
The entire premise of language and the storage of communication is founded on a principle that we can learn from the mistakes and successes of others. Historically, companies guarded their trade secrets, but tools such as the case study method from Harvard Business School used to train MBAs allowed outsiders to gain some insight into what makes companies tick and succeed. Spying also works, but is usually not condoned.
In the 21st century, we are a bit more open about some aspects of our businesses, and for good reasons of enlightened self-interest. Open source software is entrenched in the datacenter and open source hardware is trying to find its place, and the largest IT users are learning to share the technologies and techniques that allow them to succeed at what they do. This may seem a little counterintuitive, like giving away the candy store, but it serves the purposes of the companies that do it. What they need more than anything is for the cream of the crop of software and hardware engineers to want to work for them, and showing how innovative and open they are turns out to be a pretty good way to attract techies who want to solve difficult and interesting problems.
This, among other reasons, is why Facebook started its @Scale conference series a few years back. The idea is to bring its peers in the hyperscale space together who are wrestling with issues at the leading edge of scale so they can learn how they might cope with similar issues as they grow their own IT infrastructure. As it turns out, of the 1,800 attendees at the @Scale 2015 conference in San Francisco this week, they represented 400 companies that have contributed to over 4,500 open source projects in the past three years that the @Scale series has been running.
This being a techie shindig put together by the social network, Jay Parikh, the vice president of infrastructure and engineering, got to open up the event with his keynote, and rather than trot out some new piece of open source hardware or software that Facebook’s engineers had come up, he talked instead about the ways that Facebook attacks any technical problem. Parikh could have picked any aspect of Facebook’s business to illustrate its approach, but because the company has been working to improve the storing and serving of video content for its 1.3 billion subscribers, this is the example that he chose to illustrate the points. About a year ago, Facebook was serving about 1 billion video views a day from its infrastructure, and this has grown rapidly to 4 billion views today and will probably grow at an exponential rate going forward – particularly if Facebook can solve some pesky engineering problems relating to the speed at which videos are uploaded, encoded, and displayed.
The idea, in case you didn’t catch it, is to give Google’s YouTube a run for the advertising money, but Facebook also expects that it will follow a line from storing and exchanging text to text and pictures to text, pictures, and video and eventually – in the not too distant future – immersive, virtual reality experiences. The amount of iron it will take to do this, perhaps for 2 billion people working over a variety of networks and devices with widely varying capabilities, is staggering to consider. And it is why what the hyperscalers like Facebook and Google are one of the pillars of The Next Platform. What Facebook learns as it tries to improve video serving will apply to other aspects of IT infrastructure.
But the main thing, again, is that the principles Facebook follows apply to any platform and any collection of people who are trying to build it, and are especially important for any product or service that might see rapid adoption and therefore scale issues. These three principles are planning, iteration, and performance.
Planning
“I often think that planning is one of the two bad P words in technology,” Parikh said with a laugh. “Planning and process, we all hate those two words, right? When we started working on this, we realized that we are operating at a terabit scale in terms of our network. So getting it wrong or guessing to figure out how we are going to build this network isn’t going to cut it for us because getting a terabit-scale network capacity plan and performance wrong has massive consequences on not delivering a really good product. So we invested a lot of engineering time developing instrumentation. The instrumentation was something we did from the beginning so we would have this key insight, so we would have this information, and we really want to feed this into building a faster, better, and cheaper network.”
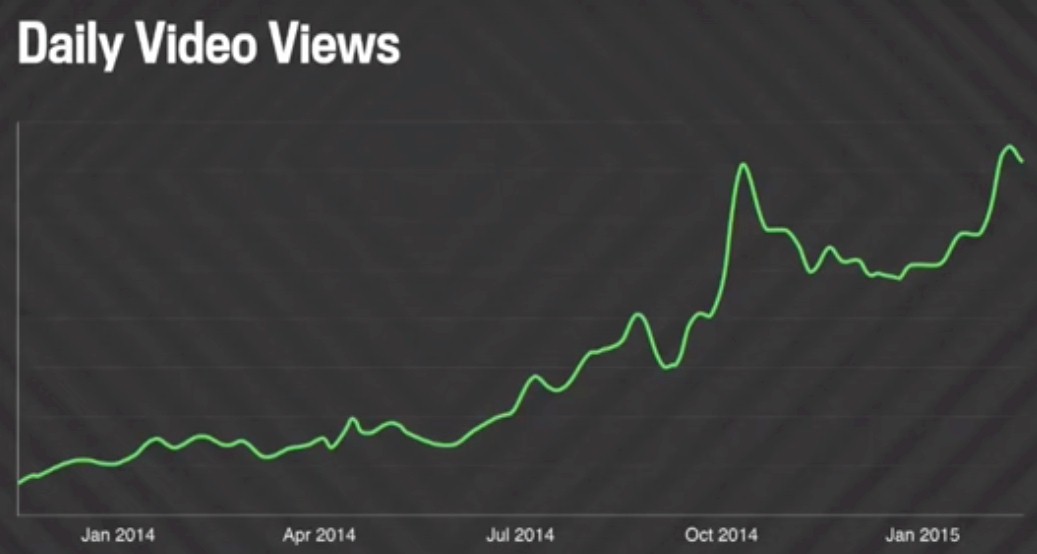
There is a reason why Facebook open sourced its hardware and datacenter designs through the Open Compute Project more than four years ago and is similarly doing so for its datacenter switches. And that reason is the company’s network bandwidth needs are going to skyrocket as it allows users to store video as well as text and photos. Take a look at the curve Facebook is facing:

The company did not show the spike it no doubt saw in network bandwidth as video is taking off, and it did not show the effect of this vast library of video content has on the Haystack object storage that is the heart of Facebook’s systems. Just to give you a sense of how much data we are talking about, Facebook users are uploading 2 billion photos per day, which is around 40 PB of incremental capacity per day that has to be added to Haystack, which for the photo archive alone is well into the multiple exabyte range. How much denser is a video than a photo? How much storage will that be? Seagate Technology and Western Digital just swooned.
The thing that you notice about all hyperscalers is that they are absolutely maniacal about telemetry coming from their systems to tell them everything they can possibly learn about the hardware, software, and user experience. At Google, for instance, the priority for jobs on its clusters is monitoring, production, batch and best effort, the latter being scraps of jobs that can be done any old time. Monitoring comes first.
And it is important to have finely grained telemetry coming out of those systems, Parikh explained, showing a chart of the playback success rate for video on the Facebook network. This looks pretty good, doesn’t it?
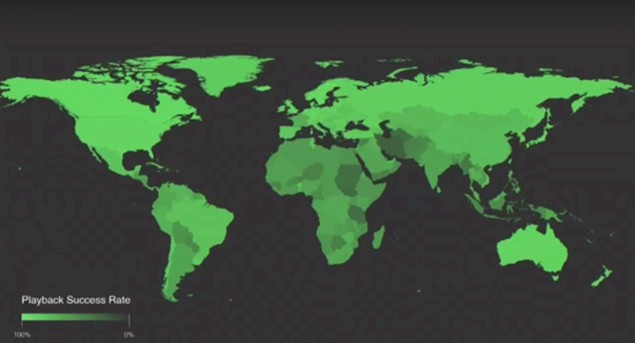
The bright green areas are where the playbacks work almost all the time, and the darker areas are where it is more spotty on the Facebook content distribution network. But there is trouble in that chart.
“These are aggregates, and they can be elusive and misleading in terms of what they are telling you because they are just at the aggregate level,” Parikh said. “Aggregates usually represent some sort of average and averages are evil. Averages really lead you astray in terms of the analysis here. So we spent time getting more sophisticated.” Specifically, the analytics that Facebook culled from its systems and put into this visualization dashboard allows network engineers to drill down into countries, states, regions, cities, and neighborhoods to see how the video distribution is working, and at that level, the data is not so clean looking because of the spotty coverage of carrier networks for wireless devices.
Which brings us to the next principle.
Iteration
Breaking problems down into pieces and making iterative changes to add features or improve aspects of a system is not a new concept, Parikh said, but it is one that Facebook embraces – and uses instead of the word process, which is less descriptive and apparently hated. (See above.)
While that download chart showing the aggregate data by country looked pretty good, when Facebook drilled down into the user experience for uploads – which is important because the content we all upload onto Facebook is the raw and free material that the company peddles ads against – it was not great. Parikh showed a message that someone from India got saying it would take 82 hours to upload a video, which obviously is not going to work.
The engineering problem to get faster and more reliable uploads of video turns out to be difficult. For one thing, Facebook users use tens of thousands of unique device types that all have different amount of memory, different types of processors and compute capabilities, different screen sizes, and varying network connections based on their wireless carriers or wired Internet providers. This makes the upload, encoding, and downloading a complex challenge. And to make matters worse, the video upload application had a big fat button on the screen saying Cancel Download, and 10 percent of the time users did that by accident.

So the engineers iterate, and keep trying to solve the problem, bit by bit.
“Believe it or not, most of the world is not on LTE and is not carrying around an iPhone 6 or 6S now,” Parikh said. “If you take the LTE away, you will see that most of the world is on these crappy 3G and 2G networks. When you add this to the problem of tens of thousands of different devices, made this problem really, really hard. So we have been just grinding it out. These 1 percent gains we strive for are really hard to find, but we bring together a cross-functional team –the back end team, the marketing team, the networking team – to find these gains. And for us, those 1 percent gains will impact millions of people. So this is a big deal, and we are focused on never giving up and making sure that we are chipping away at this problem and making it better.”
This leads naturally to a discussion of performance, which also shows the iterative approach that Facebook took to making video encoding faster.
Performance
Parikh asked this rhetorical question: “Who here thinks performance is important? Only half of you? The rest of you are liars, or your manager is here and you can’t say it is important. For us, it has been about incorporating performance at the beginning of the process. What we have found in years of doing this: If you save making things faster to the end after you have shipped a product, guess what? You never come back to it. There always something else after that, and by then you have made all of these decisions just to make your app beautiful and gorgeous and serve the needs of the people that you are building it for, but you never designed it with speed in mind. So clawing back and making it fast at the end is a waste of time in most cases.”
Encoding videos for different screen formats is a compute-intensive jobs, so Facebook’s engineers took a page out of the HPC playbook and parallelized it. Running encoding jobs in serial mode, it could take a server on the Facebook network anywhere from 5 minutes to 10 minutes, sometimes longer, to encode a video for the various formats that potential viewers might have on their devices. By breaking the video into chunks, encoding each chunk on a different server, and then stitching the video all back together again at the end, Facebook could get the encoding time down to under a minute. Call it a factor of 10X performance improvement to be generous with this distributed encoding approach.
The size of the files is also an issue, however, considering that a lot of Facebook users are working from 3G and 2G carrier networks, and uploading and viewing videos is going to eat into their data plans like crazy. So Facebook needed to make videos less fat. To do this, Facebook took some of the machine learning techniques that it has worked on for the past several years, with a team run by luminary Yann LeCun, and created something it calls AI Encoding.
This uses the same parallel technique as the Distributed Encoding, but instead of breaking the video down arbitrarily, it breaks them down by scene. And the neural network that Facebook has trained to analyze videos looks at the lighting, motion, color, and other parameters of the video and based on its training model it feeds recommendations into the parallel encoder that can shrink the file size of the resulting video. The gains are not huge, but Facebook has seen double digit percent decreases in file sizes, and over exabytes of capacity and heaven only knows how many exabits of data transferred over a year, this will add up to savings for Facebook and its users.


Open Compute Really Is Open For Business
Open source hardware is something that is intellectually satisfying as well as economically rewarding, but it is clearly not something for everyone. At least not yet. But the Open Compute Project ecosystem that social network and hyperscale application provider Facebook started back in April 2011 has always taken the very …
AMD Gets Inside Facebook’s Latest – And Most Powerful – Microserver
Sometimes, you do put new wine in old bottles. This is what it looks like Meta – well, really its Facebook social network group – is doing as it adds a microserver node based on a custom AMD “Milan” Epyc 7003 processor to its datacenter infrastructure. Facebook has been one …
Xeon D Refresh: The Little Hyperscale Engine That Could
The datacenter server has been the center of gravity for compute for decades. But in recent years, as relatively heavy compute – meaning more than in your PC or smartphone – has been embedded into all kinds of storage and networking devices and increasingly pushes out to the hyperdistributed computing …
Be the first to comment