

The Hadoop framework was created to deliver a balance between performance and data management efficiencies and while this is a good part of the reason it has taken off in recent years, there are still some areas of The Next Platform that are out of balance at the storage layer. At the same time, the demands on Hadoop to run jobs at top speed and energy efficiency are increasing as well—the only thing that has not changed is the ability for users to expand beyond concrete storage options.
Since not all storage media is created equal and must be balanced (for instance, hard disks are valuable for their low cost per gigabyte and high capacity while solid state drives offer excellent performance and energy efficiency, but are more expensive), it stands to reason the ability to tune and rebalance for several storage approaches should be part of Hadoop. However, while platform supports the use of SSDs generally, at the storage layer, it treats all storage devices equally or, more accurately, it is not balanced for the advantages of hard disk drives over SSDs.
If the native Hadoop storage layer that revolves around the Hadoop Distributed File System (HDFS) allows the simultaneous use of the best of both the hard disk and SSD worlds, it stands to reason that if the performance would see a boost, the energy consumption would go down if the right data elements were handled by the best fit storage device, whether that is higher performance and efficiency SSDs that are expensive, but beat the slower but more economically efficient advantages of disk.
Along these lines, a team of researchers in Brazil have developed the ability for this balance between storage performance and price tradeoffs with HDFSh, which is essentially an approach to block placement policies or “storage zones” within HDFS that are capable of reducing energy consumption and boost performance by assigning the right part of the storage workflow to the most appropriate device via hard-set policies that can be tuned for each specific workload. The goal is to allow configurability to the point that users decide how much of either storage approach is used during the map and reduce phase in particular. As one might imagine, at its core, it involves only storing certain elements on the high performance but expensive SSDs while managing a great deal of the rest of the workflow that is not in flight on slower, but cheaper hard disks.
“HDFS lacks differentiation of the different storage devices attached to a Hadoop cluster node; consequently, it cannot properly exploit the features provided by such devices to customize and incease job performance or decrease a cluster’s energy consumption.”
The team tested the performance across the last six releases of Hadoop across a nine-node commodity cluster, including AMD quad-core processors, 8 GB RAM, then a 1 TB hard drive and 120 GB SSD from Intel. As an interesting side note, the team found several big differences in both I/O and energy efficiency benchmarks depending on which Hadoop version was used. For instance, when the YARN resource manager was added into the releases, the energy consumption worsened quite significantly. Given these differences, they have gone into detail about the different results on benchmarks broken down by Hadoop release (as seen below—the name of the release runs across the bottom).
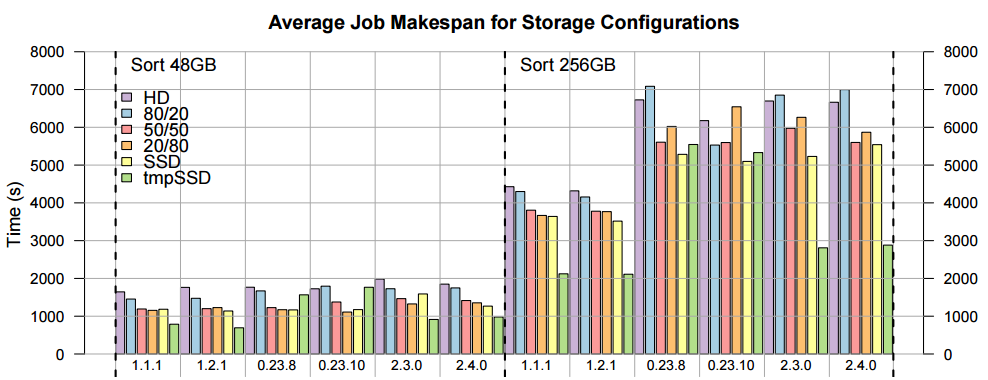
According to the researchers, when it comes to Hadoop branches and “their significant performance and energy consumption differences, it is clear that YARN brought flexibility to the framework, but generated a significant performance loss.” They note that since most of the energy pull is tied to job makespan, the versions .23x and 2.0x releases nearly double the energy consumption companied to jobs that were running on 1x releases. While this was not the focus of the HDFSh project, it is a noteworthy finding as perhaps the same efforts that have gone into tuning HDFS could be extended to improving the efficiencies of YARN—a necessary but apparently dragging element in a platform that has been refined to a great extent over the years.
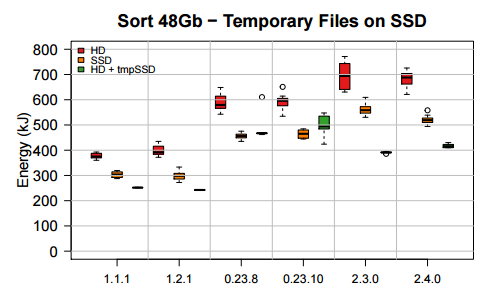 Despite some of these side findings about performance and efficiency, the team was able to show up to a 20% improvement in both areas, in particular by using the SSDs as temporary storage for the map and reduce phase of the computation.
Despite some of these side findings about performance and efficiency, the team was able to show up to a 20% improvement in both areas, in particular by using the SSDs as temporary storage for the map and reduce phase of the computation.
This element of the approach, called SSDzone, also showed there are still version differences in this assessment when run across a 10 GB dataset. Interestingly, the 1x branch of releases performance better as the data sizes increased—which means that not only did performance et a boost, but the energy savings skyrocketed in relative fashion when the SSDs became the sole home for temporary space.
The full host of benchmarks tied with the version number can all be found in the paper, along with some granular associations between cost per gigabyte and how the overall TCO of this approach might map out.
As a side note, to be fair, the idea of marrying the advantages of SSDs and hard disks is not new—and there have been some notable efforts to make this more seamless via examples like SSHD (solid state hybrid drives), which essentially bundles both devices in one package, where the “hot” data is held and managed within the SSD. However, for users that have existing Hadoop clusters that might have some of both storage media available, this could provide a quicker way to play with performance and efficiency tuning without buying new hardware.

The Opposite Of Snowflake: Analytics Without The Data Warehouse
As we have pointed out before, large enterprises have to deal with a different kind of scale issue than the hyperscalers, and in many ways, the hyperscalers have it easier. The hyperscalers have dozens of core applications that they have to run at massive data scale – pushing up to …

Getting Hadoop to Jump Through AI/ML Hoops
Just a decade ago, the enterprise IT push was to make Hadoop the platform for storage and analytics. At that time, cloud hesitancy was still looming for large on-prem organizations. Hadoop, no matter how that ecosystem played out over the years, became a major source of investment with the idea …
Automagically Moving Legacy Hadoop To The Cloud
Always on the lookout for the kernel of a new platform, we chronicled the steady rise and sharp fall of Hadoop as the go-to open source analytics platform. In fact, we watched it morph into a relational database of sorts only to end up being cheap storage for unstructured data. …
Be the first to comment