

We can rent as much or as little compute capacity or storage or connectivity as we want, and we can get it when we want it. And we don’t have to maintain or account for any of that hardware. What a great idea, this cloud. Why hasn’t that been done long ago? And the companies providing all of those resources have been increasingly making it easy for us to use. Life in the IT world sure seems good.
Those providing the cloud to us, though, know that – as with most everything – this good life comes with a few trade-offs. It is absolutely not that these caveats are hidden, it’s just that it takes some technical background to easily explain. Why is it, for example, that one day my cloud-based application’s performance is great and the next day it’s not, even with all else – from our point of view – being equal? The possible causes are really not that hard to get your head around. So we are going to here focus on Processor Virtualization, a set of technical concepts which underlie at least part of the cloud.
Do you really have a choice to not understand this? As I read in a recent article on The Next Platform: “Companies today operate with one foot on-premises and one in the cloud. This combination of private and public assets delivering essential business services is known as the hybrid enterprise, and it has become the new normal. While this model can reduce costs and improve employee productivity, it can also be a nightmare for IT to manage.” A little bit of extra knowledge ought to help here.
We will absolutely be talking about what drives performance, but this isn’t – and it should really go without saying – an article on computing performance in general; it’s an article on the differences between the public and private asset usage.
So, sit back, and let’s build a few mental images on what is really going on up in those clouds.
The Starting Point
Sure, part of the beauty of the cloud is that you can rent its resources. But it is enabled by a rather simple fact; you are typically using only a small percent of the compute resources available on the hardware on which you are executing. If you are using – say – only 10 percent, why are you paying for the other 90 percent as well? Instead, rent what you need.
Those running the cloud, of course, have and have paid for the hardware and so all the compute capacity that comes with it. And often lots of it. And they are perfectly willing to allow you to share – up to some limit – that hardware, pay a nominal amount for the privilege, and still be guaranteed that you are functionally isolated from all the other cloud dwellers. That is what processor virtualization is really all about anyway; sharing the hardware in some secure manner, but in such a way that the capacity available in that hardware is being more fully used.
When we see pictures of what really comprises the cloud(s), it sure looks like our own usage footprints are unaccountably tiny within something that unimaginably massive; each looks like scads and scads of compute capacity, memory, persistent storage, and huge bandwidth interconnects. You shout in something that big and expect to hear an echo; that is, even if you could hear anything other than the cooling fans.
But, no, it’s not really that way. Each cloud is built largely from the hardware that you already know and love. Many are massive replications of one to a couple boards supporting an SMP (Symmetric Multi-Processor), each with one to a couple processor chips, each chip with a large handful of processor cores, each with quite a bit of cache, and total memory within striking distance of a terabyte of memory. And these building blocks, in turn, support connections to neighbors, other I/O devices, and the outside world via the likes of PCI-Express, Ethernet, InfiniBand, and more. Compared to not too long ago, even these individual SMP building blocks are powerful entities. And, for those that need more, more at a higher price, there are still larger SMP systems – or such with the likes of GPUs – that could be similarly replicated. the cloud isn’t so much a massive fog bank as it is a large number of hot snowballs; it’s a Cloud because you don’t need to know where you are while in it, not that it is all yours to use.
These SMP units might all seem big in their own right – the compute capacity of multiple tens of processors and hundreds of gigabytes of memory after all – but they are finite. And the Cloud provider’s job is to meet and exceed your performance needs, decreasing your costs, while also minimizing their costs – which include huge energy costs – and maximizing their profits, while fitting you and others within these finite resources. Load balancing to accomplish this is raised to a high science here.
They are not giving your OS instance and its applications an entire processor board; they instead provide you with something much more abstract, Compute Capacity. You and tens, hundreds, perhaps thousands of other OS instances – a.k.a., partitions – share the overall capacity of a single SMP unit. Again, you are not buying or even necessarily leasing a particular number of processor cores, you are sharing this resource and leasing some part of its capacity.
You contracted for a certainly level of capacity; so did many, many others. the cloud providers take your desired and actual performance needs, look at the capacity available in each and all of their actual and currently active hardware, adjust for energy usage, and decide where in this huge cloud your partition gets to reside for a while; residing there, in that SMP unit, along with a whole bunch of others.
That’s the starting point. We’re next going to dig down a bit and see what that means and how you may feel it.
What is Capacity?
Have you ever watched the CPU utilization graphs on your workstation? For most purposes, it’s OK to use CPU utilization as a very rough measure of how much more work can be done by your processors. But for this discussion, let’s assume that CPU utilization provides some considerable precision in the measure of capacity.
Suppose that you are measuring some unit of work that you are calling a “transaction”. Let’s suppose that, right now, you system is knocking off 1,000 transactions/second. And you have noticed that the CPU utilization is – say – 20%. What is your automatic assumption about your system’s available capacity? You are likely thinking that that 20% CPU utilization means that my processors can take on 5 times more work. I should, therefore, be able to get roughly 5 times as many transactions – 5 times as much throughput; this assumes that that SMP is processor – not I/O – limited. So, 5 times 1,000, the total capacity available is around 5,000 transactions/second. Again, that is what your automatic take-away is when you look at CPU utilization.
You might also have measured your transaction-based throughput over time, noting all sorts of interesting relationships about transaction rates over time, perhaps even mapping that onto CPU utilization. You may even have gone so far as to determine the core-count compute capacity needed to drive this throughput over time; if your 16-core system was often at 25 percent utilization, perhaps you could get the same work done with 4 cores. You’ve noted that typically you have needed only a small fraction of your – say – sixteen cores; you could have gotten by with the capacity available in these many fewer cores, but very occasionally you know you could use more. Nice work. You are ready to buy into one or more of the Cloud’s economic offerings.
Believe it or not, you have made a lot of assumptions in that nice analysis, many of them sufficiently valid, others – well – we’ll be talking about them shortly.
Capacity is conceptually close to the notion of throughput. Having the ability – the opportunity – to produce higher throughput – higher transactions/second – also means having higher capacity. Transaction rate is a measure of throughput; capacity is the maximum transaction rate that can be achieved. It is not: How much is in your bucket? It is: How large is your bucket?
Capacity can be a function of single-threaded performance, but those two concepts are very different. Certainly, the sooner that a single thread can get its work done on a processor core, the sooner that that processor becomes available to do the next item of work. That faster single core can mean more capacity. But, depending on the type of work, more slower processors can also produce the same capacity.
What Is Available?
There are a lot of different Cloud Service providers, but let’s pick on just one, mostly to get a concept across, not because it is or is not superior.
If you visit the Amazon Web Services (AWS) site and look up pricing, you will notice that they are pricing at least partly based on the notion of an ECU (EC2 Compute Unit). At some level, this is a self-referential value representing the relative compute capacity of each of their offerings. A 26 means that such an offering has roughly twice the capacity of a 13. With that knowledge alone, however, you realize that you have no idea what a 13 represents. Digging further, you learn that a single ECU represents the compute capacity of a single and particular design-point processor core with a particular cycle time; this reference system would be assigned the value 1. An ECU roughly represents the performance capacity available in a processor core, albeit of a particular older core. It is a stable, unchanging, measure of capacity doing some mix of work on that processor. OK, that may help, but you still don’t necessarily have a reference to your world. I mean, how many of your own transactions/minute could you have produced with an ECU of even 1?
The ratings like 13 or 26 – or what have you – are determined via multiple benchmarks and performance test magic, run on the hardware environment in question, with results compared to the reference system. The Amazon folks know full well that there are a lot of different ways to use these systems and their performance environments sample some of these. Please realize, though, that amongst these there can be considerable relative variation from workload to workload and even more as we go from system to system. As they say, “Your results may vary.” These ECU ratings result from a mix of the chosen workloads; any one of the workloads may or may not produce twice the throughput on a 26 versus a 13. So they use a mix; they could publish all their results, but we all want a quick relative capacity reference like ECUs. Still, it is a good approach, if what you are looking for is a single-number representation of relative capacity.
Explaining a tad further: Even using a single core, there are a lot of ways that a given rating can be achieved; via hardware technology, cycle time, fine-grain parallelism, cache size and topology, bus bandwidth, memory speed, and so on. We could also roughly double the capacity from 13 to 26 by doubling the number of cores. Again, such differences in design may mean differences in the performance of specific workloads.
That’s AWS. Other systems attempt to represent their system capacity using other conceptually similar ratings. (As an example, from my own IBM Power Systems background, there is CPW, short for Commercial Performance Workload and based loosely on the TPC-C online transaction processing test.) Some offer considerably finer granularity on the capacity of your instance. And that is what you are buying, the capacity of an OS instance, typically a fraction of the capacity of an entire single SMP. So the point is: What you are really getting with ECU is a statement of the fraction of the total capacity available within some larger physical SMP system. The OS instance you purchase is sharing the same hardware – at least for a while – with some number of other instances; each is getting some fraction of this overall capacity. As mentioned, the cloud service’s job is partly to determine how best to pack them together, given each such instance’s capacity requirements.
Distinct from ECU, AWS has another metric they call a vCPU, short for virtual CPU. Others have related concepts like VP (virtual processor). I will be using both terms interchangeably. This, too, is an abstract concept. What it is not is some particular core within some SMP that your operating system instance holds indefinitely. Each VP is instead an abstract entity to which the OS assigns work (a.k.a., work being a task or a thread). When your operating systems’ VP is found to have work dispatched to it, that VP subsequently gets assigned to a core for some period of time. The distinction might seem subtle at this point, but it is important to performance in ways that we’ll get into shortly. A VP is not a core, it is an abstraction of a processor.
So, when you say that your OS instance has – say – four vCPUs, what you are really saying is that your OS knows of four entities to which it can dispatch tasks. It does not mean that your OS at that moment has four particular cores – and the capacity that they represent – upon which your tasks can execute their instruction streams. A vCPU instead represents a maximum level of SMP processor parallelism possible. A vCPU rating of four means that an OS can have four times as many tasks concurrently executing than is possible with an OS having vCPU count of one.
In a way, the VP count also represents a maximum capacity in that a four-VP OS is limited to that number of concurrently and continuously executing tasks; you get no more throughput than is available running constantly with four VPs, just as you get no more than if running continuously on four cores. If there were no notion of an ECU and only vCPU count to represent capacity, a vCPU value of four says that you have up to the capacity of four concurrently executing tasks if continuously executing. The ECU capacity value, then, becomes a capacity limit less than this vCPU-based maximum.
It is worth noting that what constitutes a VP or a vCPU is inconsistent across providers. We’ll be getting into this more shortly – and the related important performance effects – as we later discuss multi-threading, but some VPs are associated with complete cores and others are associated with the hardware threads of multi-threaded cores.
As a conclusion on this section, two concepts were outlined:
- You can rent compute capacity representing some fraction of the total compute capacity of some single SMP.
- You can specify the level of SMP parallelism; how many tasks can be executing concurrently.
But always picture that there are other OS instances just like yours which may be – or may not be – sharing the same processor resources.
What Is A Processor?
It used to be that the terms – Processor or CPU – were fairly well understood. But both hardware and software changes have made both rather ill-defined and often misused. Consider SMT (Simultaneous Multi-Threading) or the roughly analogous Intel’s Hyper-Threading. In both of these, the better defined notion of a processor core is enabled to allow it to simultaneously execute multiple instruction streams. Rather than tasks / threads being dispatched one-for-one to processor cores, these cores can be thought of as concurrently executing instructions on behalf of multiple threads.
So why bring this up in a discussion on virtualization? Answer this: What is a VP or vCPU? Is a VP a core with all of its SMT hardware threads together, or is a VP a single hardware thread, one of multiple within a core? In the latter, a VP represents the execution of a single instruction stream; in the former, a VP represents the instruction streams of multiple tasks.
Given that there is no performance difference, the question could be considered moot. But there is a difference and it is quite significant.
As a mostly conceptual example, consider the following taken from a figure representing the throughput gains on a Power8 processor of having up to eight threads per core. From a total throughput point of view, each core has considerably more capacity – more throughput potential – because of 8-way SMT (a.k.a., SMT8); a Power8 core can support up to 8 threads. That extra capacity is a good thing. But also notice the throughput of a reference thread – say, the one in blue – as it first starts out alone on a core (i.e., the bar on the left) and then shares the same core with one, then three, then seven other threads. That thread’s individual throughput falls off considerably. This is completely normal behavior; each thread may be slower, but because of SMT, at least it is executing; the same thread would have no throughput during the time it is waiting for an “SMT thread” if such an SMT capability did not exist.
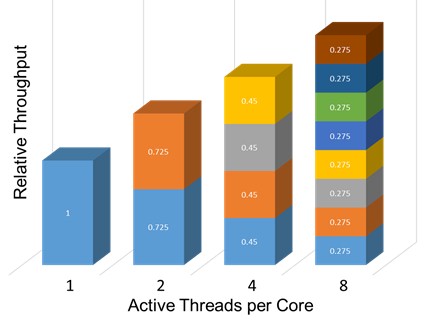
So why the tutorial? Remember the question? Is a vCPU associated with a complete core – here capable of supporting up to 8 threads – or is a vCPU associated with a single SMT thread – one of up to eight on each core? If the latter, a physical core is then also supporting multiple vCPUs; recall again that when defining a new OS instance, you also define the maximum number of VPs/vCPUs you intend to use. So if you specified two VPs, are you getting up to the capacity of two cores or of two SMT threads?
For now, let’s say that a vCPU is an SMT hardware thread, not a complete core (with multiple SMT threads). Let’s also assume that you have an OS instance with two vCPUs and they are both assigned tasks, meaning that both want to be assigned to a “processor.” It is completely possible that your OS’ vCPUs could be assigned to different cores and no other OS’ vCPUs at that moment share the cores. Great. Your tasks are getting to use the full resources of those cores and, as a result, execute as fast as they can. Or, say, your operating systems’ vCPUs could be both assigned to the same core. OK, if alone together, they are both executing, but each slower than in the previous case.
But the cloud is not really about executing alone in an SMP; there are other operating systems with their vCPUs are well sharing the same system. So let’s ramp up the systems utilization and have other operating systems be busy as well. Where are their vCPUs assigned? Sure, they could be temporarily assigned to different cores, but their vCPU(s) could be assigned to the same core(s) where one or more of your operating systems’ vCPUs are assigned at that moment. In comparison to executing alone on a core, as the system’s utilization ramps up, there is an increased probability that your vCPU(s) will be sharing cores and so running relatively slower.
Said differently, suppose that your operating system has only one vCPU – and so just one thread – active right now. You may expect that that thread ought to be executing full out just like the blue thread in the leftmost column above. Indeed, you might have repeatedly experienced that effect, and not known it; the system was lightly used and that was the result. So let’s – unbeknownst to this OS’ application thread – ramp up the utilization of all of the other operating systems and vCPUs on that same SMP. Your thread will still get to use a “processor”, but now it is much more often sharing a core with a number of other active vCPUs. The result is slower execution. And, because of the expected functional isolation of operating systems, there is nothing within your operating systems that is capable of telling you why the application’s performance slowed.
Of course, the issue is less intense with a maximum of only two threads per core, but the basic concept stands.
So, is a vCPU a core or an SMT thread? For VMware‘s ESXi hypervisor: “Considering that 1 vCPU is equal to 1 CPU is an assumption for the sake of simplification, since vCPUs are scheduled on logical CPUs which are hardware execution contexts. These tasks can take a while in the case of a single core CPU, CPUs that have only 1 thread per core, or could be just a thread in the case of a CPU that has hyper-threading.”
A vCPU with VMware’s ESXi hypervisor is an SMT thread. With IBM’s PowerVM hypervisor, the notion of a virtual processor (i.e., a VP) is different; a VP is associated with a physical processor core, including at once all of the core’s SMT threads. A VP here is not necessarily tied to a particular core; the operating systems’ task dispatcher assigns one or more tasks to a VP – as though it were a physical core – and then the hypervisor assigns the VP to an available core, freeing up a core dynamically if necessary.
See the difference between VMware ESXi and IBM PowerVM? With PowerVM, it is still true that a core can be concurrently executing one or multiple threads. But, if multiple threads, with PowerVM, the threads executing on some core all belong to the same OS. If, say, your OS’ utilization was low enough to have just one thread per VP, those threads will execute alone and therefore faster when each VP is also attached to a core. With VMware, even if your OS has exactly one executing thread – that thread being associated alone with a vCPU – it is possible for that thread to find itself sharing a core with vCPU(s) of other OSes; increased utilization occurring in other OSes can slow another OSes performance.
But it’s not all peaches and cream with PowerVM either. If a VP is active with even one thread, the hypervisor assigns that VP to a core. The entire core’s capacity is being used by that assignment; no other VP can use it then, even though there is only one thread executing there. As you saw in the SMT figure above, with one thread executing, there is actually quite a bit of capacity available, but with this approach it must remain unused. The entire core’s capacity must then be accounted for as being used. VMware, treating each SMT thread as though it were just another physical processor, will instead assign vCPUs (i.e., always one thread) to any available SMT thread within any core. The point here is that with PowerVMs approach, because some capacity can remain unused in a core, other OS’ threads which could use that capacity instead wait their turn for an available core. (Interestingly, I know of at least one PowerVM OS – and so perhaps more – that attempts to pack threads into VPs up to a point in order to decrease this effect.)
A lot of detail, yes, but see the essential effect? The performance of your operating systems may vary based largely upon the level of utilization of the other operating systems sharing – and sharing at this time – the same system.
That is a subject we will talk about in the second part of this series on processor virtualization in the cloud.


Big Iron Will Always Drive Big Spending
Starting way back in the late 1980s, when Sun Microsystems was on the rise in the datacenter and Hewlett Packard was its main rival in Unix-based systems, market forces compelled IBM to finally and forcefully field its own open systems machines to combat Sun, HP, and others behind the Unix …
VMware Partners Its Way Deeper into Cloud, Edge, And AI
Software maker VMware has always been about tight partnerships with other tech vendors. When you are middleware between hardware and operating systems, you sort of have no choice. You need to support a diverse set of hardware below and a rich of operating systems and applications above. During its early …
An Architecture for Artificial Intelligence Storage
As we’ve talked about in the past, the focus on data – how much is being generated, where it’s being created, the tools needed to take advantage of it, the shortage of skilled talent to manage it, and so on – is rapidly changing the way enterprises are operating both …
Be the first to comment