

While supercomputing centers and hyperscalers would agree about many things when it comes to systems architecture and the need to use certain technologies to goose the performance and the scale of their applications, they often have a fundamental disagreement when it comes to networking. It is hard to predict if this might change, but as hyperscalers push the performance up and pricing down on Ethernet, big HPC centers could end up adopting Ethernet for more systems.
They could also continue to embrace technologies such as Cray’s “Aries” XC dragonfly interconnect, which was announced nearly three years ago and which offers many advantages over fat tree, torus, and hypercube topologies based on InfiniBand or other proprietary protocols. As the recent Top 500 supercomputer rankings show, Cray is on the rise in terms of system count and is being very aggressive about competing against InfiniBand and Ethernet in the HPC centers of the world. The company also has set its sights on expanding outside of HPC to enterprises, and is getting traction here. SGI also has a slice of the market with its NUMALink interconnect, which is used for tightly coupling server nodes together to create a shared memory system that is easier to program than a cluster.
There is also a battle brewing between Mellanox Technologies, which has 100 Gb/sec InfiniBand already in the field with its Switch-IB products and is getting 100 Gb/sec Ethernet out the door later this year with its Spectrum products, announced last month, and Intel, which is gearing up to launch its Omni-Path networking, which combines some attributes of the Cray Aries interconnect (which Intel bought for $140 million back in April 2012) and its True Scale InfiniBand (which it got from its $125 million acquisition of the QLogic InfiniBand switch and adapter business in January 2012) to create yet another option. Over the past several months, Intel has been divulging some of the feeds and speeds of Omni-Path switches and adapters, and it provided a few more tidbits about them at the International Supercomputing conference in Frankfurt last week.
To our eye, the competition at the high-end of the HPC market is getting more intense with regards to interconnects, not less so, and Ethernet will have to work that much harder to make inroads. But, it will also come down to scale and price, and if 100 Gb/sec Ethernet costs a lot less and has close to the same performance as InfiniBand, Omni-Path, and Aries as well as a way of running applications that have been tuned for InfiniBand or Aries, then we could see Ethernet rebound in HPC centers.
That has not been the case in the past several years, as a survey of the interconnect choices in the Top 500 supercomputer rankings shows:
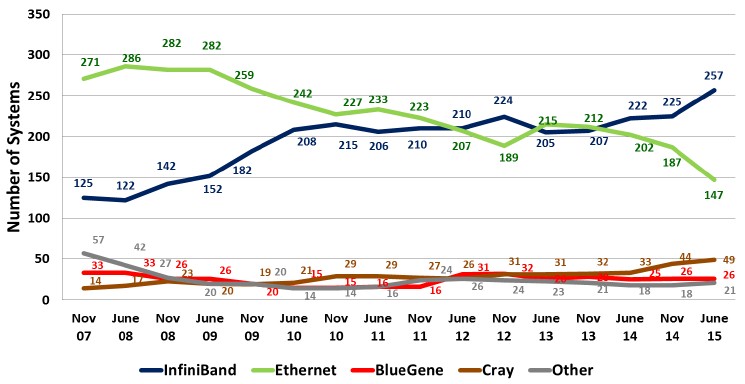
As you can see, InfiniBand has been on the rise over the past eight years and now accounts for more than half of the systems on the list – a place that Ethernet held at the beginning of the term set in this chart. Cray’s proprietary “Gemini” XT and Aries XC interconnects have also been on the rise as the company has pushed hard to demonstrate the benefits its systems have running real workloads, not just the LINPACK Fortran matrix math test that is used to rank the Top 500 supers in the world twice a year. IBM’s BlueGene machines, which are based on a proprietary 3D torus interconnect, are still hanging in there on the list and will remain so until they are decommissioned a few years from now.
There is a kind of fractal nature to the Top 500 list that just came out at ISC 2015, which shows the same pattern of distribution, more or less, between InfiniBand, BlueGene, Cray, and other interconnects with one exception. As you expand out from the top of the list to the bottom, increasing the number of machines in the data pool by a hundred machines, Ethernet’s portion of the system count grows and everything else except InfiniBand grows more slowly. It is an interesting pattern:
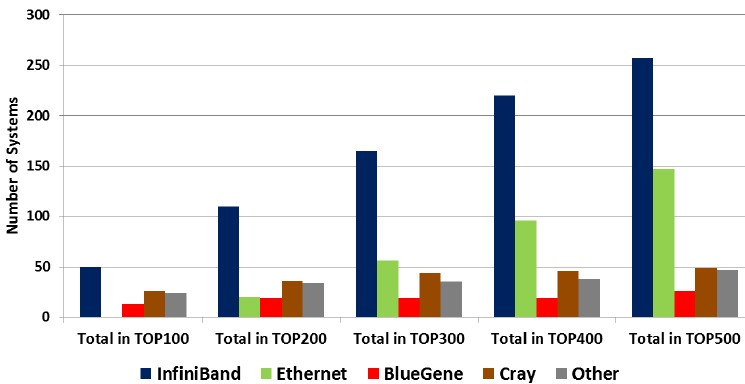
This pattern makes perfect sense once you understand the machines and the work they are doing. The HPC centers with the biggest clusters seek out switching infrastructure that provides the highest bandwidth and lowest latency because they want to efficiently scale their applications and thereby push as much work as possible through their machines. Supercomputer customers in particular – who buy so-called capability class machines, where performance and scale are used to run very large and relatively few workloads – are used to having exotic interconnects on their machines that are not based on the Ethernet protocols that have dominated the enterprise datacenter for over two decades. (It is hard to remember that IBM’s Systems Network Architecture and Token Ring protocol used to be better, technically speaking, than the Ethernet of the time, but once the Internet became the network standard in the dot-com boom, SNA and Token Ring were doomed.)
Hyperscalers are concerned about throughput, too, but they are more concerned about economics because they need computing to get less expensive as it scales, not more expensive, or they cannot support hundreds of millions to billions of users in a cost-effective manner. They pick a few server platforms for web, application, and database serving, a storage server or two, and non-blocking Ethernet networks that scale across an entire datacenter with 50,000 or 100,000 nodes. If HPC systems had to scale to this size – and some pre-exascale class machines will have to do this – there would be different trade-offs between latency, scale, and protocols. The biggest hyperscalers, such as Google, Facebook, and Amazon Web Services, have built their own Ethernet switches and software stacks to address their very specific needs. HPC centers can afford to do a lot, but they can’t afford that. (You can see our overview of Google’s switches here, and Facebook’s there. Amazon is a bit more secretive about it.) And hence, collectively they have heavy input into the interconnects that commercial suppliers create.
There is not one InfiniBand or one Ethernet in use among the HPC centers of the world, of course. Several generations of servers and interconnects exist at the same time on the list because no one can get a new cluster every year. Supercomputers and hyperscale clusters tend to have about the same lifespan – about three years, which is significantly shorter than the four to five years that is the average tour of duty for an enterprise cluster.
If you drill down into the most recent Top 500 list with regard to interconnects, you can see the interconnect distribution by system count and by aggregate performance. The first chart above showing trends since 2007 was made by Mellanox for its presentations and it is for some reason missing two of the InfiniBand systems. And we might argue that the two generations of the TH Express interconnect look a lot more like InfiniBand than anything else, and also point out that while Intel is being very careful to not brand Omni-Path as a flavor of InfiniBand, there are similar arguments that will no doubt be made that Omni-Path should be considered InfiniBand. (We will see what Intel thinks when it launches Omni-Path later this year, and also see what the InfiniBand Trade Association thinks, too.) In any event, here is how the networking breaks based on system count, total performance, and total cores for the June 2015 Top 500 list:
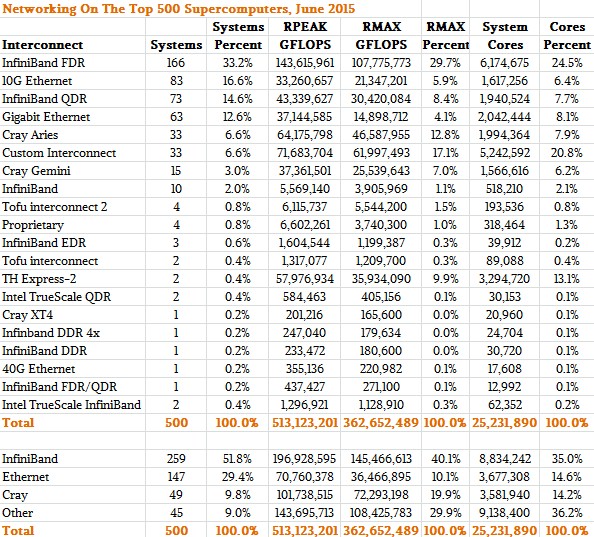
There are a couple of interesting things to note in that table. First, there are three machines on the list that are already using the 100 Gb/sec EDR InfiniBand that was launched by Mellanox last fall. The 56 Gb/sec FDR InfiniBand speed is the most popular, but 40 Gb/sec QDR rates (from both Mellanox and Intel) are on the list, too. While Gigabit Ethernet is still on 12.6 percent of the systems, 10 Gb/sec Ethernet is on 16.6 percent of the machines; there is one cluster using 40 Gb/sec Ethernet, and we think it will not be too long before there are systems using 100 Gb/sec switches and 25 Gb/sec or even 50 Gb/sec server uplinks if the price is right thanks to the hyperscalers that are pushing this technology.
If you drill down into the raw capacity, as gauged by LINPACK, and the total core count for InfiniBand as a group, InfiniBand’s share across those categories drops, which means something we all know from looking at the list as a whole: On average, the Ethernet machines tend to be near the bottom, where the budgets are smaller or the bandwidth and latency demands are smaller. The average InfiniBand system on the list has 34,109 cores, while the average Ethernet machine has 25,016 cores. The average Cray system using its Gemini or Aries interconnect has nearly three times the cores, at 73,101 cores, and has five times the sustained performance of the average Ethernet cluster. And the average machine using other, proprietary interconnects has nearly twice as much oomph and three times the core count. But again, we think that the Tianhe-1A and Tianhe-2 machines on the list can probably be considered quasi-InfiniBand machines and that would skew the numbers a bit. That said, there are still some very large and powerful BlueGene machines that boost the core count and aggregate floating point performance for the Other category of interconnects.
One of the fun aspects of the list is to look at the relative efficiency of the systems running the LINPACK test, and InfiniBand, BlueGene torus, and K Tofu interconnects always do well on this efficiency ranking, which ranks the LINPACK performance against its peak theoretical performance. Here is a scatter graph that shows the relative efficiency of each machine, by interconnect, running the LINPACK test:
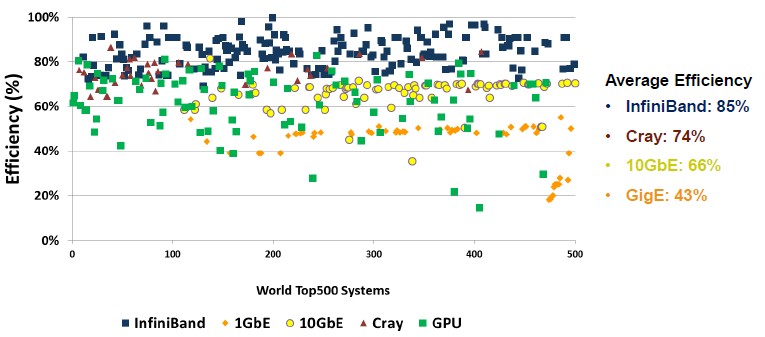
We realize that there is a world of difference between how a system runs LINPACK and how it runs on real-world workloads. And, in fact, if you look at other benchmark tests like HPCG, which is being positioned as a follow-on to LINPACK, the efficiency is just awful. We spend a lot of time talking about how to scale up the hardware within a certain power and thermal envelope, but the real issue in HPC is that it is much more difficult to scale up the application software. The point is that customers have to look at the complete system and the efficiency at which the interconnect can allow MPI, PGAS, and other parallel programming models to run is an important factor and will be increasingly so as system architects try to get more performance out of CPUs and storage.
According to a survey just conducted by HPC industry watchers Intersect360 Research, bandwidth and latency are still the big issues, as you might expect. But that does not in any way negate other factors in choosing an interconnect for an HPC cluster:
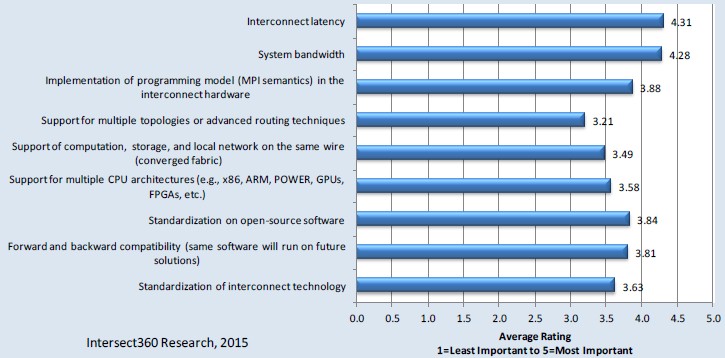
“The results of this study highlight the enduring, paramount importance of performance – the P in HPC,” explain Addison Snell and Laura Segervall, authors of the report. “Whereas enterprise IT applications may be predominantly driven by reliability and standards, the nature of HPC applications is to strive to new pinnacles of discovery, insight, or achievement. Scientific and engineering problems can be run at higher fidelity, with increased realism, with more degrees of freedom in the model. You don’t need to build the same bridge twice; you go build a harder bridge.”
You can get a copy of the report, High Performance Interconnects: “Performance” Is Still HPC’s Middle Name, at this link.

The Highly Profitable Chip Making Monopoly Called TSMC
When Taiwan Semiconductor Manufacturing speaks, the datacenter sector of the IT industry listens because, with few exceptions, this foundry etches the compute, networking, and storage engines that power the datacenter. And the rest of the entire IT industry also listens, particularly the smartphone industry and a good portion of the …

Gutting Decades Of Architecture To Build A New Kind Of Processor
There are some features in any architecture that are essential, foundational, and non-negotiable. Right up to the moment that some clever architect shows us that this is not so. What is true of buildings and bridges is equally true of systems and their processors, which is why we use the …

The Cheapest Compute In The Intel Xeon Lineup
While the minimalist server processor — and the microserver concept that was based upon it — did not take over the datacenters of the world, there are still some workloads that can fit in modestly powered single-socket CPUs just fine. That is why Intel has always created server variants of …
Timothy, I am not sure the Top500 list is really the right place to look considering that there is no requirement to actually be an HPC installation to apply and that for many installations in the Ethernet area also the results are simply extrapolated. So you have Virtualization clusters, Webserver farms, Cloud systems … anything that has many servers and is connected sharing the list with the systems that are actually used for HPC applications. There are only very few 1GB Ethernet based HPC systems large enough for Top500 – e.g. from Financial Market with rather task oriented grid-like operations.