

When it comes to high performance computing, IBM is in a phase change that will take it several years to complete with its key OpenPower infrastructure partners, Nvidia and Mellanox Technologies. As it turns out, the desire to build exascale systems is forcing all supercomputer architects to move away from clusters built from generic processors towards more parallel and specialized compute, coupled together with faster and wider interconnects. IBM is gearing up its Power8+ processors, due next year, as another important step on the OpenPower roadmap and, as it turns out, is already doing deals that feature machines based on that future chip.
There are a lot of changes on the horizon for processors and systems design, many of which were discussed in detail at the ISC 2015 supercomputing conference this week and which we will be going through in a careful and considered fashion here at The Next Platform in the coming days.
IBM did not have any new supercomputers to show off at ISC 2015 this week, but as our coverage of the Top 500 rankings shows, the massively parallel architecture of the BlueGene systems, which have their roots in quantum chromodynamics research at Columbia University many years ago and which were commercialized formally by IBM starting in 1999 through a $1 billion grand challenge investment, still have a major presence on the list.
There are many of us that wish IBM had continued to push the Power-based systems, including embedded PowerPC processors with perhaps dozens of cores, creating something akin to Intel’s 72-core “Knights Landing” Xeon Phi due later this year. Such a parallel Power chip could have been hooked into an extended 3D torus interconnect (perhaps with a few more dimensions and some bandwidth and latency improvements, or BlueGene/Q systems could have been enhanced with an R or S variant with a dragonfly-style interconnect, perhaps based on that 1.1 Tb/sec hub/switch that IBM made for its implementation of the “Blue Waters” system at the National Center for Supercomputing Applications, which was not sold to NCSA and which was not, for the most part, commercialized because the Power 775 system was too expensive for IBM to build.
In this alternate universe, that IBM interconnect would be something like the “Aries” interconnect developed by Cray for its XC30 and XC40 systems, and IBM would have pitted Power8, Power9, and Power10 against Intel Xeons of the “Haswell,” “Broadwell,” “Skylake,” and “Cannonlake” generations. (Yes, Intel launches new processors much more frequently, at least for now.) And souped-up PowerPC A series parallel processors would have been pitched against the Knights Landing and Knights Hill chips from Intel, too, in this alternate universe.
The rise of GPU accelerators from Nvidia coincided with IBM’s problems with the Power7-based Blue Waters architecture and concern over the future of the BlueGene, and given IBM’s experience from building the petaflops-busting “Roadrunner” hybrid CPU-GPU for Los Alamos National Laboratory, which was decommissioned two years ago and which was not known for being easy to program because it was the first machine of its kind, it is not hard to understand why Big Blue found it appealing to shift to Tesla GPU accelerators, with their CUDA programming environment, as a parallel and throughput computing adjunct for future Power-based systems. IBM is also keen on creating a single, unified platform for the HPC market, rather than three distinct systems, and more importantly, want to be able to directly and easily leverage this HPC technology for enterprise, cloud, and possibly even hyperscale customers like Google, which is a key founder of the OpenPower foundation, which is designing and making its own Power8 systems, and which has said unequivocally that it would shift its infrastructure from X86 to Power if it felt it could get enough of an advantage. (Google is testing that idea out now.)
One Power Platform To Rule Them All
IBM now has something it has never had in the history of the Power platform, which dates from 1990 when the original RS/6000 Unix systems were launched, and that is a single, consistent roadmap and product set that it can apply across the HPC, hyperscale, enterprise, and cloud pillars. It also has partners who are doing some of the development on GPU acceleration and networking for very good enlightened self-interest reasons. And, more importantly, IBM has an architecture that emphasizes what many modern workloads crave most, explains Dave Turek, vice president of technical computing and OpenPower, and that is a system that provides integer performance and memory bandwidth (funny that first bit, but it is true) and floating point performance that can be radically increased when the workload calls for it.
As for GPUs, Turek says that there is not only a tension between what to put in the CPU and what to leave for the GPU (and perhaps other accelerators such as FPGAs), but also between those whose applications are ready for GPU acceleration and those who are not. “There is a tension, because if I am not using GPUs, I don’t necessarily want to pay for them,” as Turek puts it. To that end, we have been thinking that for perhaps Power9 or maybe better still for Power10, GPU acceleration will become so normal that IBM won’t have to put vector math units on Power chips at all; it will just offload this work to GPUs, freeing up die space for more Power cores and other kinds of accelerators and cache.
With all of the talk about the “Summit” and “Sierra” supercomputers that IBM, Nvidia, and Mellanox are teaming up to build for Oak Ridge National Laboratory and Lawrence Livermore National Laboratory, respectively, in the late 2017 timeframe, people might be under the mistaken impression that the OpenPower partners are not delivering machines this year or next. But that is not true. You don’t have to wait until Power9 in late 2017 to get on the OpenPower roadmap. In fact, IBM is getting ready to ship the “Firestone” Power8-Tesla K80 system that it resells from original design manufacturer Wistron, which we told you about in March from the OpenPower Summit. (We are trying to get some more details on this machine from ISC 2015.) This machine is on the first spot on the OpenPower roadmap that was unveiled by Sumit Gupta at ISC this week. Gupta used to run the Tesla accelerated computing unit at Nvidia and is now its new vice president of OpenPower high performance computing, working alongside Turek to push IBM’s HPC and data analytics agenda on Power and hybrid architectures. Here is what the official OpenPower HPC roadmap looks like:
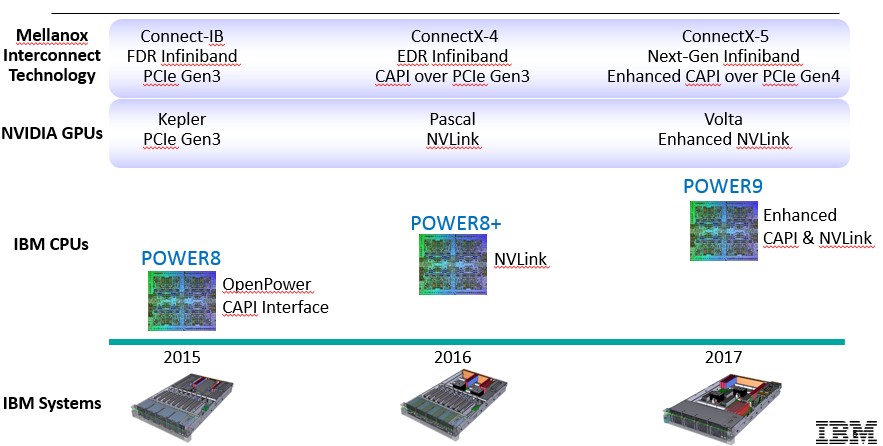
We, of course, caught wind of this roadmap back at the Rice Oil and Gas Conference in Houston and told you all about it back in March. And it confirms many of the details to a broader audience of customers who might want a slice of Summit and Sierra for their own simulations, models, and analytics jobs. For one thing, it names the processors coming from IBM as Power8+ and Power9, the first time IBM has pinned the names to them in the OpenPower roadmap. Although as we showed you last week, when IBM Research divulged that it had made test transistors using 7 nanometer processes and therefore had extended the Power roadmap to perhaps 2023 or 2026 at least from a chip making perspective if the process can be commercialized by foundry partner Globalfoundries, the IBM roadmaps being shown to business partners have been mentioning very vague details about the Power9 chip and not really discussing Power8+ at all. Now we know there is a Power8+ chip coming next year and a Power9 chip in 2017. The latter was expected given the Oak Ridge deal.
All IBM has said about the 2017 generation of systems that implement this OpenPower roadmap is that the systems will have multiple Power9 processors and multiple “Volta” generation Tesla GPU accelerators from Nvidia. If you look carefully at the system images below, it looks like IBM has two Power9 processors in the 2017 machine, and it is very hard to reckon where the GPU accelerators are. (The images may not be faithful to the designs they represent, but the Firestone machine from 2015 looks about right.) The important point is that IBM is ready to do hybrid machines now and will be able to do slightly more dense ones later when the Firestone machines ship. The other important thing is that the Power8+ chip will sport NVLink high-speed links between the Power8+ processor and the “Pascal” family of Tesla GPU coprocessors.
“We have a significant pipeline of deals next year that we are bidding on with Power8+ and NVLink right now,” Turek tells The Next Platform. “These are big systems, and small systems. Small meaning a couple of million dollars here, a couple of million dollars there, and big being on the order of $30 million.”
In the meantime, IBM and its OpenPower partners are focusing on understanding the compute, storage, and networking demands of future HPC and data analytics workloads, and it is also helping customers begin the work of porting their Power7/Power7+ or BlueGene applications to the systems using Power8 and beyond processors with GPU and FPGA acceleration. IBM opened an OpenPower Design Center in Montpelier, France in June and two centers for excellence have been established at Oak Ridge and Lawrence Livermore to help with the application porting work on the hybrid Power-Tesla machines.
Gupta tells The Next Platform that over 1,500 applications have been ported to Linux running atop Power, and these are real applications that IBM is counting, not the thousands of applets that come in a normal Linux distribution. (For reference, a typical AIX, Solaris, or HP-UX release had somewhere between 3,000 and 4,000 applications.)
Perhaps as important as the applications to the future of the Power and hybrid Power-GPU architectures is the fact that IBM is starting to demonstrate the performance gains that can be had by using a Power8 chip instead of an Intel Xeon chip. Here are the comparisons that IBM is making publicly at the ISC 2015 conference this week:
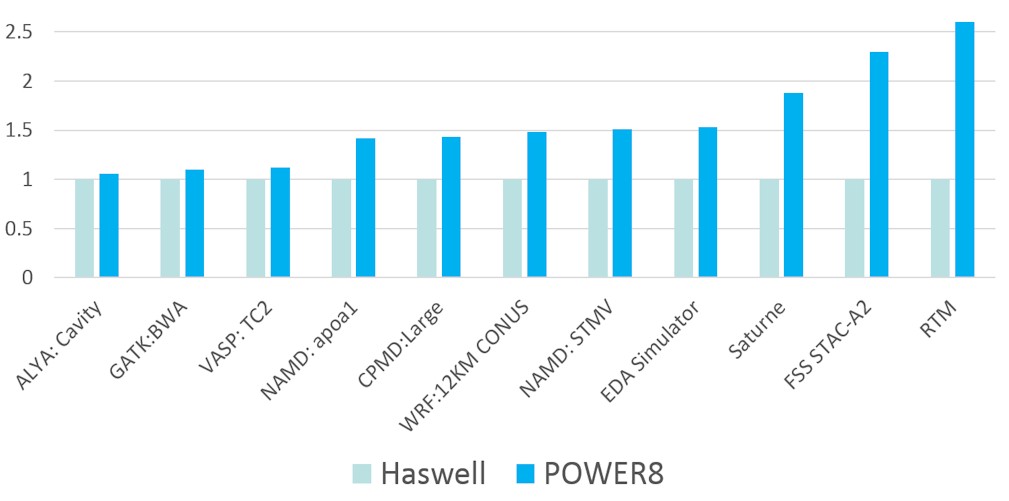
In the chart above, most of the tests for Power8 systems were done on machines equipped with a twelve-core Power8 chip running at 3.02 GHz compared to an Intel “Haswell” Xeon E5-2690 v3 or E5-2697 v3 processor, which respectively have 12 cores or 14 cores running at 2.6 GHz. The STAC A2 financial services benchmarks were done on a server with two Xeon E5-2699 v3 processors, which have 18 cores and run at 2.3 GHz, compared to a system with a pair of Power8 processors with twelve cores running at 3.52 GHz. Not everybody is familiar with the benchmarks above, but Alya is for computation biomechanics; GATK is from bioinformatics; VASP and CPMD is for computational chemistry; NAMD is for computational molecular dynamics; WRF is for weather simulation; Saturne is from computational fluid dynamics; STAC A2 is a financial services benchmark; and RTM is a reverse time migration seismic simulation from the from oil and gas industry.
As you can see, some applications show a nominal speedup, and others show big jumps. This is but a sampling of the performance data that IBM has amassed to make the case for Power8 against Xeon processors. There are other generic CPU tests and enterprise workloads that IBM has tested as well, not just HPC performance. And Intel has similar benchmarks that show it making a case against Power8 processors and platforms, too. In the coming weeks, we will be analyzing these two different architectures and trying to rationalize the differences between the camps over the past several years and what we expect in the coming years. This is not something that can be summed up in one simple, single article – that is for sure. And it will change as the processors, their accelerators, their systems, and the applications themselves change over time.




Be the first to comment