

Without any new plain vanilla processors from Intel, IBM, Fujitsu, AMD, or the relative handful of ARM server chip makers, and with Nvidia launching its Tesla M4 and M40 accelerators aimed at hyperscalers and those looking for cheap single-precision flops ahead of SC15, the “Knights Landing” Xeon Phi chip was pretty much the star of the high performance conference as far as compute is concerned.
We covered the news about the Knights Landing processor from the show, but still learned a few new things from Intel’s executives at the event. We also got to peek at some of the iron that various server makers are working on as they prepare to ship production systems concurrent with Intel’s volume shipments for Knights Landing, now set for an unspecified time during the first half of 2016.
Intel is clearly taking as little more time to ramp up the yields on the 14 nanometer processes used to etch the latest Xeon Phi chips, and given that at more than 8 billion transistors per die, it is also the largest chip that Intel has ever made, this is doubly complicated. (As one Intel engineer once quipped to us, no processor chip in the history of the IT business has ever come out on time.) Given the market these Knights Landing processors are aimed at, we expect for Intel to make a big splash for Xeon Phi – including various SKUs, pricing, and volume – around the time of the ISC2016 supercomputing conference in June in Frankfurt, Germany.
Judge for yourself how late that is, but Nvidia did not get a “Maxwell” GM100 GPU Into the field this year with double-precision oomph, either, and seems to be waiting instead to deliver the “Pascal” GP100 GPUs for its Tesla compute engines in 2016. AMD is similarly not ready to launch the next generation of its FirePro S series accelerators, either. Everyone knows what everyone else is and isn’t doing and what is in play in the RFPs at the major supercomputing centers.
Here is what the Knights Landing wafer looks like:

Yes, it would be a lot of fun to throw that a very long distance. . . .
After talking to several Intel executives, we also have some thoughts about how Intel might broaden the appeal of the Xeon Phi as a processor in compute clusters. The organizations that have Knights Landing chips in operation now – Cray, CEA, and Sandia National Laboratories – are using pre-production silicon in their test systems, and Charles Wuischpard, general manager of the HPC Platform Group within Intel’s Data Center Group, said that most of Intel’s system partners were now sampling silicon, too. Intel is expecting to roll out the standalone Knights Landing, which is a bootable single-socket chip like a regular Xeon E3 or Xeon E5 that can run Windows Server or Linux.
As we have discussed before, Intel has talked about three different variants of the Knights Landing processor that it plans to bring to market. One is a standalone, bootable processor; another is a bootable processor with two integrated Omni-Path fabric ports (also known as the Xeon Phi-F); and the third is coprocessor form factor like the current “Knights Corner” Xeon Phi 3100, 5100, and 7100 series. Here are their basic feeds and speeds:
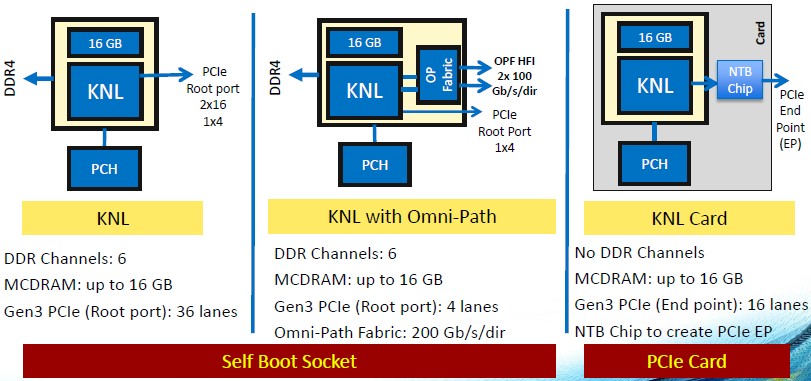
Intel revealed the memory hierarchy and addressing schemes in the Knights Landing chip back in March, explaining how the mix of local MCDRAM on the Knights Landing package and DDR4 memory that is on the motherboard (but controlled from on-chip memory controllers) like regular servers can be used in different ways, depending on the workload. The first mode is the 46-bit physical addressing and 48-bit virtual addressing used with the current Xeon processors, only addressing that DDR4 main memory. In the second mode, which is called cache mode, that 16 GB of near memory is used as a fast cache for the DDR4 far memory on the Knights Landing package. The third mode is called flat mode, an in this mode the 384 GB of DDR4 memory and 16 GB of MCDRAM memory are turned into a single address space, and programmers have to allocate specifically into the near memory.
In early tests using the STREAM Triad memory bandwidth benchmark, the 16 GB of MCDRAM near memory delivered more than 400 GB/sec of aggregate bandwidth into the cores, while the 384 GB of DDR4 memory did more than 90 GB/sec. Intel has not revealed the clock speed on the MCDRAM memory, but the DDR4 can run at up to 2.4 GHz.
Intel initially did not say what the integer performance ratings are for Knights Landing, except to say it would be around 3X that of the predecessor Knights Corner chips. But back in August, at the Hot Chips 27 conference in Silicon Valley, Avinash Sodani, chief architect of the Knights Landing chip, did a detailed presentation with lots of juicy block diagrams and presented some performance figures that compared a 72-core Knights Landing chip to a two-socket server using the 14-core Xeon E5-2697 v3 processors, which clock at 2.6 GHz. (Intel has not disclosed the clock speed for the Knights Landing chip, but we think it will vary from 1 GHz to maybe 1.3 GHz, depending on the SKU. Sodani also revealed in August that the Knights Landing chip has a total of 76 cores, with the four extra ones being there to increase chip yield, not to boost performance.) The single Knights Landing processor had what looks like about a little more than half the integer rate performance (as gauged by the SPECint_rate_base2006 test) and about the same integer performance per watt. (Those two Xeons burn about 290 watts, and the Xeon Phi comes in at around 200 watts.) As for floating point performance, Intel has said that the variant of Knights Landing with 72 of its 76 cores active (four of them are spares to improve manufacturing yield) will deliver more than 3 teraflops of double-precision and more than 6 teraflops of single precision number-crunching capability.
Having gone through all of that, here is the new bit of data. We knew there would be two Knights Landing chips plugging into standalone sockets, with both near MCDRAM and far DRAM memory to keep the processors fed, and one of them with an integrated Omni-Path fabric. We also knew there would be a coprocessor that had local MCDRAM but that did not have its own DDR4 memory. But Wuischpard confirmed at SC15 that there will be yet another variant: a standalone processor that does not include MCDRAM at all. Why would Intel do that?
“The Top500 measures flops, and in some ways that is an evil task master to keep on the flops wagon,” Wuischpard explained. “But we will have Knights Landing available without any MCDRAM as an option, and you could buy that and of course it has lots of low-power cores and good bandwidth and the flops remain the same. If you add 16 GB of MCDRAM, you get dramatically better memory bandwidth, but memory bandwidth does not get picked up by LINPACK really. So there is a lot of cost and benefit in these processors that won’t be picked up in the Top500 ranking, and it is a challenge. How do you help a customer who wants to be at a certain position in the Top500 but get them a proper part that screams for everyday use? This is always the case. You can buy a bragging rights system, but it won’t be a very usable system, and our goal is to have a very usable system at all scales.”
It is interesting to contemplate what workloads – in modeling and simulation as well as machine learning and data analytics, and that are not sensitive to memory bandwidth – that could make use of such a MCDRAM-less Knights Landing part. Whatever workload that might be has to be able to handle clocks speeds in the range of 1 GHz or so and work within the 192 GB memory footprint per socket that will be available on a Knights Landing node using 32 GB DDR4 memory sticks. (No one will buy 64 GB sticks, they are just far too expensive.)
While we were talking to Wuischpard, we suggested that another possible tweak to the Knights Landing chip would be to support FP16 16-bit, half precision floating point math. Back in March, when Nvidia was talking about its Pascal GPUs for its Tesla coprocessors, the company revealed that it would offer such capability on its future GPUs. Here’s why. On machine learning algorithms, having more data is better than having half as much of more precise data. By shifting to 16-bit data formats, you can put a dataset into the GPU buffer memory that is twice as big as using 32-bit data formats, which researchers are finding yield better results, and often faster, too.
The math units on the Knights Landing chips are hefty. Each modified “Silvermont” Atom core on the Knights Landing chip has two AVX512 vector processing units, and a tile, which has two Atom cores and four vector units, can process 16 double precision and 32 single precision operations per clock cycle. Or, we think, perhaps 64 half-precision operations per cycle, effectively doubling the MCDRAM memory to 32 GB and the DRAM memory to 384 GB (using 32 GB memory again) as far as the dataset size is concerned.
It’s a thought experiment, and as far as we know, FP16 support is not in the Knights Landing chip. But presumably it could be added with a new stepping – particularly if some hyperscalers and cloud builders wanted it for their machine learning. The mixed precision is also fine for certain image processing and signal processing workloads, apparently. The Knights Landing chip could be partitioned on the fly, allocating cores to various workloads in wired and wireless networks, too. And, given the fact that it runs Windows Server, we think that there is a very good chance that Microsoft will use Knights Landing chips as accelerators on its Azure cloud and possibly on its own infrastructure.
The point is, the third generation of Xeon Phi chips is more than a product for HPC. But, it will definitely get its start in HPC.
Knights Landing Show And Tell
With more than 50 companies gearing up to sell systems using Knights Landing, this is a pretty decent ramp for a product that might eventually sell into the high tens of thousands to low hundreds of thousands of units, compared to around 20 million units a year for the workhorse Xeon E5 processors.
We saw a couple of interesting Knights Landing machines at SC15, and the first we have already detailed, which is the Sequana supercomputer design by the Bull unit of Atos for CEA. The Sequana design puts three Knights Landing or three dual-socket Xeon E5 nodes on a tray and packages them up in very dense racks that load front and back. Eurotech also hinted at its own plans for Knights Landing in its Aurora blade and Aurora Hive super-dense machines, which we have also covered already. We caught sight of the Penguin Computing Open Compute sleds – the Tundra OpenHPC systems – back in March, and these were on display at SC15, too. The Penguin Computing setup has 81 nodes in an Open Compute rack, which works out to 243 teraflops and an expected power efficiency of 10 gigaflops per watt. This is about double the efficiency of the machines near the top of the Green500 supercomputer rankings.
We also spied two Knights Landing nodes that will be sold by Fujitsu in a compact design, too, but one that still thinks at the chassis level instead of at the rack level like the Bull and Eurotech machines mentioned above. The future Primergy CX series machine, which has not been named as yet, can put four half-width Xeon Phi nodes in the front of its 2U enclosure and four more in the back, for a total of eight sockets in a 2U space. This is pretty good density, given that hyperscale servers can generally only cram four two-socket servers into a 2U enclosure. The Fujitsu Knights Landing design will come in an air-cooled variant that has a single PCI-Express 3.0 x16 slot and a single 2.5-inch drive for expansion on each sled, while the second variant will have water blocks to cool the processor and memory. Here’s what the air-cooled version looks like:

And here is what the water-cooled version looks like:

As you can see, the water cooling hoses take up the space for the local drive for storage, but you still have the PCI-Express slot for network expansion. But the water cooling allows all eight of the nodes in the 2U chassis to run with the full complement of 384 GB of memory across those six memory slots in each Knights Landing socket. Techies at Fujitsu told us that the air-cooled variant of the future Knights Landing machine could only have 70 percent of its memory installed (meaning less dense memory sticks or fewer of them, you pick) because it would overheat. (Water blocks on the memory might help here.) Either way, the impressive thing is that Fujitsu is able to deliver 504 teraflops per standard 42U rack, with either air or water cooling.
Cray has also cooked up its own Knights Landing nodes. This one is for its CS Storm rack-mounted clusters:

And this one is for its XC40 supercomputers, which employ the “Aries” interconnect and which put four Knights Landing nodes on a single blade:

You can see the Aries network ASIC to the left on the XC40 blade above, and the special tubular heat sinks that Cray uses for the transverse airflow system it employs to blow air across racks, side to side, instead of through racks bottom to top.
Hewlett-Packard Enterprise was showing off its future Knights Landing systems, too. Here is a shot of the company’s homegrown system board, code-named “Lancelot” of course:

And this is the Apollo 6000 server tray, code-named “Realm,” that makes use of that Lancelot board:

Dell was showing off its Knights Landing system designs at SC15, but these were under non-disclosure to prospective customers and were not out on the expo show floor.

A Cornucopia Of Memory And Bandwidth In The Agilex-M FPGA
When it comes to memory for compute engines, FPGAs – or rather what we have started calling hybrid FPGAs because they have all kinds of hard coded logic as well as the FPGA programmable logic on a single package – have the broadest selection of memory types of any kind …

Intel Sometimes Charges A Hefty Premium For Sapphire Rapids
No matter what, and without any excuses about Moore’s Law slowing down, those buying compute, storage, and networking expect at least one thing in any generational leap in a device: That the cost per unit of capacity goes down. And for the hyperscalers who run massive applications, they look at …

Intel’s “Ponte Vecchio” GPU Better Not Be A Bridge Too Far
It is pretty obvious to everyone who watches the IT market that Intel needs an architectural win that leads to a product win in datacenter compute. And it is pretty clear that the top brass at Intel are putting a lot of chips down on the felt table that the …
The usual rational for FP16 in ML applications is that it allows the model to be twice as big, rather than the data. The data is still sent in as integer/byte bitmaps (in the case of images) or streams of integers (in the case of text). The model parameters themselves often don’t need all the precision available in FP32, so having twice as many of them (or doing the operations in half the time) is really useful.
Knights Landing supports the AVX512F instruction set (see https://software.intel.com/en-us/isa-extensions for details). That includes instructions for converting FP16 format data to or from FP32 data in registers. Therefore Knights Landing can already handle FP16 storage of data, allowing the larger data-sets or model you believe to be necessary for machine learning to be stored. (Of course, this doesn’t allow you to use the 512 bit vector register to be operated on as 32 FP16 values, but it does solve the “no room to store the data” problem).
Similar instructions have been around in AVX on Xeons for a while now, so it’s unsurprising they’re also in KNL, as it is binary compatible (modulo some AVX512 extensions).
FWIW I work for Intel :-).
You can find details of the relevant instructions in the Intel Intrinsics Guide
https://software.intel.com/sites/landingpage/IntrinsicsGuide/#text=cvtph&expand=1618 for conversions from FP16 and https://software.intel.com/sites/landingpage/IntrinsicsGuide/#expand=1618&text=_ph for conversions to FP16
Thanks for that. It will be interesting to see if it can be used in the way that I suggest.
Great article. I want to comment on the rack level configurations of Penguin Computing and Fujitsu from the article and point out a couple of items not mentioned.
As CTO of Penguin Computing, I feel it’s important to be honest with customers when discussing “maximum” configurations. The 81 nodes of KNL quoted for Penguin Computing is a *real*, usable and deliverable configuration that includes everything needed to make a usable cluster. That includes a management network and Mellanox or Intel 100Gb fabric. That means that some RU are taken up with network switches and fabric switches.
The Fujistu configuration assumes a 42U rack completely filled with nodes. No local network switches or fabric switches. That means in a real configuration all those connections need to be routed to another rack someplace with the network equipment. That’s a total of 336 cables leaving the rack and the fabric cables will likely have to be more expensive active optical to make the distance. We don’t think that’s a practical configuration.
By contrast, the Penguin Computing rack has the following advantages:
= 4x ssd drives per air node (2 in water cooled)
= 192GB or 384GB of RAM (no limitations)
= both air and liquid cooled options
= short, copper cables for node to fabric switch connections
= Variety of power sources based on power shelf. 120/208 or 277/480, N+3 redundant (what is the power supply redundancy for the Fujitsu?)
= All service is done from the cold aisle
Sincerely,
Phil P.
Fair point. I was impressed at the compute density in general compared to Xeons. Then again, by the time Skylake rolls around in 2017, Knights Hill will have to double up again. This is a bit like the Xeon-Itanium game of the early 2000s in that regard.