

If ARM processors are going to get traction in the datacenter, they will have to do so outside of the conservative glass houses of large enterprises. Applied Micro, one of the upstart makers of server-class 64-bit ARM server chips, knows this, and therefore it is no surprise that the company is on hand at the SC15 supercomputer conference talking up its plans for the future.
Applied Micro has two of its X-Gene family of ARM server chips in the field, with the third one on the way. The company is a little bit behind on its rollout, but that is understandable given the complexity of delivering an ARM server chip with brawny cores, as Applied Micro is doing after getting a full architecture license from ARM Holdings, the steward of the ARM instruction set. Getting the hardware and software ecosystem for ARM server processors in synch has been a challenge, but there is plenty of talk among the hyperscalers and HPCers that the market needs an alternative – meaning that these organizations, which buy in the thousands to tens of thousands of units, want one – and this is significant because it is precisely them who will be the early adopters, if for no other reason to play and to get leverage over Intel. This is ever the way with any company that attains a dominant position in any market. The profit pool attracts piranhas.
To those who think that ARM options can’t cut the HPC and hyperscale mustard, an ARM core with reasonable integer performance can be paired with a GPU or FPGA to offer accelerated compute, and most of the ARM vendors are delivering their threads as cores and not as simultaneous multithreads, which AMD could possibly be adding to its “K12” chip but which Applied Micro and Cavium Networks, the two companies that are shipping ARM server chips today do not seem to be interested in.
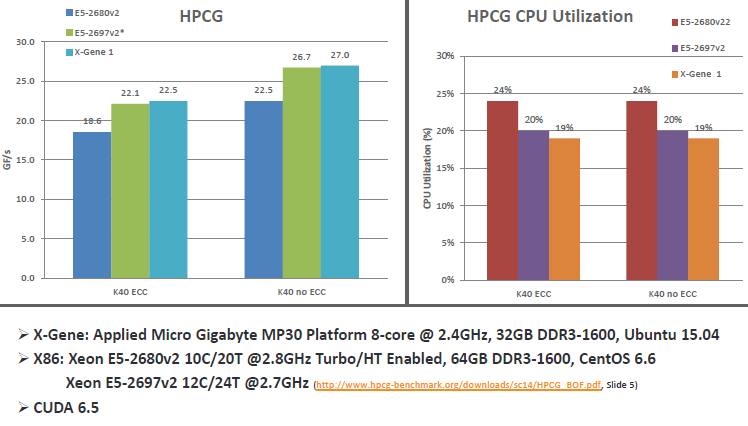
As an example, here are some benchmarks that Applied Micro is showing off at the SC15 conference this week, sowing the X-Gene 1 chip versus Xeon chips when paired with Tesla K40 GPU coprocessors from Nvidia running the new HPCG supercomputing benchmark test:
The big news at SC15 is that Applied Micro is previewing its “Skylark” X-Gene 3 processor, due next year, and is also talking about a new processor interconnect called X-Tend that will allow the company to create server nodes that span up to eight processor sockets. The relative beefiness of the X-Gene 3 cores plus the NUMA interconnect, says Kumar Sankaran, director of engineering at the chip maker, will allow the company to take on the X86 hegemony in the datacenter.
Paramesh Gopi, CEO at Applied Micro, tells The Next Platform that the X-Gene 3 chip will be etched using the 16 nanometer FinFET 3D transistor processes from Taiwan Semiconductor Manufacturing Corp, putting it more or less on the same process footing as Intel’s 14 nanometer processes that are used for future “Broadwell” and “Skylake” Xeon E5 processors for workhorse two-socket servers. The Broadwell Xeon E5 v4 chips are expected in the first quarter of 2016, and the latest we hear is to expect the Skylake Xeon E5 v5 (not to be confused with Applied Micro’s Skylark) sometime around the middle of 2017. (You can see our detailed coverage of the Broadwell and Skylake chips at this link.) The word we hear on the street is that plenty of hyperscalers and HPCers are very interested in the X-Gene chips but they have to keep it on the down-low because everyone, including their server manufacturing partners, does not want their competition or Intel to know what they are up to. The competition between Xeon and ARM will break out into the open in 2016, and it will be raucous if the industry knows what is good for it.
Gopi revealed a few feeds and speeds about the X-Gene 3 chip, which is based on a customized ARMv8-A core. (Applied Micro was the first publicly announced ARMv8 licensee and has been doing custom cores from the get-go.) The X-Gene 3 chip will have up to 32 cores and clock speeds of up to 3 GHz, and it is the shift to 16 nanometers that is allowing for the clock speeds to be increased a little and the core count to be quadrupled. The X-Gene 3 will have eight DDR4 memory channels with speeds up to 2.67 GHz, allowing it to have memory bandwidth that is competitive with Xeon and maybe even Power processors, and will sport up to 42 PCI-Express 3.0 lanes for peripheral interconnects. Depending on the comparison, the X-Gene 3 will offer somewhere between 4X and 6X the performance of the prior X-Gene 1 chips, which have been shipping for a year, and the X-Gene 2, which has been shipping since the first quarter of this year in proof of concept machines.
The plan for the X-Gene chips has shifted a bit over the years, but the roadmap is essentially the same even if it has been pushed out a bit. Some of this is due to market timing issues – particularly relating to the software stack – and some of it is due to the somewhat pesky shrink down to 16 nanometer chip etching processes. (Intel has had similar issues moving from 22 nanometers to 14 nanometers, and has even said that the pace of Moore’s Law is slowing.) Applied Micro got the “Storm” X-Gene 1 processor to market in 2014, which was an eight-core chip running at a peak speed of 2.4 GHz with two integrated 10 Gb/sec Ethernet interfaces on the die; it had four memory channels. This X-Gene 1 chip, said Applied Micro executives back in the summer of 2014, had more performance than the “Seattle” eight-core ARM chip from AMD, ThunderX 24-core chip from Cavium Networks, and the “Avoton” Atom C2000 chip from Intel, but had a little less oomph than the “Ivy Bridge” Xeon E6 v2 processor from Intel. (Those are per-core, not per socket, comparisons.) The X-Gene 1 chip was implemented in TSMC’s 40 nanometer processes, so it had some limitations in terms of how many cores it could have crammed on it.
The plan for the “Shadowcat” X-Gene 2, which was sampling in the summer of 2014, was to have it come in variants with eight or sixteen cores, with clock speeds ranging from 2.4 GHz to 2.8 GHz and adding Remote Direct Memory Access (RDMA) functionality to the on-chip Ethernet to reduce its latency and make the chip more appealing to hyperscale and HPC organizations. The extra cores and other features were enabled by a shift to 28 nanometer processes from TSMC, but for whatever reason, the sixteen-core variant never saw the light of day.

If Applied Micro had to pull back a little on X-Gene 2, it will be pushing harder with X-Gene 3. Back in the summer of 2014, the company was telling us to expect a chip with “a large core count” and hinted very strongly that it would be sixteen cores with a new microarchitecture that allowed it to scale to 3 GHz at a baseline speed and a second generation of support for RDMA over Converged Ethernet (RoCE). The X-Gene 3 chip was in design in 2014 and was expected to start sampling in the middle of 2015. Applied Micro was also hinting that it was working on some sort of interconnect that would allow it to scale up to 64 cores.
We now know that X-Gene 3 will actually have twice the number of cores at 32, and that, says Gopi, is because Applied Micro wants to be able to go straight at the high-end of the Xeon E5 and all of the Xeon E7 line of Intel. The former has high core counts and is often used on HPC systems, and the latter has beefier memory configurations as well as high memory bandwidth and high core counts and is often used for in-memory processing.
ARMed And Dangerous
While that is a lot of scalability for a single socket, that is not enough to compete with either Intel or the ThunderX chip from Cavium. Intel can scale up Xeon E5s to two or four sockets in a single system image using NUMA clustering and can push the Xeon E7s to four or eight sockets as well. Cavium has two-socket NUMA with its ThunderX, and will probably be extending that in the next generation of its chips if it wants to take a bigger bite out of juicy server sales.
Applied Micro is not adding NUMA circuits directly onto the die, as Xeon, Power, Sparc, and Cavium ARM chips do, but is rather using a mix of clustering software and PCI-Express interconnects to glue chips together into a single image for an operating system to run on. The NUMA functionality that is being enabled across all of the X-Gene chips – not just the X-Gene 3 coming next year – is based on a hypervisor that Applied Micro created four years ago when it jumped into the server racket called Xvisor, which is short for Extensible Versatile Hypervisor and that runs on ARMv5 through ARMv8 architecture chips and, oddly enough, 64-bit X86 processors. This Xvisor hypervisor will work on ARM chip that do not have integrated virtualization circuits, and what Applied Micro has done to cook up its NUMA scaling is to extend the hypervisor so it pools memory and CPU across multiple X-Gene sockets, in a way that is analogous to a similar tool created for X86 processors by ScaleMP called vSMP. (ScaleMP does not support ARM architecture chips and Applied Micro is not licensing its code.)

The X-Tend NUMA functionality that Applied Micro has cooked up will link two X-Gene processors on a motherboard together gluelessly through their PCI-Express buses, and requires Non-Transparent Bridge (NTB) functionality to work. (NTB is commonly used in clustered storage arrays to tightly couple multiple controllers together to present a single virtual controller image to the storage.) To scale beyond two sockets will require a PCI-Express switch from Integrated Device Technologies or Avago Technologies (which bought PLX Technology a while ago for its PCI switching), and Sankaran tells The Next Platform that when it ships next year, the X-Tend NUMA clustering will allow up to four X-Gene sockets to be linked. (The image above shows four X-Gene sockets per server sled, and has two sleds per chassis.)
Ultimately, X-Tend will be pushed up to providing a single image across eight sockets on a system board, although when that will happen is not clear. Sankaran says that the X-Tend feature will impose a performance overhead of somewhere around 10 percent to 20 percent of the aggregate compute capacity of the processor sockets in the system, depending on the configuration. (NUMA overhead is higher as the socket count rises.) This is consistent with the overhead on Opteron, Xeon, Power, and Sparc processors, although we are wondering about the performance of NUMA on X-Gene given that it is only talking over a PCI-Express bus instead of something faster. We shall see when performance benchmarks are available.
“So far, there has been zero capability of anybody to capture the high end of the Xeon E5 or even the middle of the Xeon E7,” says Gopi. “This thing fits there, if you want to contextualize it versus X86.”
The point is, Applied Micro can see a way to creating a 128-core system next year that supports up to 2 TB of main memory, and it can do so with an architecture that will very likely allow a motherboard to present a machine as four 32-core machines with 512 GB of memory, two 64-core machines with 1 TB of memory, or one 128-core system with 2 TB of memory. And further down the road, when eight-way scaling is available, 256 cores with 4 TB of memory will be a significant machine, too. A software reconfigurable NUMA machine could be valuable – again, if the software runs scale-up Linux applications well.
That’s the other thing. For the moment, X-Gene chips and the X-Tend clustering only work with Linux operating systems. But we believe that over time, Microsoft will deploy ARM servers underneath parts of the Azure cloud, particularly for SaaS applications it sells or for raw infrastructure services like cold storage. For all we know, Microsoft has already done this, but what we do know for sure is that if ARM servers offer compelling thermal and price advantages and can compete with Xeon E5s on performance, we will have a real race in the datacenter. If Microsoft can embrace Linux, as it has, then it can also embrace ARM. And what Microsoft embraces, it extends. That much as not changed. And so, we believe that ultimately there will be a Windows Server variant for ARM chips.
But Applied Micro does not need Windows Server to get started, any more than other ARM chip suppliers do. “If you look at what really drives this market, it is open source software – machine learning, real-time analytics, large scale-out databases and the operational applications associated with them or frameworks like Spark,” explains Gopi. “If you ask the services providers, they want to ape Google and Amazon and they do not want anything proprietary. So what they want is more cores, more functions on the chip, and the ability to elastically allocate memory to compute.”




I see they are comparing an Xeon processor released in 2013 [1] to their own product released almost two years later [2]. Why not compare to Haswell (v3) Xeon processors?
In any case, what sense does it make to compare them when both are paired with an NVIDIA K40? Why not compare just the CPUs?
[1] http://ark.intel.com/products/75277/Intel-Xeon-Processor-E5-2680-v2-25M-Cache-2_80-GHz
[2] https://www.apm.com/news/gigabyte-and-appliedmicro-announce-commercial-availability-of-gigabyte-mp30/