

When is the right time to get rid of servers and storage and replace them with shiny new gear? The answer is not just a matter of preference, but one that has to take into account the needs of applications, the cycles of the underlying technology, and the rules governing the accounting of capital assets.
It is hard to generalize, given all this. But the bell curve of answers to that question seems to fit a pattern that a lot of large enterprises, cloud builders, and hyperscalers have come up with from their own experiences, based on conversations that we at The Next Platform have had with many organizations over the years. And the anecdotal evidence also jibes with the suggestions kicked out by financial modeling tools created by experts who used to design datacenters and systems at Google and Facebook.
What you have to remember is simple: Three years seems to be about the right age to retire a server or storage server. There are, of course, exceptions to any general rule, which is why Amir Michael, who was a hardware engineer at Google and then a hardware and datacenter engineer at Facebook, founded Coolan last year. The idea is to make decisions based on actual data about the health and reliability of individual components in systems as they are running in the field and using sophisticated financial and capacity planning tools, and that is precisely what Coolan is doing. The Coolan service is now monitoring thousands of servers out in the field and Michael wanted to share some insights that have been gleaned from the early adopters as well as offer up a thought experiment about system lifecycles and how this meshes with his own experiences and those of his peers who run datacenters.
First, the thought experiment. Back in May, Coolan created a total cost of ownership model, which is embodied in a Google Docs spreadsheet, of course, that it used to show how companies can figure out if they should deploy their applications in a cloud or deploy infrastructure in their own datacenters or in co-location facilities. To make a point about how you have to think about the issues, Michael built out the model with a comparison for co-lo and datacenter options and drilled down into power costs, and showed that the cost of electricity was a negligible factor in overall datacenter costs. In the cloud versus co-lo versus datacenter example, the Coolan model took different numbers of compute and storage servers and compared the cost of using cloud or doing it in-house. The upshot there was that if you have a workload with lots of compute and very little storage, clouds like AWS always win. If a workload is heavy on storage with very little compute, then somewhere at around 500 storage servers it makes sense to think about owning your own gear and using a co-location facility and at 1,000 storage servers, it makes economic sense to build your own datacenter.
In the latest thought experiment, Michael wanted to see how long companies should take to upgrade their storage servers – the dense machines that are crammed with fat SATA disk drives at hyperscalers and cloud builders the world over and that are increasingly being used by enterprises to host massive banks of object storage. The scenario capped the storage at 100 PB, initially using 4 TB SATA disk drives with a fixed price of $300 per drive and a total of 25,000 drives. A year later, 6 TB drives become economically feasible in volume at $300 per drive, and the model looks at the cost of replacing all of the storage servers – not just the drives, but all of the servers – to get the same 100 PB of capacity. (It takes only 16,667 drives to make the 100 PB, which lowers the storage server footprint count.) After two years, 8 TB drives are available, and after three years, 12 TB drives are available. The consolidation factors are considerable – you could end up with only 8,333 servers after three years – and this set of scenarios ignores any performance factors associated with such a compaction in the number of nodes.
The model has a few other assumptions, including that the power efficiency and cost of electricity of the datacenter does not change over the term of the comparisons. The costs of higher failure rates for keeping older iron around were ignored (these are tough to quantify, which is one of the reasons why Coolan has launched its hardware component monitoring service in the first place), but annual operating expenses for datacenter management and labor to operate and upgrade the systems were included. (We presume these are prorated based on the power consumed for the gear, just as is the case for the datacenter costs themselves, but they are sunk costs as well.) The storage servers are depreciated over a three year span and the datacenter is depreciated over eighteen years.
Here is what the initial installation looks like, costed out over seven years:
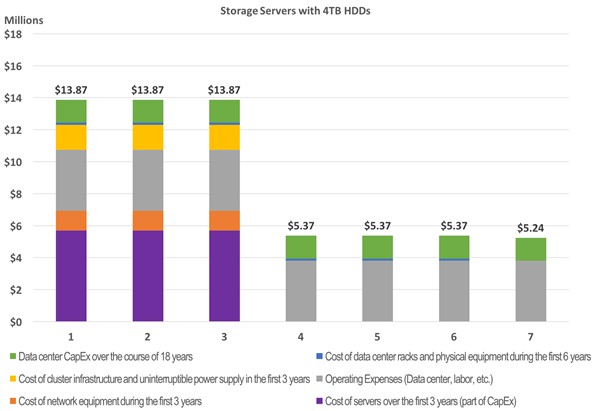
As you can see, just paying for the datacenter capital expense and operating expenses comes to $5.24 million a year. The storage itself costs close to $6 million per year over the three years it is amortized, and adding in datacenter and operational costs plus capital expenses for networking gear for the storage servers and racks and uninterruptible power supplies that support the storage drives the overall cost up to $13.87 million for the first three years. Add it up over the first six years, and that 100 PB of storage costs $57.7 million. The operating expenses and datacenter sun costs related to the 100 PB of storage will run out for 18 years. (We would say that people should probably get a cost of living raise in the model, which is not in here.)
So what happens if, one year into this storage pool, the company wants to upgrade to 6 TB storage servers and cut back on its footprint? Take a look:
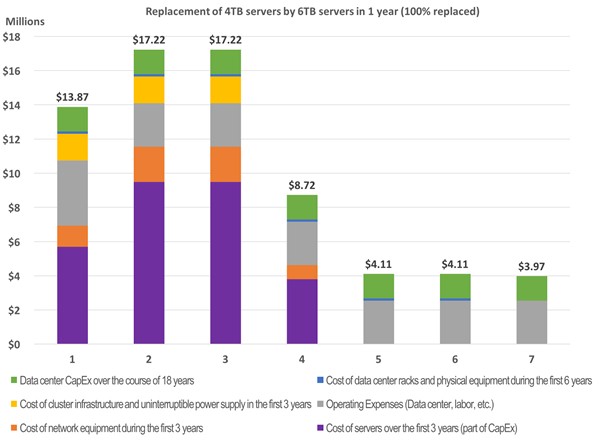
The swapping out of the hardware in the second year to upgrade to storage servers based on 6 TB drives causes a considerable bump in capital expenditures and the original 4 TB storage servers have to be written off as well. It is true that the operational costs fall a bit as the storage server count is reduced. But by the end of year six, the cost of the 100 PB of capacity ends up being $65.2 million, an incremental $7.5 million and, Michael argues, not a smart investment unless something is compelling the technology change. If you wait a year longer, then 8 TB drives will be available for around $300 a pop, and the total cost is only $60.5 million over the first six years. That is still higher than the initial deployment costs, however. But look at what happens when the upgrade is done in after three years, when 12 TB drives are available at the same cost of $300 a drive:
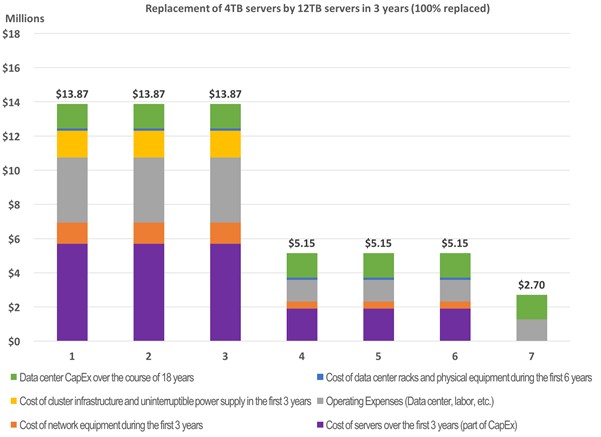
Basically, in the fourth year, the cost of the storage server hardware plus the cost of operating the machinery both come down sufficiently when the machines are swapped out that the six year cost to maintain 100 PB of servers comes to $57.1 million, essentially the same cost as keeping the storage servers based on 4 TB for six years. If you start taking into account disk drive mortality and very likely the desire to expand capacity beyond 100 PB, then moving to denser, newer storage seems rational and a cycle to replace the machines after three years of use seems to make both economic and technical sense.
Three Is The Magic Number
The three year lifecycle for servers and storage arrays is typical among hyperscalers, although there are exceptions. Amazon is widely believes to be using old disk arrays on the edge of its network to host its Glacier archiving service, which is a bit slower than its S3 service but is a lot less costly at 0.7 cents per GB per month. The rumor that Michael heard about Glacier fits with what we have heard, which is that Amazon takes vintage arrays that are swapped out from underneath its S3 and EBS services and equips them with its own file system with power down features common in cold storage that extend the life of the arrays beyond the typical warranty of a normal disk drive. (This is akin to the power-down technique that archive specialist Spectra Logic is using in its Verde DPE NAS arrays, and that Microsoft has employed in its Pelican cold storage and Facebook has used in the cold storage that backs its Haystack primary storage.)
As Urs Hölzle, senior vice president of the Technical Infrastructure team at Google, explained to The Next Platform back in March, Google keeps its compute and storage servers around for three or four years in its fleet, and says that the company is constantly weighing the issues of a fully depreciated machine being free, in some sense, against the efficiency benefits of a new machine. Facebook is on a similar cycle, and we presume that Microsoft and Amazon are as well.
The question is how applicable the results shown above are to other kinds of servers in the modern datacenter, and Michael did not have other scenarios ready when we spoke to him. But similar conditions apply, and a similar set of economic and technical rules will come into play.
“In a compute server, which is defined by its CPUs, or a caching server, which uses a lot of DRAM as well as CPUs, these components behave somewhat similarly, even if they might have a different cadence than disk drives,” says Michael. “Every step along Moore’s Law gives you double the performance at the same price and the same power, and you could apply the same models to a compute server and likely the results will be somewhat similar, but the timing might be slightly different.”
Out in the field, Coolan has seen both extremes. Some companies that have eight year old storage servers, and it costs money to deal with the higher failure rates on drives than with newer gear. On the other end, some companies get on the Moore’s Law curve for compute or storage and then reclaim a portion of the machines they discard by reselling them in the aftermarket. “You could make a case that it might make sense to go as fast as two years on your upgrade cycles,” says Michael – particularly if the datacenter is running out of floor space or power or both. But that presumes that you can find a buyer for your used gear.

The Last Hurrah Before The Server Recession
Excepting some potholes here and there and a few times when the hyperscalers and cloud builders tapped the brakes, it has been one hell of a run in the last decade for servers. But thanks to the coronavirus outbreak and some structural issues with sections of the global economy – …

Intel Back To Playing The Long Game, Not The Wrong Game
The supply chain is holding back the server business, and not just in the way you are thinking. Yes, there is a limited supply of manufacturing and packaging capacity for server-class processors based on the most advanced semiconductor nodes. It’s in the less obvious ways, such as the availability of …

Server Spending Measures Aspiration As Much As Oomph
Sometimes, to get the proper perspective, you have to take the long view. And other times, you need the extremely long view. It is with this in mind that we ponder the nature of the IT sector, the impact that the coronavirus pandemic is having on it, and prior crises …
Be the first to comment