
Long before it became the cloud computing juggernaut that it is today, Amazon was a fast-growing online retailer that bought its servers from traditional suppliers, starting with Hewlett-Packard and then moving on to Rackable Systems, an innovator in high density rack designs that is now part of SGI. But five years after its foray into cloud computing, Amazon Web Services did what most of what its hyperscaler peers did, and that was design its own custom switches and servers.
At the re:Invent 2015 conference last week in Las Vegas last week, Jerry Hunter, vice president of infrastructure at AWS, talked a bit about why the company started building its own custom machinery for its cloud operations. Hunter did not reveal the specific designs of its custom gear – those are trade secrets that give the company a competitive edge – but there was a little show and tell, which is always fun.
The central idea that Amazon, the retailer, is based on is a virtuous cycle that brings an ever-widening product line to an increasing base of customers that allows it to leverage its scale to command the lowest prices and therefore to make it up in volume. Amazon Web Services, explained Hunter, is no different in this regard.
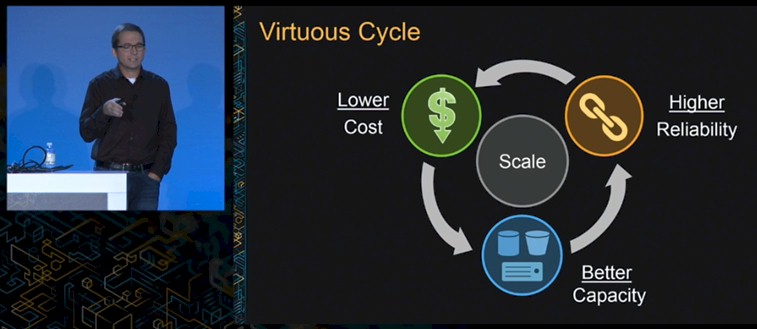
The virtuous cycle for AWS is that it provides capacity on demand for over 1 million customers, who have very different needs that often vary by the minute, and yet are a lot easier to do capacity planning for as a group than they are individually. Creating minimalist machinery that only has the hardware features and software functions that the AWS cloud requires and by having sophisticated redundancy built into the network of machines in its datacenters, availability zones, and regions, gives AWS some important leverage that is simply not available to most large enterprises, who operate at scale to be sure, but not hyperscale.
“It turns out that scale lets us doing some interesting things, from building our own networks and building our own servers to building our own datacenters,” Hunter explained, adding that Amazon was involved in selecting and designing everything from the smallest components in its server and networking gear all the way out to a 200,000 square foot datacenter facility.
“This ability to customize allows us to remove a lot of excess features, and allows us to simplify a design, both from a reliability perspective as well as from an operational perspective. This in turn allows us to work with OEMs and component manufacturers to make sure that our capacity is always there, that hard disk, memory DIMMs, racks, servers, networking gear, and even transformers are forecast and stocked and ready for on-demand. Less complexity in the gear means fewer things to break. This also gives us deeper understanding of all of these components, which means more automation and less human intervention and less human error and also leading to higher reliability.”
The cycle turns, driving higher reliability and driving down costs, and as this happens, AWS is better able to compete better against its rivals – which are not so much other cloud providers as on-premise datacenters. More customers coming into the AWS fold increases its scale even more, cranking the cycle one more time and frankly making it that much more difficult for other cloud builders to catch up.
And as James Hamilton, distinguished engineer at AWS who masterminds its system and datacenter designs, has pointed out many times years gone by, it is far easier to plan for capacity next week than it is four to six months from now, so shortening the time it takes to make systems and having a supply chain that can deliver gear in a steady flow, with some ups and downs, is critical if the goal is to not overprovision capacity. Compute and storage capacity may be elastic on the AWS cloud, but Amazon’s balance sheet is not.
Contrasting Post Dot-Com With Cloud Era
Hunter has plenty of experience running IT infrastructure. He spent a few years at Sun Microsystems as a services and support engineer and then moved over to managing the enterprise Java stack for the former system vendor that is now part of Oracle. A decade ago, Hunter moved up to take over Sun’s datacenters, and in 2007, he was put in charge of corporate applications at Amazon and eventually was responsible for moving the retailers applications to AWS. Once that was accomplished, Hunter moved into his current role of managing the AWS datacenters and their server and switching gear.
Back at Sun, Hunter said that server utilization used to be somewhere between 11 and 15 percent, and with some huge engineering effort, moving applications to containers in the Solaris operating system controlled by Sun, the company was able to get it up to 19 percent utilization, on average. Some of this excess capacity was due to application and system design, but a lot of it was due to the fact that Sun had to stand up server capacity to cover its peak workloads.
“This all made compute and storage pretty expensive,” said Hunter, and then he regaled with a scenario that will sound all too familiar to large enterprises. “Because utilization was low and the cost of the machinery was high, we really didn’t experiment all that much. Experimentation means that you don’t really know if the application is going to do what you need it to do, if the application is going to differentiate your business. And so, instead, we would spend time to ensure that an application would do what we needed it to do. That meant that we had lots of meetings. We met with the finance team, we met with our business partners, we met with the leadership team, and ultimately, if we got ourselves comfortable that this application was worth pursuing, we would look to see if datacenter space and networking available, and if there was, we would collectively argue about whether or not that datacenter space would be reserved for that application. And if there wasn’t, we would argue about whether or not we would go build this extra datacenter or networking space, which was also underutilized and expensive. It would take three to nine months before we could deliver this capacity to the developers. Not a lot of experiments got past this development stage, but when they did, we were using pretty high-end servers. On the one hand we were pretty happy with the reliability, but on the other, they were missing features that we wanted. The added complexity led to operational issues, which sometimes resulted in outages. This led to a vicious cycle – added complexity led to lower reliability led to lower utilization, and the end result of this vicious cycle was a lot of wasted money, a lot of wasted time, and some frustrated developers.”
The big problem at Sun, Hunter concluded, was that it did not have the scale in its own IT operations to break the vicious cycle.
A key factor in breaking that cycle for AWS was building its own gear, and incidentally AWS started with custom networking equipment in 2011 before it moved to custom servers in 2012. (As usual, Google was way ahead on custom servers, with its first server racks being installed in 1999 and its first custom switches in 2005.) All of the hyperscalers have the same complaints about closed box, appliance style networking equipment, and that is that the devices have to support a wide variety of protocols and have closed APIs that are only accessible from tightly controlled software development kits from switch vendors. These companies want to be able to hack a switch like they can hack a server or storage array, and they are willing to buy switch ASICs and ports and slap together their own iron and Linux-based network operating systems to get only and precisely what they need and to automate the management of switches as they have servers.
Hunter flashed up this image during his presentation:

Presumably this image is of a rack of switching gear in an Amazon datacenter – that was certainly the implication. But if you look carefully, as we do here at The Next Platform, this image is of two racks of “Jupiter” switching gear that Amin Vahdat, a Google Fellow and technical lead for networking at the search engine giant, revealed back in June. (The image is at the bottom of the story, and you can see that they are the same.) We are not saying that Amazon is using Google’s switches, because Hunter surely did not say that, and we cannot imagine why the two would share technology when they are at war in the clouds, but that is a peculiar image for Hunter to have used. We have calls into Google and Amazon for an explanation, and incidentally, the picture in the Google blog post talking about Jupiter gear had been removed when this story was being put together. (It is back up now.)
Hmmmm.
Back in November 2013, at a prior re:Invent conference, AWS distinguished engineer James Hamilton showed off some images of homemade AWS servers and switches, and here is what a switch looked like:

As for custom servers, here is what Hamilton showed back at re:Invent two years ago:

And here is a rack of servers that Hunter revealed at this year’s re:Invent conference. Presumably this is an Amazon design and not one from someone else:

The pair of server racks that Hunter revealed is very interesting. It looks like a slightly taller rack than a standard 42U rack, and the height is not obvious the way the picture is taken. Two switches are on the bottom of the rack and feed network links to five and maybe a half enclosure above it. We can see two more enclosures above another pair of switches; there could be space for more. The server enclosure has room for ten server nodes – five left and five right – that are split by what we presume are two power supplies or peripheral nodes in the center. This is clearly a hyperscale, minimalist design.
The important thing, said Hunter, is that the servers are designed specifically for the software they are supporting, and utilization on those components is very high. (He did not say what the average server utilization was for the machines that comprise AWS, but Hunter did cite a report from the National Resources Defense Council that estimates the average utilization on the public cloud is around 65 percent – more than four times higher than the average server running in a corporate datacenter these days.
The real wake up call for Amazon on its need for customized servers actually came in 2011, when it was launching its first switches, when massive flooding in Thailand massively disrupted the manufacturing of components such as motors, casings, arms that go into disk drives. The factories that made components and that manufactured drives, which accounted for a sizable percentage of the worldwide capacity, were under water for months, leading to shortage. (One factory in Thailand accounted for 85 percent of disk drive motors, and Thailand accounted for 60 percent of worldwide disk drive manufacturing.) So Amazon took over its own component supply chain for all elements that go into the gear in its datacenters and has been managing that, as it does books and myriad other items for its shoppers, since that time. The volume of gear that AWS was buying back in 2011 was not all that much, but now it is and such shortages would cause significant problems for AWS, which is doubling capacity every year for many of its services.
“The lesson we learned is that disasters happen, and you need to be in control of your supply chain,” said Hunter.
And, we would add, you need to leverage that supply chain to the hilt to compete with the likes of Google and Microsoft, which also have taken over their parts supply chains. This, perhaps more than server designs themselves, will make all the difference when it comes to a profitable cloud business. Some competition with the Xeon platform from Intel, from the OpenPower partners and the ARM collective, will no doubt enter into the supply chain equation should Power and ARM server chips prove to have sustainable advantages for server workloads. Time will tell, and we are all waiting to see what might happen. Odds are, we won’t know what Amazon, Google, and Microsoft did until years after they did it.
Bootnote: We got a message from Jim Sherhart, AWS marketing manager, explaining the Google Jupiter picture in Hunter’s presentation:
“This was my mistake. Because we have a lot of IP in our datacenters, we don’t typically show images of them in presentations. I just grabbed what I thought was a generic stock photo from Google Search since it had no branding, trademark, or meta identification. I’ve replaced the image in the presentation. Happy you guys were watching re:invent though :)”
Well, it would have been far more useful if Hunter actually had talked a bit about Amazon’s switches and servers, we think, and perhaps a lot more fun if AWS was using Google switching gear. . . .


Money Keeps Raining Down From The AWS Cloud
Amazon Web Services is not the largest IT supplier in the world, but it is well on its way to attaining that position as it has notched up another quarter of growth in what is a tough economic climate. AWS should surpass Lenovo this year and Dell before too long, …
The Big Clouds Get First Dibs On AMD “Genoa” Chips
The expanded lineup of AMD’s 4th generation “Genoa” Epyc server chips – built atop “Zen 4” core and some with the chip maker’s L3-boosting 3D V-Cache – unveiled at a high-profile event in San Francisco this week is quickly making its way into the cloud. Microsoft and Amazon Web Services both …

Object Storage Makes A Push Into HPC
Four years ago, Cloudian was a six-year-old startup in an object storage space that, while the technology had been around for more than a decade, was seeing a surge of interest from cloud providers desperate for a storage architecture that only could scale to meet the demands of their rapidly …
So when you extrapolate this to the future this means that the big three or four will completely suck up the current supply chain of IT equipment and the rest of the world get the few breadcrumbs. Doesn’t sound like a bright future to me.
Those “Step #5” servers look a hell of a lot like Dell PowerEdge C8000’s or their Dell DCS siblings.