
When Hewlett-Packard launched its moonshot effort to create a new computing architecture centered on non-volatile memory last year, called The Machine, many people jumped to a number of wrong conclusions. The first was that The Machine would only be applicable to data analytics workloads, and that is not true. The second was that The Machine would be based on memristors and therefore its success or failure would be tied to the commercialization of this non-volatile memory, which HP and others have been working on for decades. Also not true.
As it turns out, HP most definitely has plans to work with customers to adapt and deploy massively parallel simulation and modeling workloads typically run on supercomputer clusters on the machine. And in fact, Paolo Faraboschi, an HP Fellow working on The Machine in HP Labs’ Systems Research area, put out a call to potential HPC shops at the recent ISC 2015 supercomputer conference to work with HP on porting their codes to prototype machines that it is building next year based on DRAM memory.
Eventually, The Machine will move to a mix of DRAM and some form of non-volatile memory when it moves from prototype to production, with DRAM being close to a system on chip (SoC) compute complex and a massive pool of non-volatile memory being shared across thousands of these SoCs using an optical interconnect that makes all of this memory look more or less local to those SoCs.
While HP no doubt wants its own memristor memory technology to be used as the so-called “universal memory” in the system, a kind of hybrid between memory and storage as we know it in systems today, it cannot wait for that. And while HP chief technology officer Martin Fink has called out phase change memory as a possible replacement for memristor memory until HP gets it sown memristors ramped up, there is another option: The 3D XPoint memory that Intel and Micron Technology unveiled three weeks ago has some of the same properties of memristors and PCM, in that they all have persistent memory (unlike DRAM, which has to be powered up to keep its data) and that they offer higher and cheaper capacity than DRAM even if they are a bit slower. As we have learned throughout this Future Systems series, most of the people talking about future system design expect NAND flash and maybe PCM memory to play a big part of the storage hierarchy over the coming years, along with DRAM in various form factors and proximities to the processor. HP would like to have a machine that just uses memristor technology, top to bottom. And it may even get there.
“If you are coming from the scale out world, it is reasonable to think of universal storage as regular storage that is 10X to 100X faster. If you come from the scale up world, you can think of this as a little bit slower memory, but much larger than what you are used to.”
The point is, and one that HP made clear last year, it is putting memory at the heart of the design of The Machine, not compute, and making it suitable for a wide range of data-intensive applications, both in terms of the amount of data and the bandwidth needed. But, as Faraboschi explained to the ISC crowd, there is more to it than just slapping together a big pool of memory to make The Machine, and some extra things will need to be done to make it suitable for HPC work.
“The Machine is not being designed for HPC, per se, but for large data analytics, graph analytics, and similar workloads, which happens to be converging to HPC to a certain extent,” Faraboschi said, adding that ultimately, the way The Machine will be architected might not be that different from where HPC systems are already evolving to.
Remember: This Is About Memory
“We see that memory is the most important thing going forward,” said Faraboschi. “Capacity is not scaling. Cores are doubling every couple of years even with all of the constraints due to the end of Denard scaling, but memory is doubling every three years if we are lucky.”
This is a curve that cannot hold, obviously. We could hold back Moore’s Law on processors, but that seems unlikely because it does not make much business sense for the chip makers or their system customers, who rely on upgrades every year to keep the money flowing in.
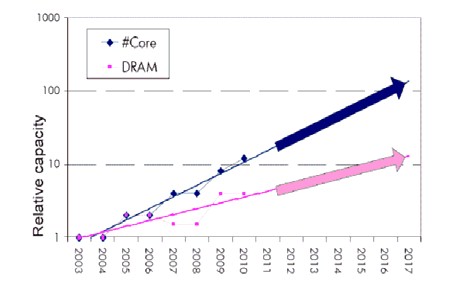
There are limitations with DDR that are related to the bandwidth on the edge of the chip, said Faraboschi, but there are even more issues to be considered when designing a completely new system architecture.
“The way we are talking to memory today is very inefficient and parallel, and while it works really well for high bandwidth memory, when you want to scale capacity, it doesn’t work. The economics of the memory business has dramatically changed in the last twenty years. Some of you are old enough to remember back in the 1980s when we had over twenty memory vendors; five years ago we had six and today we are down to three. That changes, quite a bit, where the investment pools in the memory business, and today they are all moving to embedded memory. Last year was the first time when we saw the bits in tablets and other mobile devices actually was higher than the bits that went into HPC, PCs, servers, and workstations. You can imagine which way the investments are going to go, and we are going to see big changes in the way we are going to connect memory. I am going to propose our view of how that is going to work. But don’t expect that the way you get memory into your system is going to continue forever.”
This is why HP has been focusing on memristors, and it is also why the company is willing to embrace other non-volatile memories in the short-term to get The Machine off the ground.
The big problem that HP is trying to solve with The Machine is that DRAM main memory is the only part of the system that is “held captive” by the processor, the only element that has not been disaggregated. (We would argue that putting PCI-Express controllers and Ethernet controllers onto the die is perhaps not as useful in the disaggregated and hyperconverged system world that seems to be emerging.) Companies don’t want islands of volatile DRAM where they have to move data around all the time, and they do want to be able to scale compute, memory, I/O, networking, and storage all independently of each other, and swap them out on different upgrade schedules that are tuned to their own technology changes – if DRAM upgrades happen less frequently than CPU upgrades, so be it. Design a machine that can accommodate that. The hyperconvergence part means bringing all of the exploded pieces back into a rack and allowing customers to think at the scale of one or multiple racks, not nodes.

“If you look at the trajectory of this rack-scale computing, in a couple of years we are – if you look at our current Moonshot machines, you can pack 20,000 cores into a rack with a significant amount of storage and memory And if you look at the projects for a couple of years, you will be able to have 100,000 cores – a combination of general purpose and acceleration cores – inside of a rack. This rack is going to become the unit that people will use as the building block for an exascale computer rather than an individual server because when you are thinking at the rack scale there is a lot more optimization that you can do than within an individual server. The problem remains that memory is the last resource that is not dynamically reprovisioned.”
With universal memory as HP is conceiving it, The Machine is talking some bits of scale up system design and mixing it with scale out design.

The Machine has what HP is for the moment calling a “shared something” architecture, and like modern cluster architectures for data analytics, data would be replicated around the nodes The Machine. The optical interconnect HP is creating could possibly be used to lash SoCs together into a vast shared memory machine, but that is not the point. Such a NUMA beast would be wildly inefficient and would spend all of its time thrashing, moving data around for nodes that would never get any work done because they would be waiting all the time. Instead, the machine has each SoC run its own operating system – in this case, a variant of Linux – and it has been tweaked to work with this universal memory and, importantly, has had a lot of its guts removed that are no longer necessary because the architecture is cleaner than a modern NUMA server.
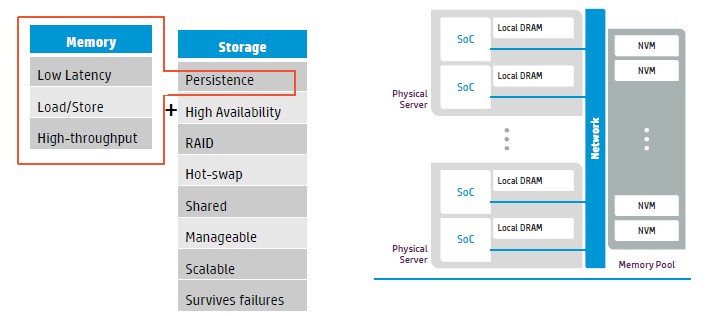
The funny bit is that Faraboschi said that persistence of data in this universal memory pool and sharing across nodes is not just about breaking down the islands of memory in modern systems. “The reason you want persistence is not because you want to store you data and pick it up a year later – this is not about capacity – but you want to be able to tolerate faults,” he explained. “There are several technologies on the roadmap today that will be able to tolerate node rebooting or hardware failure so you can restart your computation.”
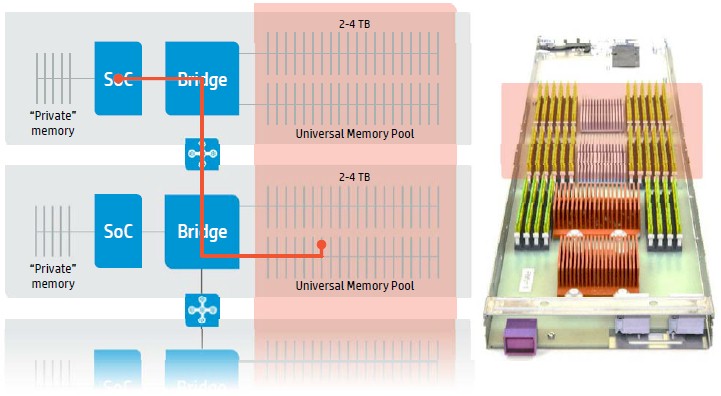
Next year, with the first prototype of The Machine, HP will be using DRAM technology for the memory on the SoC and as the universal memory layer. This DRAM in the universal memory layer will be on a separate power domain from the CPUs on the SoCs, so a power outage on the CPU (for example, during a reboot) will not cause memory loss. When a non-volatile memory layer is added in, this is when we can expect HP to start delivering its own Linux variant. This prototype will be based on the Apollo system enclosures, and the compute and memory are physically distributed but logically pooled. The SoC is in the front of the mock up shown above, which has its own private memory; eventually this will be stacked high bandwidth memory, but for now it is just DRAM. But the architecture is not the same as a normal SoC. “The difference is that we have freed memory from the CPU, and now one CPU can issue a memory operation that traverses the bridge chip and the fabric, including optical interconnects, and can hit memory that sits in another part of the physical infrastructure but belongs to the same logical pool,” explains Faraboschi.
“If you are coming from the scale out world, it is reasonable to think of universal storage as regular storage that is 10X to 100X faster. If you come from the scale up world, you can think of this as a little bit slower memory, but much larger than what you are used to.”
This is exactly how other alternatives, including the new Memory1 flash-based and bit addressable DIMMs from Diablo Technologies, are being described, generally speaking. And as we pointed out, this is how the 3D XPoint memory – which could be a variant of phase-change memory – is also being characterized.
The thing to remember is that universal memory is not just memory, but storage, and that means you can do things like replicate data for high availability, use RAID data protection on chunks of it, do hot swapping of components, and so forth. There is no reason why it cannot run the Hadoop Distributed File System, Lustre, or GPFS, by the way.
Because The Machine is not a scale up box, a memory error in a chunk of this universal memory does not bring the whole machine down. The architecture is more like a shared-nothing cluster in that if a node fails, the cluster heals around it. In the case of The Machine, a node will just point to a replica dataset and continue processing. The code for doing this is not yet done, of course, and this is where modifications to the Linux kernel are necessary. And Faraboschi is pulling no punches about why he thinks Linux needs to evolve.
“One is the Linux community – and please forgive me if you are hardcore Linux – but Linux is usually targeted at the lowest common denominator,” he said. “Anything that doesn’t fit that model has been really, really hard to get in. And I am talking about things like multicore, 64 bits, and you name it. It went there, but it took a long time. We might to evolve at a faster pace than Linux evolves. The second reason is that when you look at the data-centric world, things are different. I will give you an example of protection. We have this big bubble of memory, and we don’t want to trust the individual operating system to access that memory, I don’t want a malicious bug in an OS or even a bug that a programmer did to go around and trash 300 TB of memory. That would be kind of awkward. We want protection to move to the memory side and we want the location to move memory side, and we want the memory to include a resource handler that is trusted at the higher level entity. This notion just does not exist in Linux. We can morph Linux by doing some magic with the page table location, and we are doing that next year.”
Am architectural hint: The Machine will have a memory broker that controls all of the memory, and each individual compute node will have to ask permission to exchange some keys and get access to a big chunk of memory – 1 TB, 10 TB, whatever – that will be mapped into the local node memory space, and then the node will parcel it out into smaller chunks.
What About An HPC Machine?
As Faraboschi joked, most of the attendees in the audience at ISC were probably thinking that they had 10 million lines of Message Passing Interface (MPI) code, it doesn’t use shared memory, only private memories on isolated nodes. Why should HPC centers care about The Machine like certain kinds of analytics workloads (graph analytics with for social networks is a great example) should? Well, for one thing, and we all know this, floating point performance is not as important as memory capacity and memory bandwidth, which is the real bottleneck in future systems. And we heard this again and again at ISC and even earlier this year when IBM told us about how memory bandwidth and integer performance were becoming more important to exascale systems than floating point.
The biggest reason why The Machine might appeal to HPC users is that this persistent storage will have very high bandwidth. “The one thing that nobody wants to talk about, and that is the unloved child of HPC, is defensive I/O,” said Faraboschi, referring to the checkpointing at intervals during the simulation and the restarting of calculations once this checkpointing is done. “As we move to larger and larger systems, our meantime to interrupt (MTTI) is going to go down to numbers that are incompatible with the rates that we can do checkpointing. In supercomputers today, the file systems goes into 1 TB/sec just to be able to do a dump in a time that would not completely overwhelm the computation.” It will need to rise to tens of terabytes per second with larger machines, he said – something that The Machine, with the right configuration, could handle.
While Faraboschi did not say this explicitly, the architecture of that optical interconnect that creates the universal pool of memory and that gives access to it to SoCs hanging off it, will lend itself to MPI operations and similar global array functions used in certain HPC codes. (Much as a theoretical exascale system proposed by Intel researchers based on a massively scaled out architecture with hierarchical storage and simple compute nodes does.) This is technical, but Faraboschi explains it well:
“Even if you are using MPI, at least logically you have the notion of very large shared data. Many applications use a global array abstraction (quantum mechanics simulations is one example) that end up replicating hundreds of gigabytes of data in all of the nodes. If you had universal memory, it could be in one place, accessible to all nodes, and you could replicate it for performance. For reverse time migration and other types of seismic analysis, you are also forced to do data domain decomposition because you have to make sure you bring the data close to the CPU when you want to process it. If you have very large universal memory, you can possibly store your propagation and accumulation data in one place and bring in all the other data you care about.
Moreover, MPI could be tweaked so that collective operations (which account for up to 80 percent of communication on the MPI protocol, could be done as in-memory shuffles on that universal memory. “Collectives are kind of a pain for everybody, even moreso when you are doing certain kinds of algorithms like all-gather, which unfortunately is fairly common in matrix multiplication and sparse matrices. Now if you have universal memory, you can think of doing in-memory shuffles. Rather than having to do complicated things like recursive doubling, you can imagine everybody posting their data in universal memory location and everyone else pulling it out wherever it is needed.”
Similarly, one-sided communication, a feature of MPI running over networks and servers equipped with Remote Direct Memory Access (RDMA), can be tweaked on The Machine’s universal memory such that you don’t actually have to move any data, but rather just change pointers in the universal memory. You might want to move data closer to a particular compute node for performance reasons, but you won’t have to.
There are a lot of details to be worked out, and HP is looking for supercomputer centers that want to play with The Machine’s architecture on prototypes based on DRAM so when the real machine comes along, with vastly more memory and node expansion, both the company and prospective users will have some idea how HPC codes might do on such an architecture.


A Surprising New Job for ReRAM Technology
Resistive RAM (ReRAM) technology has been waiting for its moment in the sun for several years now. Despite its placement on the roadmaps of several chip manufacturers and as part of novel architectures like HPE’s shuttered memristor-based “The Machine” project, it never took off as a revolutionary memory technology, even …
Inside HPE’s Gen-Z Switch Fabric
Even before it launched a $1.3 billion acquisition of Cray back in May, Hewlett Packard Enterprise has had exascale aspirations. Its memory-centric concept platform, called The Machine, was a possible contender as starting point for an architecture for an exascale system, and its offshoots based on HPE’s substantial work with …

Quantum Has Its Role, But In-Memory Is the Way To Go
A lot of money and time is being thrown at quantum computing by vendors, including IBM, Google, Microsoft, and Intel, and there is the normal competitiveness between the United States and China and Europe as well as work in Japan. We are at the early stages of quantum computer development. …
Do the SOCs on the machine have to be based on just a modified Harvard architecture, or can they be based on a stack architecture. I’m referring to the Burroughs stack architecture of days past where everything ran in a stack, data in the data stack code in the code stack, and built into and intrinsic to the design of the stack architecture based CPUs where hardware registers that specifically pointed to the top, and the bottom of these respective stacks, and the Burroughs CPU had plenty of these hardware pointers/registers . Any addressing out of the bounds of these CPU pointers, top or bottom resulted in a hardware interrupt and the MCP promptly flagging and flushing the offending code. All this continuous need to provide the necessary security protection by purely software means has been unsuccessful as these security problems(overflow vulnerabilities, etc.) appear to be endemic on the modified Harvard architecture based processors that dominate the current market. I’d love to see if anyone has taken the time to research the old stack architectures on a FPGA and maybe have done some vulnerabilities stress testing using Burroughs extended ALGOL, or some newer objected oriented languages and compared the results of the stack architectures versus the modified Harvard architecture. If any architecture lent itself to running object oriented code securely it was the stack architecture.
HP has a serious credibility problem. Lot’s of talk, no product. I don’t want to hear anything more about that company until they are actually shipping something of interest.