
The cloud doesn’t just provide utility pricing on compute, storage and networking. It is more than various slices of capacity on a single server and aggregations of capacity across blocks of CPU cores and flash or disk drives set up as block or object storage.
Clouds allow for this infrastructure to be as permanent, or as ephemeral, as companies want it to be. As it turns out, a lot of the infrastructure that that companies fire up when it is easy and cheap to do so doesn’t tend to stay alive for very long – not by traditional IT standards, at least. That means the monitoring tools that have been used for physical iron are not necessarily well suited to this cloudy world. These tools expect for iron to come into a datacenter and sit there for three, four, five, or more years and not to vanish like a past thought at any moment.
Monitoring is a little different on the cloud, and the challenge is to take data from the cloud service provider and merge it with the telemetry from the operating system and software stack enclosed in virtual machines and containers to get a better view of what the entire stack is doing. Thanks to a tighter integration with the CloudWatch service infrastructure monitoring service that is at the heart of Amazon Web Services, New Relic’s Application Performance Monitoring can take data from Java, .NET, Ruby, Python, PHP, and Node.js applications and mash it up with metadata from various AWS services to give a much more complete view of what is going on inside that cloudy infrastructure.
These new AWS monitoring features are being announced in a private beta ahead of the AWS re:Invent conference in Las Vegas this week, and can pull data from CloudWatch for AWS services such as EC2 compute instances as well as Elastic Block Storage, Elastic Load Balancing, Elasticache (in-memory caching), Simple Queue Service, and Simple Notification Service. Al Sargent, who is director of product marketing at New Relic, the fast-growing SaaS APM tool provider founded by APM pioneer Lew Cirne that we profiled back in May, says that as far as he knows, the company is the only APM provider that has such integration with the telemetry system of AWS.
The First Priority Is To Gather Telemetry
Monitoring is not an afterthought or a luxury that companies can’t afford. It is central, and the site recovery engineers at hyperscalers like Google, Facebook, Microsoft, and Amazon would be the first ones to tell you this. In fact, SREs would let production, customer-facing applications crash before they would let the monitoring and management systems go down because they know they cannot do root cause analysis on failures and solve problems without massive amounts of telemetry from systems, applications, and users. You can’t manage what you don’t monitor, as the old adage goes.
About half of New Relic’s 12,000 paying customers are sending data to the APM service from AWS services, with EC2 being the dominant one, and many of the virtual machines that comprise the EC2 instances only live for a matter of minutes, hours, or days. (Some are long-lived, of course.) But the idea, in the parlance of DevOps, is that even still, EC2 instances are more like cattle, which have unique ID tags and are fairly interchangeable, and less like pets, which is what any server is when you tape its name on it. (And we have done this, as you have all done, too, so don’t make fun of those who are still doing it.)
New Relic does not divulge how many companies are using its free service tier, but across free and paid accounts it has more than 500,000 system and application administration users, which is a pretty large installed base. And one that must have some pretty fascinating statistics.
To help The Next Platform understand the ephemeral nature of cloudy infrastructure, Sargent pulled out some data on Docker containers, which New Relic has been supporting with its monitoring tool in beta form since May for Linux instances (either on the cloud or on private infrastructure). If VMs like an EC2 instance are cattle, then Sargent says that the containers that are at the heart of microservices are more like bacteria – small and very short-lived.
Since firing up its Docker container monitoring service back in May, approximately 1,000 of New Relic’s customers have turned it on. And through the end of August, those customers had fired up a total of more than 8 million containers with the average of 300,000 containers active over a 24 hour period across those customers. About 11 percent of the containers were active for under ones minute, with 27 percent of the containers were active for less than 5 minutes and 46 percent active for less than one hour. This data is consistent with preliminary stats that New Relic talked about back in June in a little more detail. In that subset of the New Relic data, the vast majority of Docker containers being monitored by the APM tool were younger than a few months (which stands to reason given the length of the private and public beta), but interestingly, if you drill down into the container lifespans, a very large number live only one or two minutes, and then a bunch live for under a half hour with very few lasting longer than that.
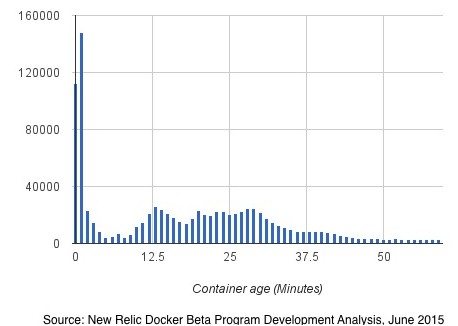
The interesting bit is that these short-lived Docker containers are alive for less time than it takes to boot up a VM image on top of a server virtualization hypervisor.
The new tighter integration between New Relic and AWS CloudWatch is important in a number of different ways, not the least of which is that as far as CloudWatch is concerned, an EC2 instance is a black box that it is not allowed to peer into. So customers who want to do infrastructure and application management need a tool like New Relic even if they use CloudWatch.
The New Relic service integrates with the identity and access management front end of AWS and allows for EC2 and other services to have their data imported in a matter of minutes. The service can see which EC2 instances have New Relic agents on them and are being monitored and which ones are not, and importantly, the tool gets around the “gray server problem” as VMs or containers appear, do their work, and are deleted. With a traditional monitoring tool, these would look like crashed servers and would clutter up the management screen; not a big deal when you have a few dozen servers, but a very big deal when you are monitoring a few hundred or thousand instances on a cloud. New Relic APM can take the AWS metadata and make it sortable by any key in the CloudWatch metadata, from Amazon Machine Image (AMI) type to datacenter and region data as well as custom metrics such as development, test, or production VMs. The New Relic tool also can take in telemetry from agents on iOS and Android client devices, which gives admins a view of the entire application, from cloud infrastructure, to back-end software, to client software. This span is necessary to do performance monitoring and troubleshooting properly, says Sargent.
New Relic, being a public company, is careful about making forward looking statements or disclosing its roadmaps, and Sargent would not comment on whether it would be offering similar tight integration with the management tools for Microsoft Azure, Google Compute Engine, Rackspace Hosting Cloud, IBM SoftLayer, or other large public clouds. But it stands to reason that it will, particularly since many companies want to go hybrid not just between their on premises datacenters and a public cloud, but across different public clouds.
The AWS integration for New Relic APM is in private beta now, and after a select number of customers get to kick the tires for a bit will be released in a public beta for a larger set of users. The general availability for these new features has not been divulged as yet.


Amazon Is The Flywheel, AWS Is The Cash Register
The coronavirus pandemic giveth to Amazon retail business and its Amazon Web Services cloud business, and the pandemic taketh away from the Amazon retail business. That pretty much sums up the third quarter financials of the world’s largest retailer, which is also the world’s largest IT cloud. You may notice …

The World Has Changed – Why Haven’t Database Designs?
It seems like a question a child would ask: “Why are things the way they are?” It is tempting to answer, “because that’s the way things have always been.” But that would be a mistake. Every tool, system, and practice we encounter was designed at some point in time. They …

Vertical Integration Is Eating The Datacenter, Part Two
It is funny to think of the modern datacenter as an appliance, like an iPhone, but in the cases of the hyperscalers and the very largest public cloud builders, this is more or less what they are building. As we pointed out in the first part of this series, best …
Be the first to comment