpenCL. It all comes down to cases, but the point is to eliminate all of that coding and to let the compilers handle it.
“To be fair, a lot of the code that programmers have to add is the platform setup code and attaching to the device, which is handled implicitly by OpenACC so it doesn’t get replicated,” explains Wolfe. “So there is a certain amount of overhead that does. Every time you write a kernel, you have to set up the procedures, you have to launch them, and that overhead is somewhere between 50 percent and 150 percent.”
The big news out of the SC15 supercomputing conference this month is that a variety of compilers are bringing expanded support for OpenACC.
The compilers from The Portland Group (which is abbreviated PGI, not TPG) now support the use of OpenACC directives aimed at multicore CPUs and this parallelization (and therefore a performance boost) works whether or not a GPU is present in the system. PGI is similarly working on support for the combination of Power8 processors and Nvidia GPU co-processors, and has also added support for OpenACC directives for the forthcoming “Knights Landing” Xeon Phi many-core processor operating in standalone, bootable mode. In this sense, the Knights Landing chip is just a CPU with 72 cores and a two-tiered main memory architecture, and Wolfe says that he does not believe that anyone will be using Knights Landing as a coprocessor. (Intel has shifted out the delivery of such a coprocessor until later in 2016, and it would not be surprising to see the company pull it off the market if customers don’t show enough interest.)
Compiler maker PathScale, which also has a large presence in the HPC space, is supporting OpenACC directives for its tools on the ThunderX ARM server chips from Cavium Networks. Both PGI and PathScale support AMD discrete graphics chips (meaning those plugged into a PCI-Express peripheral slot) and AMD APUs (meaning chips that have CPUs and GPUs on the same die) already. PathScale has beta support for the combination of ARM processors and “Kepler” family GPU accelerators, and the most common test setup out there is an ARM chip with a Tesla K20 accelerator; this will ship as a commercially supported product in the Enzo 2016 compiler set for early next year. PathScale also has alpha support for the combination of IBM Power8 processors and Kepler Nvidia accelerators; it is unclear when this support will be rolled into the Enzo toolchain.

Two years ago, Mentor Graphics joined the OpenACC effort and since that time has been doing a lot of work to put OpenACC directives in the open source GNU Compiler Collection, and ahead of SC15 the company was working with the GCC community to get more OpenACC features into the compiler stack; the exact extent of this improved support, which is expected with GCC 6 in early 2016, is up to that community and is not entirely clear yet. But it will be more, and it will include supporting the Power8-GPU combination, says Poole, who also adds that he is not always perfectly aware of every initiative that is going one. (This is the nature of open source software. People can just decide to start doing something.) IBM’s own XL C/C++ compiler has hooks to offload parallel code sections to Tesla accelerators, but it is not clear if IBM is supporting OpenACC directives. (Given that IBM is not on the OpenACC support list, probably not, but given how strongly that IBM wants to sell Power-Tesla hybrid systems, this seems odd.)
This is not the end of the expanding support, hints Wolfe, and this is interesting because many DSP and FPGA coprocessors actually have ARM CPUs embedded in them. The DSPs look promising, but the FPGAs, not so much, as far as Wolfe is concerned.
“You can imagine at some point doing a DSP as an attached device,” says Wolfe. “We are approached by the FPGA makers every year or so, asking when are we going to support them. The FPGA is a different ball of wax entirely. The code build process takes hours, not minutes, and you are lucky if it is only hours and not days, so that changes the behavior of the tool. You are also limited by the number of gates on the FPGA, not by the number of lines of code, and so you can’t really put a whole program on the FPGA but only one particular algorithm. And the penalty for making a bad decision is so high that you need much, much more user input to make sure you are generating good code because otherwise you are going to be generating really bad code. There is no intermediate step. There is no market, and there is no hope. It is a research project, not a product. There are PhDs waiting to be written there.”
Obviously, with much talk out there about FPGA acceleration, and Intel shelling out $16.7 billion to buy FPGA maker Altera, there is plenty of room for debate on this point. And, quite possibly, heated debate much as there often is in the discussion about OpenACC and OpenMP, another parallelization method that predates OpenACC. ) One would expect GPU chip maker Nvidia and its arms-length compiler subsidiary to prefer the hybrid CPU-GPU approach to any other. Suffice it to say that cracking the programming issue for FPGAs, which are about as easy (or difficult) as you might expect when thinking about coding hardware, would be a boon for the IT industry. Who would not want truly programmable hardware if it was easy?
The OpenACC effort is not limited to compiler makers, of course. There are over 10,000 programmers in the world who are familiar with OpenACC, and lots of other formal projects outside of the vendor community.
Technical University Dresden has done the work to put OpenACC support into code profilers, and Allinea and Rogue Wave Software have support for OpenACC with their parallel debuggers. Rounding out the efforts are a number of initiatives at the national labs and academic institutions, including the OpenARC effort at Oak Ridge National Laboratory, the OMNI effort at RIKEN and the University of Tsukuba, the OpenUH effort at the University of Houston, and the RoseACC project at the University of Delaware and Louisiana State University. Nvidia has also packaged up the PGI compilers, the Nvidia profilers, and code samples and released it as the OpenACC Toolkit, which is available for free to academics to help spur its adoption.
OpenACC functionality keeps growing because of all of these efforts, with three releases in the past five years:

As for the future, the OpenACC community is working on a feature called deep copy, which is a way of handling nested dynamic data structures that are spread across the CPUs and GPUs in systems. Basically, sometimes you want to move the entire structure from one device to another, including all of the data structures on which it depends. The community will also be taking on the hierarchical memory that will be coming out in compute elements such as Intel’s Knights Landing Xeon Phi and future GPU accelerators from Nvidia and AMD. All of these will have one form of high bandwidth main memory or another, and very likely links to system-level DRAM and other non-volatile memory like 3D XPoint, and OpenACC is going to have to deal with this. Similarly, OpenACC will have to be aware of the virtual memory enabled between GPU accelerators and CPUs.
Looking even further ahead, there will often be multiple devices in a system – we can envision applications that might offload to a mix of accelerators as well as running on portions of multicore CPUs – and the OpenACC community will be looking at better ways to handle that. In a sense, the CPUs are serial computation accelerators and network cluster links for the GPUs in hybrid systems, with the GPUs doing most of the parallel computation. So treating them more generically and as equals of a sort might be necessary. Particularly in a future where systems have a mix of accelerators, including GPUs, DSPs, or FPGAs (however much Nvidia may not believe in the latter).
As for the choice between OpenACC and OpenMP, Poole pointed out that he is a member of both communities and that many people are involved in both camps. His advice is to code now and that the method of parallelizing, is valuable and the effort will not be wasted. Wolfe echoed these sentiments, and shared the following chart, which showed a comparison between OpenACC 2.5 and OpenMP 4.0:

“The real issue is which one, OpenACC or OpenMP, solves the issue for the users,” explains Wolfe. “OpenMP is richer and has more features than OpenACC, we make no apologies about that. OpenACC is targeting scalable parallelism, OpenMP is targeting more general parallelism including things like tasks, which in some senses are inherently not scalable. OpenMP has a lot more synchronization primitives, and if you are talking about scalable parallelism, that is just a way to slow your program down. The important differences are performance portability – and at SC15 you heard that it is either important or impossible – and we are saying that it is not only important and possible, but that we are demonstrating this today.”
The reason this is the case, says Wolfe, is because OpenACC uses descriptive directives in the code and has the compilers figure out how to parallelize the data and the code that chews it.
“OpenACC says this is a parallel loop, go run this as fast as possible on the hardware I have, while OpenMP doesn’t ever really say that, but rather says it has created some parallel threads and go spilt that loop over those threads. And if they have SIMD parallelism, it won’t do that unless you tell it. OpenMP is very much prescriptive and very much directed by the programmer. OpenMP can be written as a mechanical, source-to-source preprocessor and has been, and that can be considered a strength as well as a weakness. It is just a different. But when you get to the point where you want performance portability – where you want to run the same program on your multicore X86, or Knights Landing, or multicore ARM, or Power plus GPU, or what have you – they have very different parallelism profiles, very different amounts of SIMD parallelism, and very different numbers of cores, different sorts of sharing of memory and hierarchy models. That all plays into how you generate code. And in order to get good code from a single source, you need a mechanism that provides flexibility in how that parallelism gets mapped to the target hardware. This is where we think OpenACC has a distinct advantage.”
To make its point, PGI released some performance specs on OpenMP and OpenACC in its compilers running the same code on multicore CPUs and CPU-GPU combinations. Take a look:
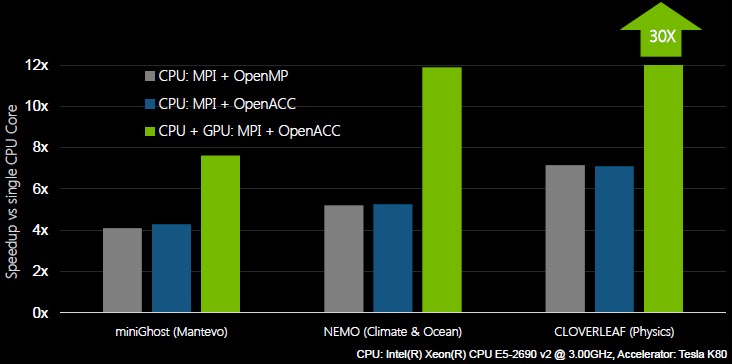
Ultimately, the OpenACC and OpenMP communities already have to work together, and they share ideas as well. Wolfe says that some of the features developed for OpenACC in the past five years have made their way into OpenMP, and that “this has worked pretty well.” And, furthermore, Wolfe says you can run OpenACC inside of OpenMP, with multiple host threads controlling the same or multiple GPUs.
All of this begs the question of whether OpenACC and OpenMP should just merge. “Originally, that was the intent,” says Wolfe. “But we have to get over this descriptive versus prescriptive issue.”
Still, Poole says that “OpenACC might be the best thing to ever happen to OpenMP” because it is driving innovation in parallelism that OpenMP can take advantage of. Just like InfiniBand was probably the best thing to happen to Ethernet, too, to draw a parallel of sorts.




Be the first to comment