

There is little doubt that the worlds of large-scale data analytics and high performance computing share common features, but when it comes to meshing these two disparate technology (and to a large degree, cultural) divides, there are clear challenges. From an architectural perspective, to programming paradigms, to the tools that are standardized upon, big data and HPC have to travel quite a ways to meet in the middle.
The key to bridging the gap, according to Raj Hazra, vice president of the architecture group within Intel and general manager of the company’s technical computing division is found in increased convergence, integration and configurability up and down the stack—a goal that is tied to Intel’s view of a single system architecture, which Hazra outlined at the International Supercomputing Conference in Frankfurt, Germany last week.
It is a lofty notion–one that requires far more than just merging technologically disparate areas, but if successful, could carve out the hardware and software stacks to allow more room to build laterally for configurability, allowing both HPC and data analytics to share the same infrastructure as seamlessly as possible inside an ecosystem in place that supports both simultaneously. The critical missing piece is the middleware–the resource management layer that ties both toolsets, programming environments, and application-oriented hardware needs together.
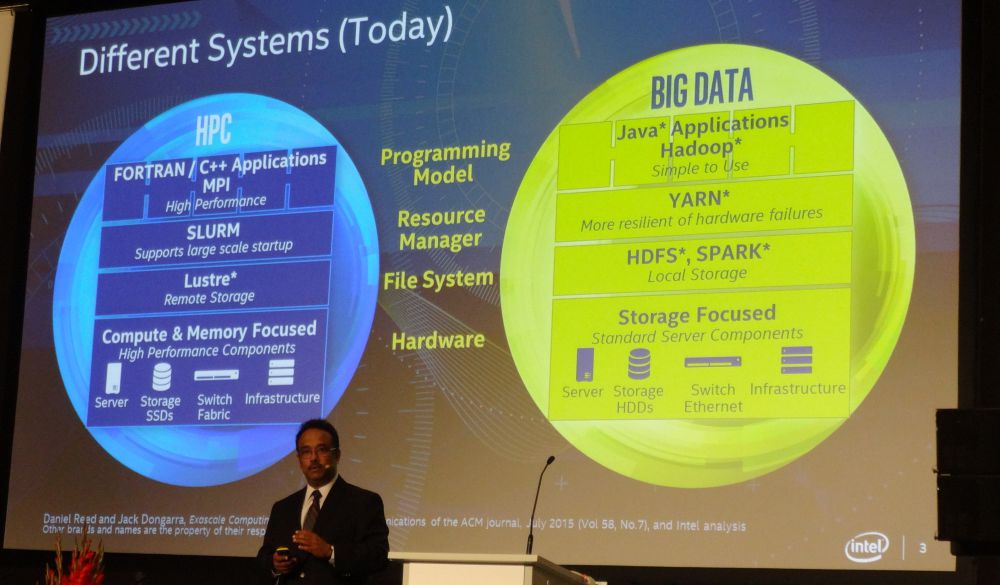
The major challenge, which Hazra says will be the focus of continued investment at Intel, is bringing together a single platform for both HPC and big data—a “design surface” to handle both application areas. The problem, which he says has plagued any company that tried to push out a technologically sound project but failed, is that if there is no ecosystem, no way to support the programming and tooling environment, the chances for success are nil.
Since there is little chance that this framework can be based on forcing “big data” developers to learn MPI or for HPC centers to look to Yarn as their resource management framework, the bottleneck is in the software glue. While he says that frameworks like Mesos and other approaches that pull in the all-important resource management layer that allows the kind of interoperability Intel envisions are attractive approaches, the development at Intel will continue to rest on this middle layer, even if it has yet to be named.
When asked specifically if Mesos is the right proposal for gluing together this single system architecture from a resource management view (with a swell of voices from the audience at this), Hazra said, “At this level of the architecture, there are some things that are conglomerated. For instance, the cloud is relevant here—do you have the ability to do resource management nested under a broad datacenter orchestrator or is it the other way around where there are multiple orchestrators? That is an architectural decision—you have to look at all the mechanisms, from containerization to how to expose those services. Mesos is just one of those frameworks for doing so.”In other words, there are options. There are multiple ways of looking at what the role of the (all important, if you’re trying to create something of this nature) resource management layer might be based on the workload (and even deployment model) users are after. But eventually, that common orchestrator will need to emerge. Whether its Mesos or not, it has to also conform to both cultures–HPC and big data (and Mesos/MPI are not exactly the best of bunkmates yet, for example). And therein lies the challenge.
“It’s about the ability to have a persistent, scalable, interoperable platform—that’s been the model of the x86 platform over the past couple of decades,” Hazra says.“Does it really have to be HPC or big data—these two choices? Can it be a more converged future? It’s both,” he argued. “It’s about the inevitability of HPC becoming part of the delivery of the full promise of big data.”
“This isn’t just an intellectual pursuit, it’s an economic imperative. And depending on where you sit in the [HPC or big data] debate, it’s important. If you sit on the big data side, you are increasingly challenged by inefficiency—you’re trying to recreate many things that have been done already in HPC. And if you’re sitting on the HPC side and you don’t look at the future of converged infrastructure and this new surface layer of HPC, you’re headed toward being a dinosaur. The meteor is one hit, but over time, you just won’t play in this market.”
The one thing that is clear from looking at the slides above is that there are no common tools between the two. We will present another slide below that better articulates how these come together, but first, take a look at the application drivers below. With such variation in workloads between data analytics and HPC, how might a framework shape up that can accommodate both and where do the tuning knobs that lend the right level of configurability sit? .

The defining principle of the single system architecture is not necessarily about the blending between HPC and big data, Hazra notes. It’s about being able to have the flexibility and configurability to design a system approach based on solution urgency. This concept of solution urgency drives both HPC and big data in different ways, he explains, from the needs of real-time or near real-time analytics in the enterprise world to being able to do some analysis from simulation at a more relaxed pace but with the required system elements to scale across thousands of nodes if needed. Further, he says, that a single system architecture means that the goal is to remove the need for separate systems and data transfer for different parts of the workflow (i.e. from simulation to visualization and back again). This is enabled by a new portrait of the stack hierarchy, which has wicked down the hierarchy to fewer, but more configurable layers.
As shown in the slide below, the current situation with the compute cache hierarchy has increased over time as there has been more latency to hide and more Moore’s Law to provide caches. Beyond that, what’s in the processor is suddenly no longer memory, it’s now storage as well. The file system has its own hierarchy as well, but what has happened is “we have pushed the technology we’ve had to give us a few more levels in the hierarchy all the time.” But now, as seen on the proposed single system architecture hierarchy view, there are new ways to add lateral layers to the hierarchy—to condense it down to a small set of levels that can then be adapted based on workload types.

The concept of the single system architecture is different than the company’s scalable system framework, which they have been building support for around the needs of large-scale HPC clusters (as in the case of the forthcoming Aurora supercomputer). Rather, the scalable framework is one element that is part of the HPC focused stack that can be configurable and extended outwards to meet the needs of large-scale analytics applications running on HPC hardware. Of course, where one draws the line between what makes a system HPC or “big data” gets confused in such a case (i.e. a data analytics application running on a Xeon-Xeon Phi system connected with Infiniband rather blurs the lines), but that, Hazra says, is the point. It confuses the distinctions between what makes a system one thing or another—and that should be the goal from a frameworks perspective going forward.
What might sound familiar about this proposed set of architectural features from the high level is that it does not sound much different than the data-centric worldview proposed by IBM. Considering that one of the key people behind the push to create a common palette for both big data and HPC workloads seamlessly working together on the same boxes, former IBM BlueGene architect and current Intel fellow, Alan Gara (interview here), it is hard to be surprised. But what is driving these movements at both Big Blue and Intel is a consistent drive of demand—for HPC systems to be better equipped to deal with large-scale data analysis and for data analysis to capture the same performance benefits that are the key force in HPC.
In presenting to a crowd of supercomputing folks, many of whom work at government-funded HPC sites, Hazra was careful to point out the elephant in the room. “There are big ramifications for how governments are investing in technology,” he explained, pointing to a debate in the United States about how exascale systems will be used—for big data or high performance computing. “It’s both, and the imperative is a political and funding question when it comes to new investments.” It is also key to how Intel will extend its systems approach (but not systems business, as we once hypothetically outlined) to meet as many server customers as possible via their partners without isolating their own investments in silos as separate as technical computing.




Be the first to comment