

Whether it is IBM with the data-centric approach to next generation supercomputers or Intel with its scalable systems framework, there is little doubt that these and other major players in HPC are thinking differently about how to architect and benchmark systems in a way that balances floating point performance with the other equally important leg of the stool—data movement.
Accordingly, the emphasis within the supercomputing community on the LINPACK benchmark, which serves as the most well-known metric for determining the relative performance of the top systems on the planet, is shifting. This is not to say that LINPACK and the subsequent Top 500 supercomputer rankings will go away anytime in the foreseeable future as the results provide excellent architectural, geographic, and other valuable information, but system purchase decisions are not being fed by LINPACK performance these days, especially at centers that need to support a diverse palette of applications.
We have seen a turning away from the LINPACK benchmark as a useful real-world application metric for several years now, especially as problems have shifted far beyond how to cram as much floating point capability to a machine and into the domain of data movement. Some centers refuse to even run the benchmark, and while there is always excitement over the fastest and most expensive machines twice per year when the Top 500 is announced, the time is ripe for an emerging effort to take center stage—at least for application owners who want a more comprehensive understanding of existing and new architectures.
“Most new benchmark requests are rooted in the argument that Linpack is a poor proxy for application performance. This is not surprising, as Linpack was never meant to be an application proxy; rather, we chose it for the TOP500 because it is a well-defined, easily optimizable, nontrivial benchmark requiring a well-integrated computer system for execution,” Dr. Jack Dongarra, one of the founders of the Top 500—and current co-collaborator (along with Sandia’s Michael Heroux, among others) of the emerging High Performance Conjugate Gradients (HPCG) benchmark.
With 63 systems on the list for the November, 2015 rankings, the HPCG list is clearly growing (there were only 12 the first time it was run two years ago). The important point, however, is that it will be the list to track closely as new architectures come to fore that offer big computational horsepower but a more balanced data movement emphasis. To get an early sense of the imbalance between sheer floating point performance as measured by LINPACK and HPCG, which measures more closely how large systems deal with I/O, look at the top ten HPCG rankings compared to their spot on the Top 500.
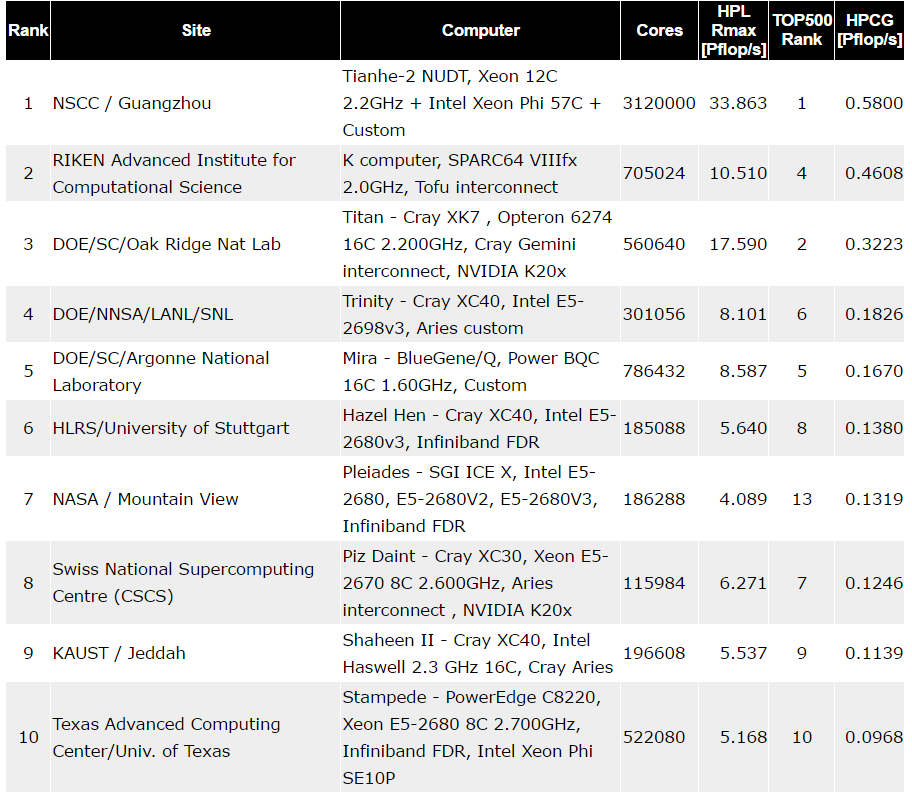
The top ten between HPCG and LINPACK is not hugely out of proportion as most systems are in the top ten on either list, just out of order. But Dongarra says these two lists serve as “bookends” or two perspectives to look to the performance curve. What is also of note on the above list is the variation in different architectures; from SPARC-based machines, those with different interconnects (Aries and the TH2-Express on Tianhe) and further, the mix of machines with and without accelerators or coprocessors. As we move toward systems on the Top 500 that will feature the forthcoming Knights Landing architecture with stacked memory and inarguably impressive bandwidth—and even better performance when Knights Hill emerges on supercomputers like the 2018 “Aurora” machine, the big differences in relative performance between LINPACK and HPCG will begin to come closer in line with another.
“We have a substrate with high performance in the hundreds of cores and very close to it will be very high speed memory modules so there is no more going off to DRAM to fetch data. That time, when the data will be close to the processor itself and easy access to fast memory means a much better balance between data movement and floating point capability.” Right now, as Dongarra argues, things are so out of whack and imbalanced because of the floating point to data movement differences that there is little choice but to look at the two companion benchmarks as anything but different. But not so in the future.
Even the existing processors across the Top 50 have an incredible ability to do floating point. A single core on one of the Skylake or Knights Landing processors can do 32 floating point operations per cycle—and that is just for a single core. If we’re talking above over 70 of those cores on a chip, that’s incredible capability, but for now, there is an incredible mismatch because data is so slow to get to those processors. “If you look at the data rates today, it takes 167 cycles to get a piece of data from DRAM and even with these processors, well over 2000 operations could have been performed in the same amount of time,” Dongarra says.
“There is probably close to three orders of magnitude imbalance between floating point rates and data movements. We see that now, but as architectures like Knights Landing, and to an even greater extent, Knights Hill, start to appear, that will lessen.”
An HPC Benchmark for a Post-Moore’s Law World
If anyone were to look at the relative performance of the top and last systems on the Top 500 going back over the years and into this month’s rankings, it might appear that there is no Moore’s Law slowdown. In fact, that is what Erich Strohmaier, one of the founders of the Top 500, argued this week at SC15. However, that was just part of his point. The fact is, it is difficult to determine whether there is a slowdown just by looking at the trend line. It takes another look instead at performance at the socket level. As Dongarra and his team argued, the increase in the number of cores per socket has given the appearance of a healthy Moore’s Law trend curve, but in fact, it could simply be masking the fact that there are simply less sockets to the count since around 2008.
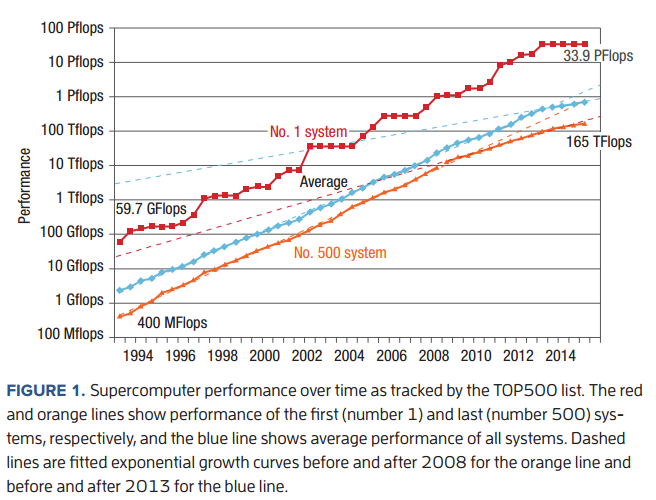
Compared to the exponential growth rate of Moore’s law at 1.59 per year, overall Top 500 system performance had an excess exponential growth rate of 1.20 per year. “We suspected that this additional growth was driven by an increasing number of processor sockets in our system sample (using the term “processor sockets” to clearly differentiate processors from processor cores.) To better understand this and other technological trends contained in the TOP500 data, we obtained a clean and uniform subsample of systems from each edition of the list by extracting the new systems and those systems that did not use special processors with vastly different characteristics including SIMD processors, vector processors, or accelerators,” Dongarra explains. To these points the average number of sockets for this subsample of systems is shown below.
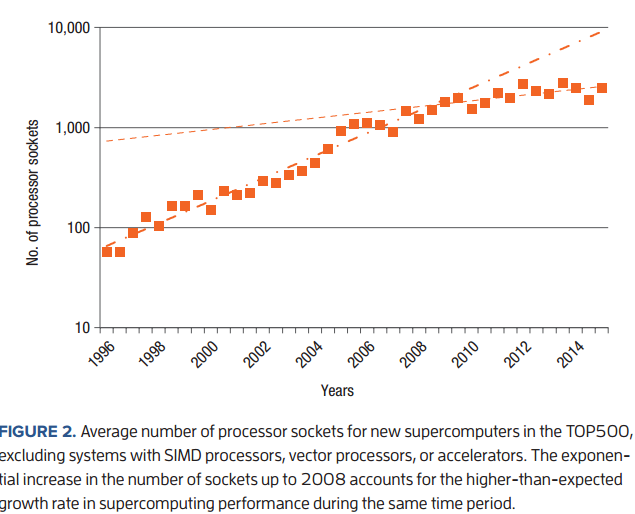
Clearly, the increasing number of cores per socket has compensated for stagnant core performance in the latter half of the past decade. Dongarra explains that the changes in the overall growth rate since 2008 can be attributed mostly to a decline in the growth rate of the number of sockets and hence components in large-scale HPC systems, which has been a very modest 1.07 per year. “The impact of this observed slowdown is quite profound: prior to 2008, overall TOP500 system performance increased by a factor of about 1,000 over an 11-year time period; after 2008, it increased by only a factor of about 100 in the same time period (extrapolated to 11 years). Our data attributes this trend mostly to reduced growth in system size as measured by the number of processors and not to reduced performance growth for the processors themselves. This slowdown will only compound the projected decline in performance growth as we approach the end of the decade and Moore’s law.”
Since the future of systems from Knights Landing and eventually Knights Hill rely far less on upping core counts on big machines and instead balancing the I/O with the compute, using Top 500 alone as a metric to determine Moore’s Law stability is not a good measure. However, as bookends, to Dongarra’s point, it will get easier to see how the balanced system concept plays out–and how irrelevant the Moore’s Law hubub is when one starts taking a look at HPCG and how actual applications perform.


Real-World HPC Gets the Benchmark It Deserves
While nothing can beat the notoriety of the long-standing LINPACK benchmark, the metric by which supercomputer performance is gauged, there is ample room for a more practical measure. It might not garner the same mainstream headlines as the Top 500 list of the world’s largest systems, but a new benchmark …

Nvidia’s “Grace” Arm CPU Holds Its Own Against X86 For HPC
In many ways, the “Grace” CG100 server processor created by Nvidia – its first true server CPU and a very useful adjunct for extending the memory space of its “Hopper” GH100 GPU accelerators – was designed perfectly for HPC simulation and modeling workloads. And several major supercomputing labs are putting …

Dennard Scaling Demise Puts Permanent Dent in Supercomputing
When the TOP500 list of the world’s most powerful supercomputers comes out twice a year, the top-ranked machines receive the lion’s share of attention. It is, after all, where the competition is most intense. But if people had given more scrutiny to the bottom of the list, they would have …
Be the first to comment