

Every evolution in computing hardware brings with it big challenges for software developers.
Hyperscalers deal with scale, to be sure, but a lot of their work is just chunking through data in batch mode. At the upper echelons of the supercomputing market, the challenges are arguably the toughest software problems to tackle. HPC shops have to deal with scale and at the same time very complex models and simulations. The situation is not getting easier, but harder.
So the big question is this: What is going to happen when the supercomputer centers of the world have to port their codes to the new breed of high-end systems. If the big machines sponsored by the US Department of Energy are any gauge (and we think they are), then these future systems will pair Tesla GPU accelerators from Nvidia with Power processors from IBM or Xeon processors from Intel, or alternatively will be based on many-core Xeon Phi processors from Intel. (The pairing of Xeon and Xeon Phi is possible, too, and so are hybrid systems comprised of ARM and GPU accelerators.) No matter what direction you look, though, machines are getting lots of cores, hefty nodes, and not enough memory and memory bandwidth to keep them fed.
Glenn Lockwood, who is the HPC performance engineer at the Advanced Technologies Group within the National Energy Research Scientific Computing Center (NERSC), a division of Lawrence Berkeley National Laboratory, spends a lot of time thinking about these issues. As part of his thought process about the future of HPC programming models, Lockwood put together this fascinating chart, which maps out the relative performance of a supercomputer node based on vector, massively parallel processor (MPP), and many-core architectures as embodied by the future Power-Tesla hybrid system called Summit or the future “Knights Hill” Xeon Phi system called Aurora – both pre-exascale systems being built for the Department of Energy. Take a look:
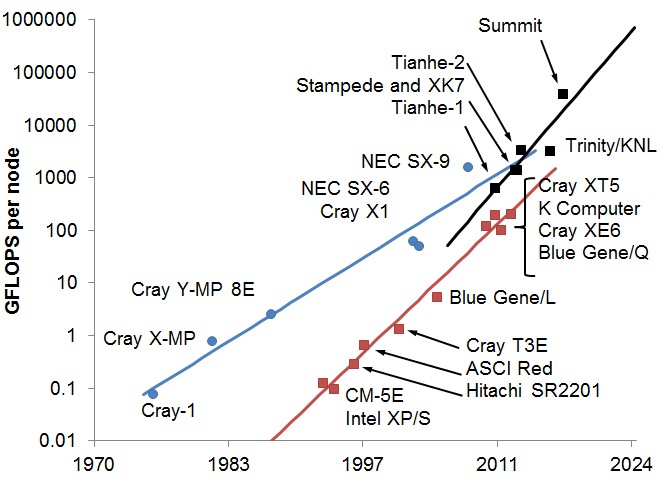
The blue line shows the trend for vector machines, the first supercomputers, and the red line for massively parallel machines, which followed them architecturally. The black line shows the more modern hybrid, many core machines, which are distinct from MPPs in a number of important ways.
“This shows that you have to change things because technology is no longer following the historic trends of vector processors or massively parallel systems,” Lockwood explains to The Next Platform. “New programming models will be needed. The bigger picture is that the capacity of the nodes is going up but the overall size of the systems, in terms of the number of nodes, is not. If you look at Summit, which is sort of an extreme case, it only has around 3,500 nodes, and each one of them is a monster. And just programming in MPI doesn’t work because most of your performance is living on the node, not over the network.”
The Summit machine is being built by IBM in conjunction with OpenPower partners Nvidia and Mellanox Technologies for Oak Ridge National Laboratory, and we have discussed the programming challenges of porting the code that currently runs on the Titan hybrid supercomputer at Oak Ridge specifically and the underlying hardware was drilled into by Nvidia at the ISC 2015 conference earlier this year. The presentation by Nvidia chief technology officer Steve Oberlin compared and contrasted the Summit architecture with that of the Aurora machine being built by Intel with the system integration expertise of Cray for Argonne National Laboratory. But to review quickly: Summit gets its compute from the combination of multiple Power9 processors from IBM and multiple “Volta” Tesla GPU accelerators from Nvidia, providing a total of 150 petaflops across the system and around 40 teraflops per node, while Aurora is based on the future Knights Hill Xeon Phi many-cored processor from Intel, and will have more than 50,000 nodes for a capacity of 180 petaflops, or around 3 teraflops per node.
Getting a set of code to run on either kind of machine – or other hybrid architectures mentioned above – is one thing, but making more codes run across any single architecture and getting any single code to span many architectures makes software porting and development an even more arduous task.
“The issue becomes how do you solve a problem with these two different architectures, and the answer is you have to rewrite your code in different ways,” explains Lockwood. “So that is the approach and they are targeting the same problems. The Department of Energy labs are all running the same sort of codes, and the issue is to find one set of source code that will run well on both of those architectures.”
The Message Passing Interface (MPI) has served the HPC industry well as we moved from vector to parallel and then cluster architectures, and it is the heart of most systems. But Lockwood says that the way that MPI is implemented on hybrid many-core machines is going to have to change.
“But it won’t be one MPI rank per core, which is how people have traditionally done it,” Lockwood says. “So, on BlueGene/Q, there is sixteen cores on each processor and no one is using OpenMP because it just doesn’t work as well as using one MPI rank per core, straight up. The issue in the future is that the amount of memory per core keeps going down, and it doesn’t get better with high bandwidth memory because you have a lot of tiny cores and a fixed amount of RAM. So the programming model is evolving to MPI plus X, which is what a lot of people are talking about, where X is some programming API or language or something that does shared memory and harnesses your on-node compute capability.
Lockwood is working on a much more detailed piece about programming these future systems for The Next Platform, and made the chart above just to gather his thoughts a bit. As he works on this more detailed piece, he did provide some early thoughts:
“OpenMP is the most obvious thing to add, for the very near future, but you can’t run OpenMP on GPUs. So the question becomes, what can you run on GPUs? You can use OpenACC, but that really doesn’t work too well on CPUs and who knows what it will do on Knights Landing and Knights Hill Xeon Phis. That is what is interesting and what is an open question.”
But just for fun, Lockwood says there is also talk about finding a different way of sharing data across nodes than MPI, which might be a little tough for HPC shops who write their own code or who rely on third party software to think about after relying on MPI for two decades. And given his background in both traditional HPC and data analytics, the answer that Lockwood proposed as a possibility for replacement of or adjunct to MPI did not really surprise us all that much.
“A bigger question is whether MPI will be the choice for programming these machines. The memory is diverging so much, there are such gaps between the interconnect performance, the memory performance and capacity, and the amount of flops you can turn out, the bytes per flops, and things like this. There are new models being put forward to work around that. Instead of doing things in a synchronous way where you have one MPI rank sending something to another and that other thing receives it, there are a lot of these remote memory access, single-sided approaches that are getting a lot of traction. Since you have a throughput-optimized node instead of a latency optimized node, you start hiding the fact that everything has latency with just a ton of concurrency with non-blocking communications and things like that, and then you just synchronize this as few times as you can. The Spark in-memory processing framework might not be that irrelevant to exascale, and that is because the Spark model being synchronized very lazily. We only do it when you really need to and let the program proceed forward until it actually asks for the synchronous, holistic answer. So that is a model that people are talking about, but whether it ends up being the model remains to be seen.”
Clearly, with Summit, Aurora, and similar machines being many years into the future, now is in fact the time to be pondering the possibilities. Stay tuned for further insight from Lockwood as he puts his thoughts together on how this might all work.

Edge. Smart Cities. Retail AI. Oh My!
Regular readers of The Next Platform know there are few more attention-grabbing tech events than Nvidia’s GPU Technology Conference (GTC). From high-end graphics card updates to a wide array of end user stories and technical deep dives, there’s something for everyone, up and down the stack: hardware and software alike. …
Finally: Some Good News For The Intel Xeon CPU Roadmap
It was a reasonable enough gut reaction given the many changes happening at Intel in recent months. The chip designer and maker – the last one in the world that does both – had announced a datacenter product line update for Wall Street analysts only a week after Raja Koduri, …
Deep Dive Into Nvidia’s “Hopper” GPU Architecture
With each passing generation of GPU accelerator engines from Nvidia, machine learning drives more and more of the architectural choices and changes and traditional HPC simulation and modeling drives less and less. At least directly. But indirectly, as HPC is increasingly adopting AI techniques, having neural networks learn from real-world …
One question I asked around and haven’t yet got a satisfying answer: Why is AMD HSA not getting any traction in HPC?
Because AMD currently and probably also for the foreseeable future is pretty much irrelevant in the HPC sector. If you look more carefully you will notice that HSA or AMD;s implementation of it in its own APU design actually didn’t gain any market traction anywhere in the consumer space either not in desktop, laptops, leightweight laptops, tablets, convertibles or you name it. What makes you think it would be such a difference in HPC sector? Only because it looks good on paper?
Huh? Why not OpenMP maybe you should double check your statement again as OpenMP4 spec does include support for accelerators which last time I checked would also include GPUs.
What a programming nightmare is being foisted on poor HPI application developers with this CPU + GPU + cluster model! Debugging concurrency issues and race hazards across one homogenous set of parallel entities is bad enough. Debugging simultaneously in three dimensions, with each dimension having its own properties and eccentricities, is going to be very ugly!
I think it’s fair to ask if it will work at all.