

Lining up the architectures of future supercomputers is interesting because it gives us a glimpse of what may be in the corporate datacenter many more years out. Server node design and the integration of various memory and interconnect technologies into clusters for running modeling and simulation applications were the hot topics at the recent ISC 2015 supercomputing conference.
Nvidia chief technology officer Steve Oberlin explained why supercomputing architectures are under pressure and the ways that various vendors – specifically, Intel with the “Aurora” supercomputer at Argonne National Laboratory and the OpenPower partnership comprised of IBM, Nvidia, and Mellanox Technology with the “Summit” system going into Oak Ridge National Laboratory – are building nodes and systems to try to get around power consumption and thermal limits that are affecting all large systems.
It must be a tremendous amount of fun to be a system architect or CTO, you might assume, but after you think about it for a minute, perhaps not. The challenges are daunting, and the stakes are high if you believe in the value of supercomputing to better the world and, if you don’t want to go so far, for the continued employment of untold numbers of techies who design, build, and program such machines to solve the toughest problems we can come up with.
“You can sketch anything if you don’t have laws of nature,” Oberlin observed wryly in his presentation comparing and contrasting latency optimized cores (what we think of as general purpose CPUs) and throughput optimized cores (massively parallel machines like the GPUs created by Nvidia that have been transformed into compute engines). “In our case, I think it is an interesting time for architecture because, for exascale especially, unlike the prior millennial crossings we made into megaflops, and gigaflops, and petaflops, now we are trying to do it with a little less help from Moore’s Law.”
Oberlin said that there was a tension between system architects that believe strongly in one or the other aesthetic, and added that there was another experiment in process “that is pretty interesting,” referring to the big Summit and Aurora machines being built by the US Department of Energy and expected, respectively, in 2017 and 2018. As we have pointed out in our recent coverage of the Top 500 supercomputer rankings, the performance of the top machines has stalled but Summit and Aurora are expected to get the list back on its logarithmic track, more or less. The list flattens out every now and then as governments build up budgets and await technology transitions that will allow them to get a big jump in supercomputing capacity.
But as Oberlin pointed out, this is becoming more challenging as adding transistors to a die is coming at a cost. Moore’s Law advances are not over, it is just that cramming more transistors on a die every 24 months since 1975 – now more like 30 months, according to Intel – is not as helpful as it once was.
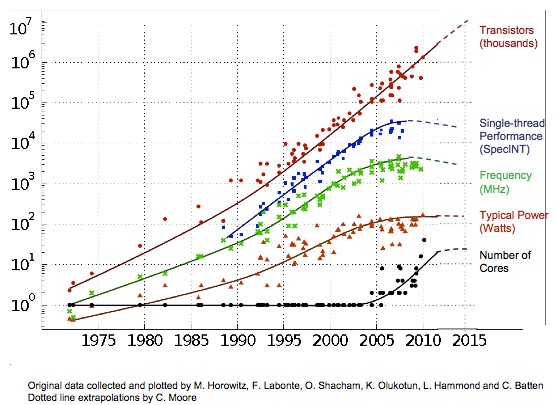
“This slide is not new, but it documents the inflection,” Oberlin said. “You can see that transistors over time continues to grow and that Moore’s Law is not dead. It is continuing to double the number of devices. But for various reasons we are losing the ability to make good use of those.”
In the early 2000s, the industry could no longer boost the clock speed of CPUs to boost performance, so were started going parallel – to the chagrin and dismay of programmers. This move was, in part, caused by capping power in the processors and that had a knock-on effect on CPU frequencies and therefore the single-threaded performance of these processors.
One of the causes of the problem, which is a chart that comes from Intel co-founder Gordon Moore himself, is the leakage of power in the circuits:
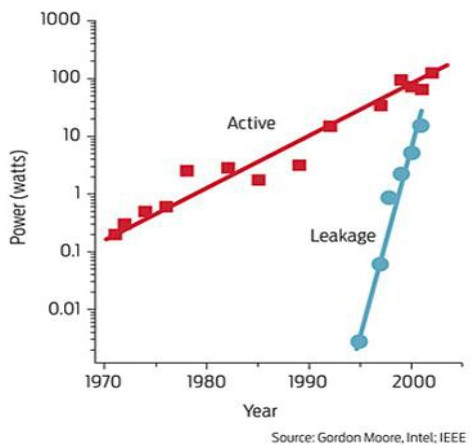
In the chart above, active power over time, shown in red, is a measure of how many watts a processor devotes to switching power. As transistors shrank, leakage started to consume more and more of that power.
“Leakage is really what is making it difficult for us to use all of the transistors that we are still getting courtesy of Moore’s Law,” explained Oberlin. “We used to have a really sweet deal, and every generation we would cut length of the device in half and we would get four times the transistors, and if you look at frequency, smaller devices clock faster and we would get approximately eight times the capability – and all at about the same power, which was really nice. So why would be bother with computer architecture?”
The New Reality And The Need For Architecture
The reality now is that as we cut the feature size in half, we still get four times the transistors, and potentially eight times the capability because they can still be clocked faster. But the power is going up because of leakage. “You can play around with the equation and turn the dials, and decide you want two times the capability at the same power for a quarter of the area and have a cheaper product. But this is one of the factors where fundamental physics is driving us into this corner with silicon.”
Oberlin said that we do have options, and he flashed up a chart showing three different transistor types with increasing length of their gates. By making gates on the transistors longer, you can have a lot less leakage – about a factor of 100X – while doubling or tripling the delay in switching. This seems like a fair tradeoff, but it does mean having bigger devices with more transistors so you can boost the overall throughput of the device. It is unclear when and if the chip industry will embrace such techniques.
In the meantime, what Nvidia has come to believe, along with its partner in supercomputing, IBM, is that hybrid computing is the answer. (Intel, by contrast, is turning its Xeon Phi massively parallel coprocessors into full-on processors, complete with fabrics on the die, and building clusters of them.)
“At Nvidia, we are believers in role specialization of devices within a node,” said Oberlin. “We believe this is a way for optimizing for the efficiency of a node. I wasn’t at Nvidia at the time, but the model of having a GPU as a coprocessor undoubtedly was not something that was arrived at with efficiency in mind. It was probably a market abstraction, if you will, something necessary for the business model for Nvidia to operate independently. But it has actually turned out to be something that has quite a lot of value.”
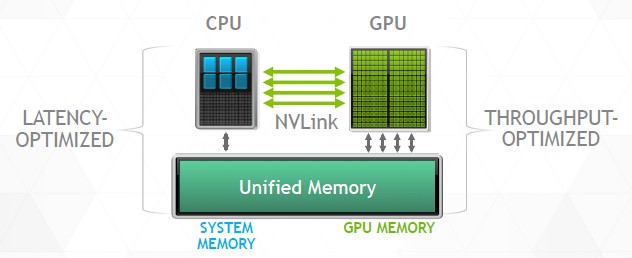
“If you look at CPUs and how they are built, and what they are optimized for, their entire pipeline – through all of the functional units from issue to lookahead to register renaming to speculative execution – all of these things are designed to accelerate a single thread to completion as short of a time as possible. The entire memory hierarchy, in fact, is organized for minimal latency, deterministic behavior. With GPUs, the throughput optimized side, not so much. Their lineage is parallel processing – billions of pixels per second to color and billions of polygons per second to shade, rotate, and so forth. That kind of thing can be done in bulk by simple coordinated processors acting on massive scale with many, many operations in flight at once. We don’t really care about latency so long as things get done in the allotted time of for a timestep, which is a frame refresh. What is much more important is bandwidth, and so the entire pipeline is designed to deliver the maximum amount of bandwidth. Pairing these things together is a great idea, since we can get the best of both worlds. Unless you are a programmer.”
Programmers, of course, have to root through their code and find the latency sensitive bits and run them on the CPU and dispatch the parallel bits to the GPU. We are taking steps to unify the memories of the CPU and GPU to make data movement unnecessary and therefore the programming easier. NVLink is being introduced to make the pipe into the GPU and between the CPUs and the GPUs fatter to enable coherence between these devices and reduce the time it takes to move data around this hybrid processing and memory complex.
There was a temptation to literally unite the CPU and GPU, which Nvidia was planning to do through an effort called Project Denver, and which AMD is very keen on with its future HPC-oriented “Zen” hybrid processor. Oberlin did not think this was necessarily a good idea.
“People at Nvidia, before I got there but not that long before, were actually talking quite a lot about integrating the CPU latency optimized cores and the GPU throughput optimized cores on the same device, and how important that was,” he explained. “Actually, it turns out that, as with all things, there is a lot of shades of gray to that question. There are a lot of reasons why physical integration maybe is not such a good thing, and there are advantages to not having them be physically integrated. You have flexibility and you can turn the dials on both sides of the equation. You can pick your instruction set architecture for the CPU, you can decide how many LOCs you want to have compared to TOCs, and optimize the memory subsystems for their roles. And you can also keep them from interfering with each other. GPUs have coherent streams of data flowing through them, and having random CPU references injected is only going to create bubbles and CPUs are not would not be very happy in a TOC optimized memory system. With all of this there is a lot of tradeoffs and some of them are for performance, some of them are for market forces, and so on. The bottom line is that if you can create something like NVLink and this abstraction that allows you to lower the programming burdens enough, then physical integration probably doesn’t matter much.”
The NVLink interconnect, which will debut next year with the “Pascal” GP100 Tesla GPU coprocessors and which will also be added to IBM’s Power8+ processors, will allow very high speed links running at 20 GB/sec (with up to four links between any two devices for a total of 80 GB/sec in either direction between the devices). Each link will provide an effective bandwidth of around 16 GB/sec, which is better than the 16 GB/sec of peak throughput and 12 GB/sec of effective bandwidth from a PCI-Express 3.0 peripheral slot. The first iteration of NVLink will allow two, three, or four GPUs to be lashed together and then for the CPU to be linked via PCI-Express through PCI-Express switches, turning those GPUs into something that will look, more or less, like a giant single GPU. Mellanox InfiniBand cards will be able to tightly couple with Power8+ chips through the Coherent Accelerator Processor Interface (CAPI), which could have also been used to provide virtual memory addressing between the Tesla GPU accelerators and the Power chips.
Further down the road in 2017, IBM will roll out its Power9 processor with enhanced CAPI (which seems to mean CAPI running over PCI-Express 4.0 buses). Perhaps Nvidia will also add CAPI endpoints to the “Volta” GV100 Tesla accelerators due in 2017 and that are, like the Power9 processors, going to be the compute elements in the Summit supercomputer. (This would be handy, allowing for the Enhanced NVLink to be reserved for GPU-to-GPU communication.)
During the node architecture sessions, Oberlin spoke for the OpenPower partners, and for fun he compared and contrasted the Summit and Aurora machines. Like the rest of us, he had to guess about some of the configuration details because the companies making these future machines are being intentionally vague about some of the system details.
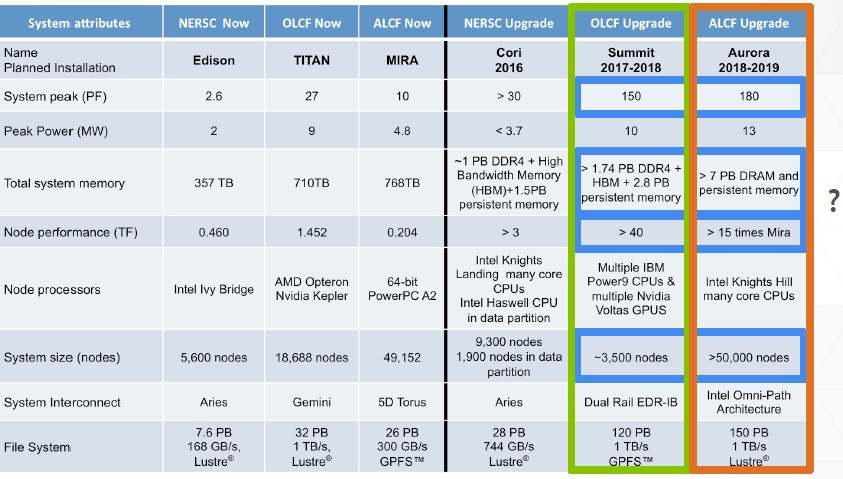
The first thing to note, said Oberlin, is that the peak performance of the two machines are approximately the same, but the number of nodes – and the performance per node – is dramatically different.
“There is obviously much finer granularity on the Aurora system,” Oberlin said, and then he got into an esoteric comparison. “One of the things that people talk about with node granularity is surface-to-volume advantages that can happen. If you think about distributing your parallel job across many nodes in a distributed computing system, oftentimes the communication devolves to some formula that is communicating on the surfaces, if you will, of the volume of data that you are computing on. Because volume scales differently than area, then the larger you make the node, the smaller the ratio of your communication needs to be relative to the size of the node.”
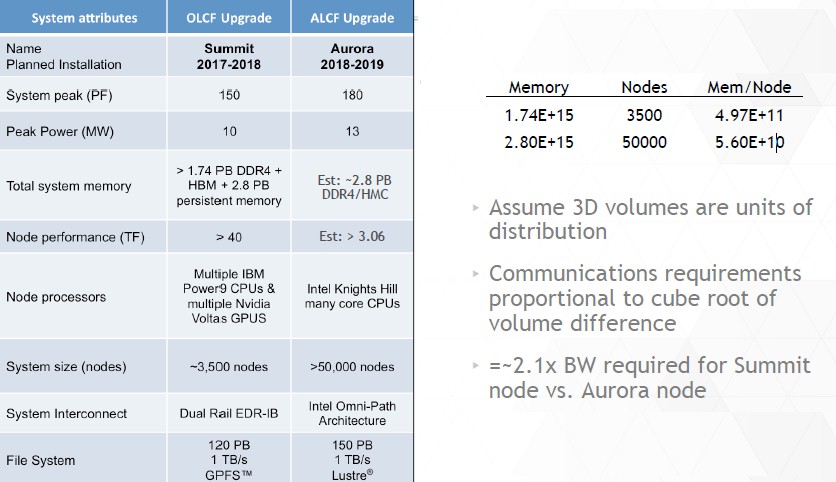
The thing you want to know as a supercomputer architect, he explained, was how much memory was in the node and how fast your compute engines will be able to rip through it. This will give you an idea of how frequently you will be communicating across nodes.
“It is kind of interesting, if you divide out the ratios of the node volumes and the node performance, they are both going to rip through that memory, or that amount of work assuming that they are touching all of the data, in approximately the same amount of time. So the compute versus communicate ratio should turn out to be approximately the same. And if you believe the surface-to-volume thing – assume a 3D volume, but it doesn’t have to be, it can be a multidimensional construct – then communications in 3D is going to be proportional to the cube root of the volume difference. It says that the Summit node should need approximately two times the absolute bandwidth per node of an Aurora node. I can’t tell if that is really the case, because we only have an architecture statement.”
Even the experts are sometimes found scratching their heads a little bit until the machines are built and tested. (And maybe a bit after that, too.) The interesting bit is that the Department of Energy will be putting two different architectures to the test, and moreover, as it looks like the IBM-Nvidia partnership will be building beefier nodes as time goes by, Intel might be looking to shift to Xeon Phi processors with fewer cores, a lot more high bandwidth memory, and very fast integrated fabrics. If that is the case, as Al Gara, Intel chief exascale architect, hinted was a possible future for Intel processors, that would explain in part why the Aurora machine based on the “Knights Hill” Xeon Phi will have more than 50,000 nodes. Each Knights Hill node could have a lot more memory bandwidth and interconnect bandwidth, but a lot fewer cores on its single chip. The issue to solve is memory bandwidth, not just pumping up the core count, after all.




Well I am not sure if I buy into that. nVidia is saying that as obviously their Denver endeavour was a complete failure and was way way behind in terms of timeframe. So they are now trying to spin alternatives to stay in the compute game. But looking at the numbers NVLink speed is a far cry of the speed of Intel’s Omnipath technology.
Don’t see any real future for Power architecture either they just don’t have the volume to recoup the massive amount of R&D required. Giving up their manufacturing to GF is also a large gamble on their site.
I think nVidia will find itself on the wrong side of the fence sooner or later.
If Intel does break up Knights Hill, eliminates the DDR4 from it altogether, and only uses HMC, it sounds like Knights Hill will be heading in the same direction that SPARC XIfx did in 2014. Thats probably the correct move for a useful exascale system, but it will make it more expensive to have large memory capacity.
It will be very interesting to see aggregate memory and interconnect bandwidth in Knights Landing compared to Knights Hill systems and those compared to SPARC, SX vector and Nvidia CPU GPU systems.
The large nodes needing less node to node communication is something that crossed my mind reading about how few nodes that system had a while ago.
One thing i wonder about that though, is given the nature of some exascale problems, you might still need a lot of node to node bandwidth even with large powerful nodes.
An exascale feasability study i read concluded that many exascale workloads will need several Bytes/FLOP and up to hundreds of PB of memory.
I wonder which evolution of these architectures will be able to efficiently scale to that size. Plenty of the higher Top500 machines are only around 60% computationally efficient now, and that has to change dramatically to keep it under 20MW.
I thought Knight’s Hill was HBM, not MCDRAM, and certainly not HMC.
Knights Landing uses a special version of HMC which Intel calls MCDRAM for some reason. I was under the impression that it used Intel’s EMIB to connect it to the KNL CPU. Im not positive on the EMIB part.
HBM implementations ive seen use interposers which Intel(and Altera) seem to want to avoid in favor of Intel’s proprietary EMIB for their SiPs.
I was also under the impression that Knights Hill would use custom on package HMC of some kind, since Intel and Micron worked to develop that and the XPoint memory(which i think is the mystery memory for Purley Xeons).
I could be wrong though :p