

In the course of tracking commercial and research supercomputers here at The Next Platform, it has become apparent that this is the year for massive refreshes and updates to existing weather prediction systems.
In the last six months alone, there have been a number of notable new large-scale purchases in the segment and while we have described some of the market here, the consensus at the systems level is that the codes that back the forecasts we depend on tend to churn best with as many CPU cores as can be thrown a weather supercomputer’s way. And if current trends are indicative, those cores are most often packed into cabinets from supercomputer maker, Cray.
Not varying from at least part of that tradition, today marks yet another win for Cray in the weather modeling and prediction space, but this time with an interesting twist. As we have described in other pieces describing the architectural choices for major weather centers, which tends to follow the line of twin systems (one for production, one for failover and ongoing research) and straight CPUs for the scalable, ancient Fortran-based codes, this new machine will be the first to run numerical prediction models with a GPU boost.
It may seem a bit odd that in the bleeding edge niche of supercomputing, there are still areas where accelerators are rare. But for the conservative world of production forecasts, where national and regional economies are gauged and guided by a keen sense of weather, there is hesitancy to move beyond what is tried and tested on the hardware front. Further, on the software side, numerical prediction models have evolved over the course of decades and are unwieldy codes, often with a Fortran base. While they have been modernized to take advantage of multi-core architectures, the offload model of moving work between the CPU and GPU creates a challenge, even for updated weather prediction models. Interestingly, for the code in question at MeteoSwiss (the Swiss climate and weather prediction service), the entire code can run on the GPU, versus just sections as is the case with many other HPC applications.
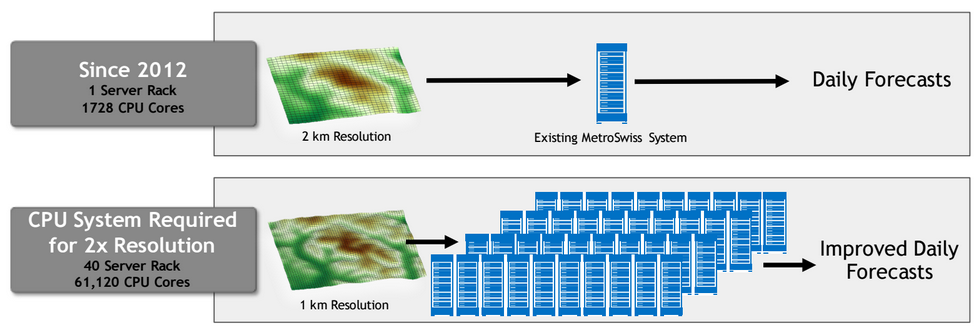
The two-year effort to retool the code has been worth it, according to the Swiss organization, which has seen a 40X performance boost and 3X power consumption reduction over its original AMD CPU-only Cray machine, which has served operational forecasts since it was installed in 2012. The new supercomputer, set to be housed at the Swiss National Supercomputing Centre, is a mere two racks, but when one considers each of the nodes sports two 12-core Haswell CPUs and a whopping eight Nvidia Tesla K80s on each node, the floating point figures add up rather quickly. The small, aptly named Cray CS-Storm cluster will be able to deliver just over 380 teraflops of double-precision performance, 359 of which come from the GPUs.
Thus far we have not seen a lot of new systems come to the fore sporting the newest K80 Tesla cards, and certainly not with eight of them on a single node. That will be a story in itself over the coming year unfolds and a sense of the combined performance and possible pitfalls become clear, but according to NVIDIA Tesla Product Manager, Roy Kim, the work on the COSMO—one of several numerical weather prediction codes used around the world—has been extensive. They can not only scale the workload to exploit that kind of capability, but keep extending it for other centers that want to adopt it or accelerate existing COSMO models with their own GPU-enabled systems.

Kim tells The Next Platform that the work they have done on this particular code can be easily shared and adopted by other centers and the teams at Nvidia, working with CUDA and OpenACC under the hood, are setting their sights on some of the other more widely-used, established numerical weather prediction codes, including WRF—the subject of some evolving work on K80 GPUs (with a 10X speedup over CPU-only execution) that could see similar adoption.
To put all of this in perspective, it is not just hardware nerdery or power consumption concerns that push a center toward accelerated HPC. For operational forecasts, there is literally no limit to how much compute power can be consumed for a forecast—with more cores comes finer resolution. This leads to more accurate, localized forecasts and for larger-scale regional forecasts, the ability to more accurately predict the climate for micro-zones inside of a given area.
As Peter Binder, Director General of MeteoSwiss noted, “To guarantee more detailed weather forecasts, the simulations will be based on a grid spacing of 1.1 kilometers, which runs recurrently every three hours. The grid spacing makes it possible to predict with more detail the precipitation distribution and risk of storms or valley wind systems in the Swiss mountains.” In addition to better resolution, the center will be able to run more frequent simulations.
On that note, as Kim told The Next Platform this week, the COSMO code is widely used in the Alps and similar regions because unlike other codes, especially those used for larger areas, COSMO performs well for mountainous climates where the weather considerations are different. He says that in this sense, it is one of the more challenging codes and now, with the addition of acceleration capabilities, its opportunity to grow (along with Nvidia’s in this space) greatly increases.
The Swiss National Supercomputing Centre is already home to another GPU equipped system, the #7 fastest machine in the world, called Piz Daint. The new weather prediction racks will be housed at the same center and will be in full production in 2016. While not a contender for a noticeable ranking in the Top 500 upper ranks, it is one of a few systems utilizing the newest K80s—and with so many of them on a single node.


JAMSTEC Goes Hybrid On Many Vectors With Earth Simulator 4 Supercomputer
Sponsored When it comes to compute engines and network interconnects for supercomputers, there are lots of different choices available, but ultimately the nature of the applications — and how they evolve over time — will drive the technology choices that organizations make. And such is the case with the new …

US Air Force Spends $100 Million To Accelerate Data Warehouses
We talk about big money being spent on GPU-accelerated HPC and AI systems all the time here at The Next Platform, and we have been clear that we think another area where such acceleration will take off is with databases and related analytics, and particularly with data warehouses that have …

Groq Says It Can Deploy 1 Million AI Inference Chips In Two Years
If you are looking for an alternative to Nvidia GPUs for AI inference – and who isn’t these days with generative AI being the hottest thing since a volcanic eruption – then you might want to give Groq a call. It is ramping up production on its Language Processing Units, …
I am curious why a 40x increase in compute performance only allows the grid spacing to reduce by 2x. The volume of the grid elements goes down 8x, so one might expect 8x more compute time rather than 40x.
Is it because the time steps must be made smaller as well to maintain accuracy, or are there other reasons?